 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models: An Applied Econometric Framework
Dec 09, 2024



Large language models (LLMs) are being used in economics research to form predictions, label text, simulate human responses, generate hypotheses, and even produce data for times and places where such data don't exist. While these uses are creative, are they valid? When can we abstract away from the inner workings of an LLM and simply rely on their outputs? We develop an econometric framework to answer this question. Our framework distinguishes between two types of empirical tasks. Using LLM outputs for prediction problems (including hypothesis generation) is valid under one condition: no "leakage" between the LLM's training dataset and the researcher's sample. Using LLM outputs for estimation problems to automate the measurement of some economic concept (expressed by some text or from human subjects) requires an additional assumption: LLM outputs must be as good as the gold standard measurements they replace. Otherwise estimates can be biased, even if LLM outputs are highly accurate but not perfectly so. We document the extent to which these conditions are violated and the implications for research findings in illustrative applications to finance and political economy. We also provide guidance to empirical researchers. The only way to ensure no training leakage is to use open-source LLMs with documented training data and published weights. The only way to deal with LLM measurement error is to collect validation data and model the error structure. A corollary is that if such conditions can't be met for a candidate LLM application, our strong advice is: don't.
Discrimination in the Age of Algorithms
Feb 11, 2019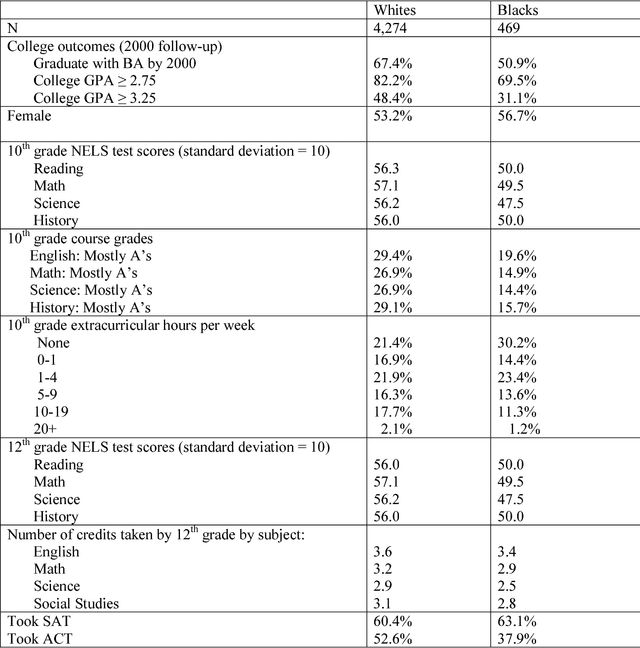

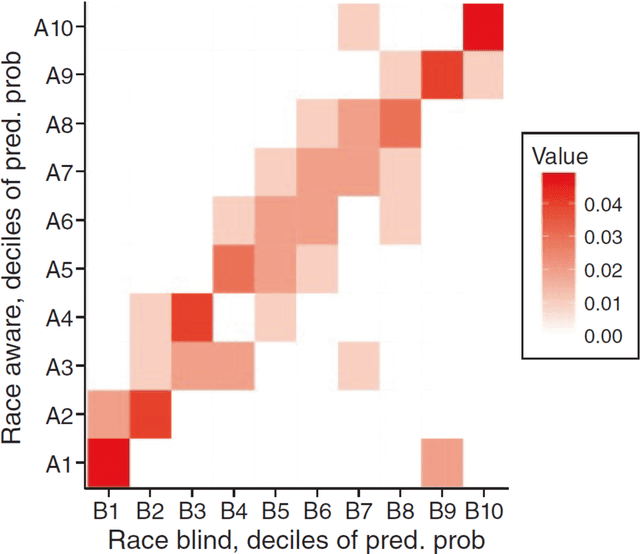
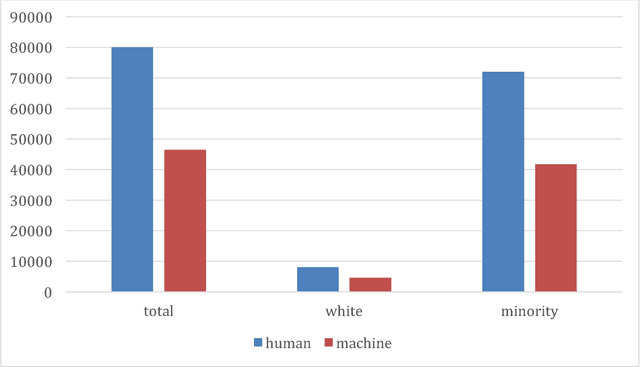
The law forbids discrimination. But the ambiguity of human decision-making often makes it extraordinarily hard for the legal system to know whether anyone has actually discriminated. To understand how algorithms affect discrimination, we must therefore also understand how they affect the problem of detecting discrimination. By one measure, algorithms are fundamentally opaque, not just cognitively but even mathematically. Yet for the task of proving discrimination, processes involving algorithms can provide crucial forms of transparency that are otherwise unavailable. These benefits do not happen automatically. But with appropriate requirements in place, the use of algorithms will make it possible to more easily examine and interrogate the entire decision process, thereby making it far easier to know whether discrimination has occurred. By forcing a new level of specificity, the use of algorithms also highlights, and makes transparent, central tradeoffs among competing values. Algorithms are not only a threat to be regulated; with the right safeguards in place, they have the potential to be a positive force for equity.
Machine Learning Tests for Effects on Multiple Outcomes
Jul 05, 2017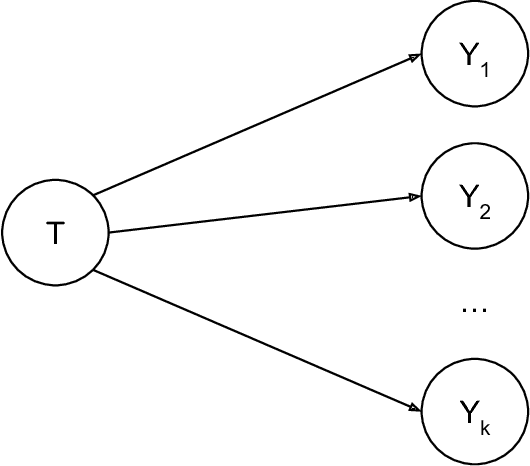
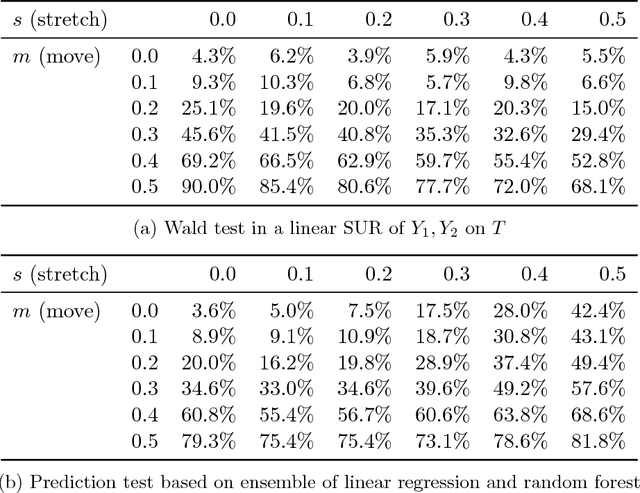
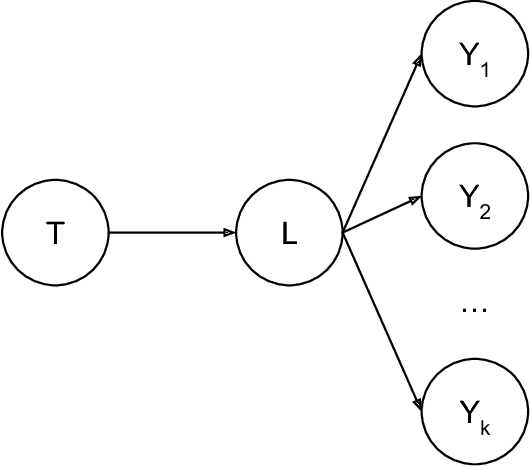
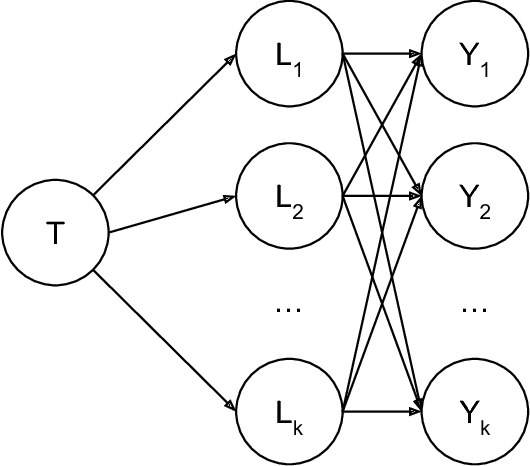
A core challenge in the analysis of experimental data is that the impact of some intervention is often not entirely captured by a single, well-defined outcome. Instead there may be a large number of outcome variables that are potentially affected and of interest. In this paper, we propose a data-driven approach rooted in machine learning to the problem of testing effects on such groups of outcome variables. It is based on two simple observations. First, the 'false-positive' problem that a group of outcomes is similar to the concern of 'over-fitting,' which has been the focus of a large literature in statistics and computer science. We can thus leverage sample-splitting methods from the machine-learning playbook that are designed to control over-fitting to ensure that statistical models express generalizable insights about treatment effects. The second simple observation is that the question whether treatment affects a group of variables is equivalent to the question whether treatment is predictable from these variables better than some trivial benchmark (provided treatment is assigned randomly). This formulation allows us to leverage data-driven predictors from the machine-learning literature to flexibly mine for effects, rather than rely on more rigid approaches like multiple-testing corrections and pre-analysis plans. We formulate a specific methodology and present three kinds of results: first, our test is exactly sized for the null hypothesis of no effect; second, a specific version is asymptotically equivalent to a benchmark joint Wald test in a linear regression; and third, this methodology can guide inference on where an intervention has effects. Finally, we argue that our approach can naturally deal with typical features of real-world experiments, and be adapted to baseline balance checks.