 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Tests for Effects on Multiple Outcomes
Paper and Code
Jul 05, 2017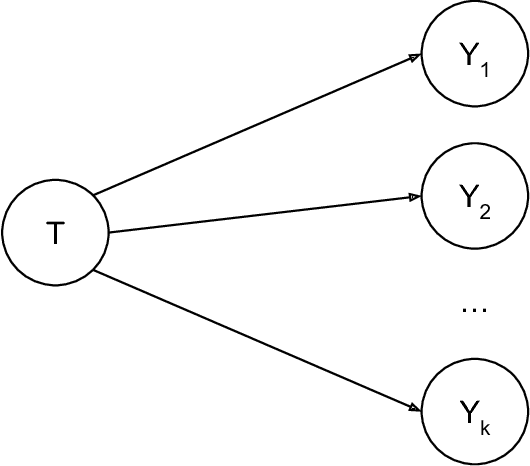
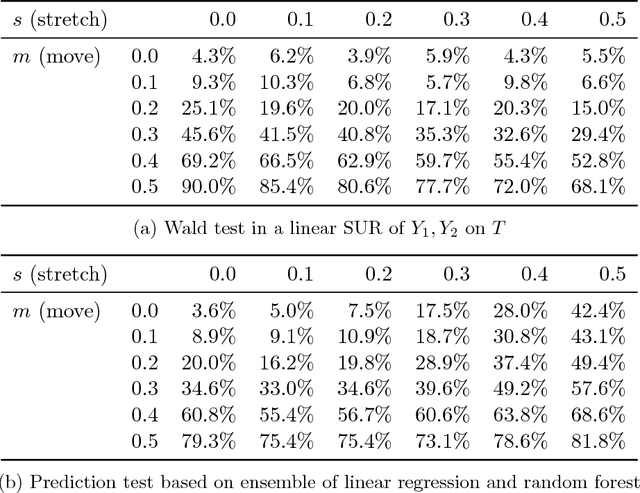
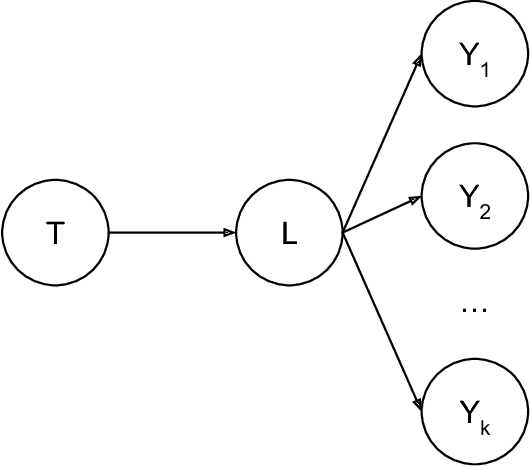
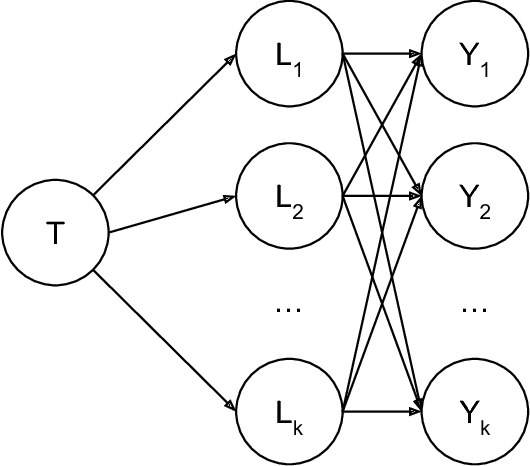
A core challenge in the analysis of experimental data is that the impact of some intervention is often not entirely captured by a single, well-defined outcome. Instead there may be a large number of outcome variables that are potentially affected and of interest. In this paper, we propose a data-driven approach rooted in machine learning to the problem of testing effects on such groups of outcome variables. It is based on two simple observations. First, the 'false-positive' problem that a group of outcomes is similar to the concern of 'over-fitting,' which has been the focus of a large literature in statistics and computer science. We can thus leverage sample-splitting methods from the machine-learning playbook that are designed to control over-fitting to ensure that statistical models express generalizable insights about treatment effects. The second simple observation is that the question whether treatment affects a group of variables is equivalent to the question whether treatment is predictable from these variables better than some trivial benchmark (provided treatment is assigned randomly). This formulation allows us to leverage data-driven predictors from the machine-learning literature to flexibly mine for effects, rather than rely on more rigid approaches like multiple-testing corrections and pre-analysis plans. We formulate a specific methodology and present three kinds of results: first, our test is exactly sized for the null hypothesis of no effect; second, a specific version is asymptotically equivalent to a benchmark joint Wald test in a linear regression; and third, this methodology can guide inference on where an intervention has effects. Finally, we argue that our approach can naturally deal with typical features of real-world experiments, and be adapted to baseline balance checks.