 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Feature Highlighting for Human-AI Decision-Making
Apr 24, 2026Human decision-makers often face choices about complex cases with many potentially relevant features, but limited bandwidth to inspect and integrate all available information. In such settings, we study algorithms that highlight a small subset of case-specific features for human consideration, rather than producing a single prediction or recommendation. We model highlighting as a constrained information policy that selects a small number of features to reveal. A central issue is how humans interpret the algorithm's choice of features: a sophisticated agent correctly conditions on the selection rule, while a naive agent updates only on revealed feature values and treats the selection event as exogenous. We show that optimizing highlighting for sophisticated agents can be computationally intractable, even in simple discrete and binary settings, whereas optimizing for naive agents is tractable as long as the maximal bandwidth is fixed. We also show that a highlighting policy that is optimal for sophisticated agents can perform arbitrarily poorly when deployed to naive agents, motivating robust, implementable alternatives. We illustrate our framework in a calibrated empirical exercise based on the American Housing Survey. Overall, our results establish the value of highlighting a context-specific set of features rather than a fixed one as a practically appealing and computationally feasible tool for achieving human-algorithm complementarity.
Causal Effect Estimation with Latent Textual Treatments
Feb 17, 2026Understanding the causal effects of text on downstream outcomes is a central task in many applications. Estimating such effects requires researchers to run controlled experiments that systematically vary textual features. While large language models (LLMs) hold promise for generating text, producing and evaluating controlled variation requires more careful attention. In this paper, we present an end-to-end pipeline for the generation and causal estimation of latent textual interventions. Our work first performs hypothesis generation and steering via sparse autoencoders (SAEs), followed by robust causal estimation. Our pipeline addresses both computational and statistical challenges in text-as-treatment experiments. We demonstrate that naive estimation of causal effects suffers from significant bias as text inherently conflates treatment and covariate information. We describe the estimation bias induced in this setting and propose a solution based on covariate residualization. Our empirical results show that our pipeline effectively induces variation in target features and mitigates estimation error, providing a robust foundation for causal effect estimation in text-as-treatment settings.
Designing Algorithmic Recommendations to Achieve Human-AI Complementarity
May 02, 2024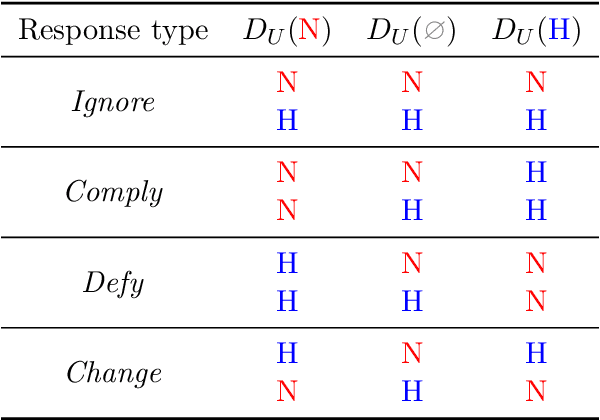
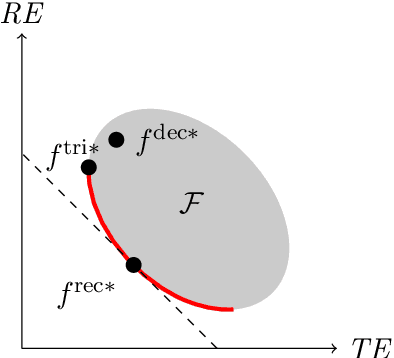
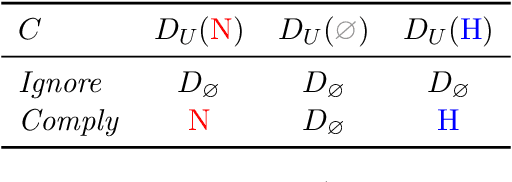
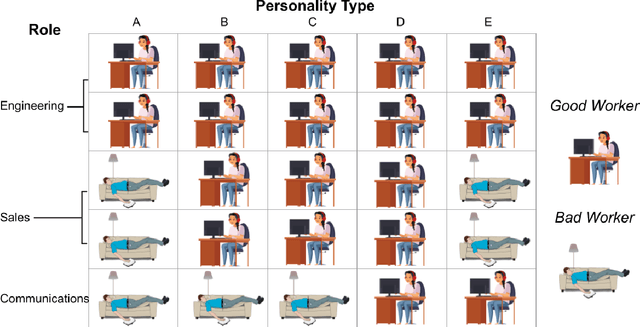
Algorithms frequently assist, rather than replace, human decision-makers. However, the design and analysis of algorithms often focus on predicting outcomes and do not explicitly model their effect on human decisions. This discrepancy between the design and role of algorithmic assistants becomes of particular concern in light of empirical evidence that suggests that algorithmic assistants again and again fail to improve human decisions. In this article, we formalize the design of recommendation algorithms that assist human decision-makers without making restrictive ex-ante assumptions about how recommendations affect decisions. We formulate an algorithmic-design problem that leverages the potential-outcomes framework from causal inference to model the effect of recommendations on a human decision-maker's binary treatment choice. Within this model, we introduce a monotonicity assumption that leads to an intuitive classification of human responses to the algorithm. Under this monotonicity assumption, we can express the human's response to algorithmic recommendations in terms of their compliance with the algorithm and the decision they would take if the algorithm sends no recommendation. We showcase the utility of our framework using an online experiment that simulates a hiring task. We argue that our approach explains the relative performance of different recommendation algorithms in the experiment, and can help design solutions that realize human-AI complementarity.
Personalized Assignment to One of Many Treatment Arms via Regularized and Clustered Joint Assignment Forests
Nov 01, 2023We consider learning personalized assignments to one of many treatment arms from a randomized controlled trial. Standard methods that estimate heterogeneous treatment effects separately for each arm may perform poorly in this case due to excess variance. We instead propose methods that pool information across treatment arms: First, we consider a regularized forest-based assignment algorithm based on greedy recursive partitioning that shrinks effect estimates across arms. Second, we augment our algorithm by a clustering scheme that combines treatment arms with consistently similar outcomes. In a simulation study, we compare the performance of these approaches to predicting arm-wise outcomes separately, and document gains of directly optimizing the treatment assignment with regularization and clustering. In a theoretical model, we illustrate how a high number of treatment arms makes finding the best arm hard, while we can achieve sizable utility gains from personalization by regularized optimization.
Machine Learning Who to Nudge: Causal vs Predictive Targeting in a Field Experiment on Student Financial Aid Renewal
Oct 12, 2023



In many settings, interventions may be more effective for some individuals than others, so that targeting interventions may be beneficial. We analyze the value of targeting in the context of a large-scale field experiment with over 53,000 college students, where the goal was to use "nudges" to encourage students to renew their financial-aid applications before a non-binding deadline. We begin with baseline approaches to targeting. First, we target based on a causal forest that estimates heterogeneous treatment effects and then assigns students to treatment according to those estimated to have the highest treatment effects. Next, we evaluate two alternative targeting policies, one targeting students with low predicted probability of renewing financial aid in the absence of the treatment, the other targeting those with high probability. The predicted baseline outcome is not the ideal criterion for targeting, nor is it a priori clear whether to prioritize low, high, or intermediate predicted probability. Nonetheless, targeting on low baseline outcomes is common in practice, for example because the relationship between individual characteristics and treatment effects is often difficult or impossible to estimate with historical data. We propose hybrid approaches that incorporate the strengths of both predictive approaches (accurate estimation) and causal approaches (correct criterion); we show that targeting intermediate baseline outcomes is most effective, while targeting based on low baseline outcomes is detrimental. In one year of the experiment, nudging all students improved early filing by an average of 6.4 percentage points over a baseline average of 37% filing, and we estimate that targeting half of the students using our preferred policy attains around 75% of this benefit.
Double and Single Descent in Causal Inference with an Application to High-Dimensional Synthetic Control
May 01, 2023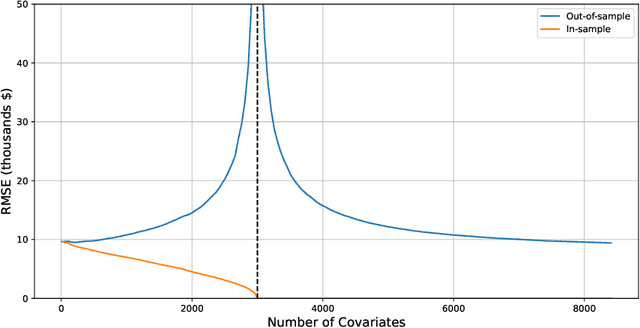
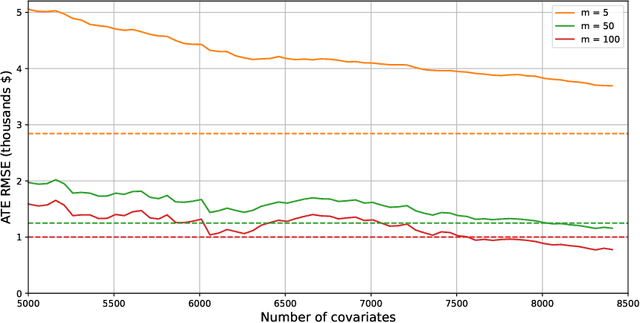
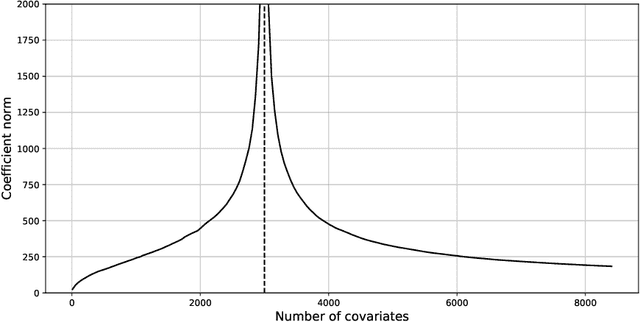
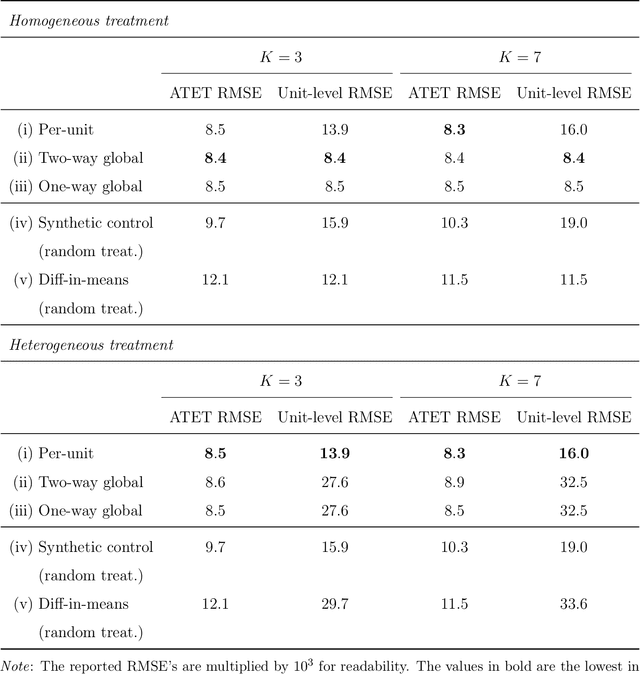
Motivated by a recent literature on the double-descent phenomenon in machine learning, we consider highly over-parametrized models in causal inference, including synthetic control with many control units. In such models, there may be so many free parameters that the model fits the training data perfectly. As a motivating example, we first investigate high-dimensional linear regression for imputing wage data, where we find that models with many more covariates than sample size can outperform simple ones. As our main contribution, we document the performance of high-dimensional synthetic control estimators with many control units. We find that adding control units can help improve imputation performance even beyond the point where the pre-treatment fit is perfect. We then provide a unified theoretical perspective on the performance of these high-dimensional models. Specifically, we show that more complex models can be interpreted as model-averaging estimators over simpler ones, which we link to an improvement in average performance. This perspective yields concrete insights into the use of synthetic control when control units are many relative to the number of pre-treatment periods.
Algorithmic Assistance with Recommendation-Dependent Preferences
Aug 16, 2022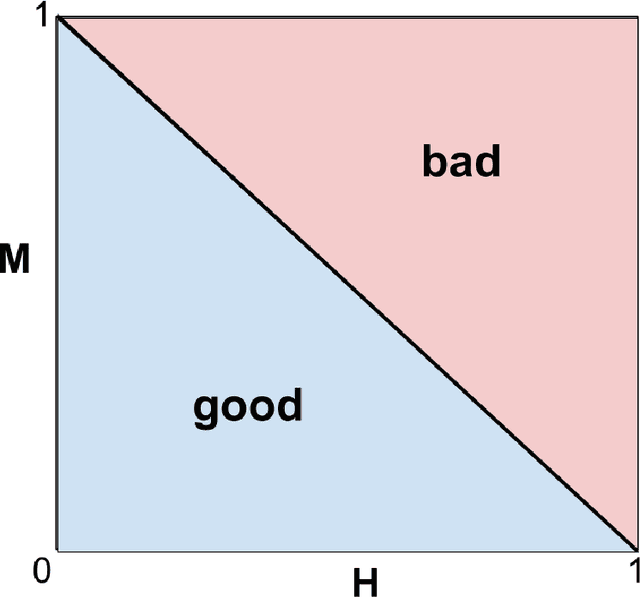
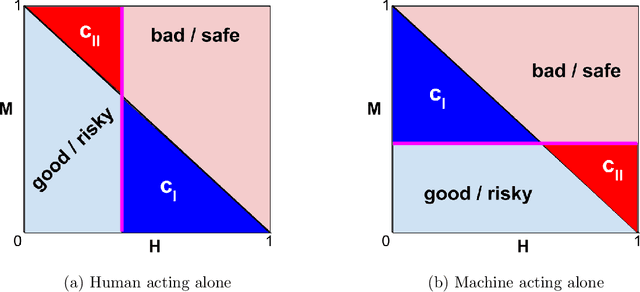
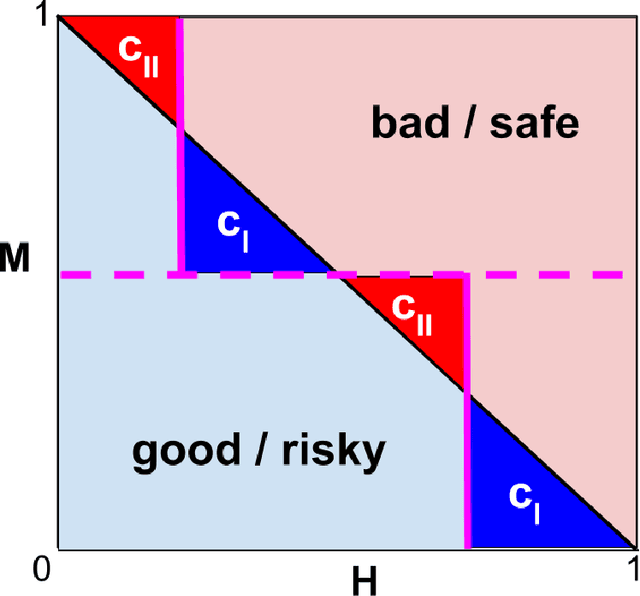
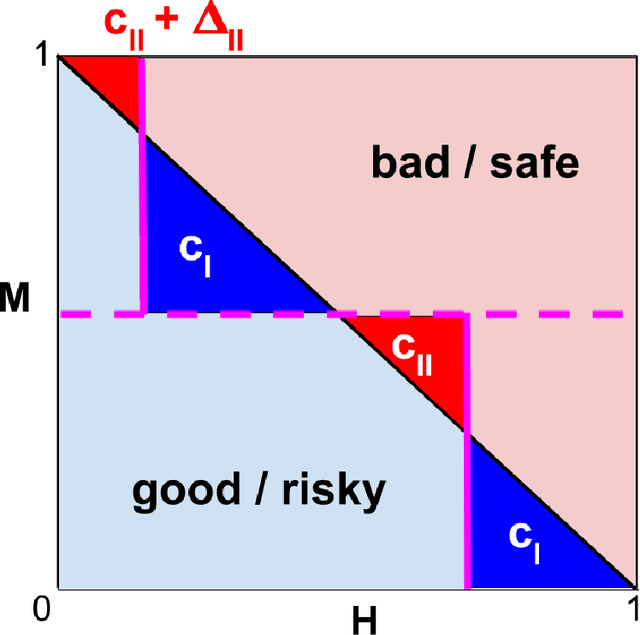
When we use algorithms to produce recommendations, we typically think of these recommendations as providing helpful information, such as when risk assessments are presented to judges or doctors. But when a decision-maker obtains a recommendation, they may not only react to the information. The decision-maker may view the recommendation as a default action, making it costly for them to deviate, for example when a judge is reluctant to overrule a high-risk assessment of a defendant or a doctor fears the consequences of deviating from recommended procedures. In this article, we consider the effect and design of recommendations when they affect choices not just by shifting beliefs, but also by altering preferences. We motivate our model from institutional factors, such as a desire to avoid audits, as well as from well-established models in behavioral science that predict loss aversion relative to a reference point, which here is set by the algorithm. We show that recommendation-dependent preferences create inefficiencies where the decision-maker is overly responsive to the recommendation, which changes the optimal design of the algorithm towards providing less conservative recommendations. As a potential remedy, we discuss an algorithm that strategically withholds recommendations, and show how it can improve the quality of final decisions.
Synthetic Design: An Optimization Approach to Experimental Design with Synthetic Controls
Dec 01, 2021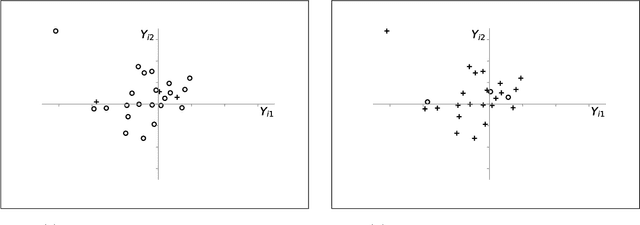
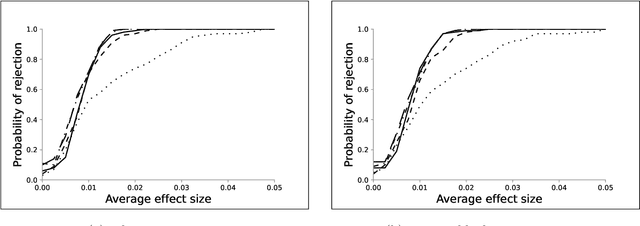
We investigate the optimal design of experimental studies that have pre-treatment outcome data available. The average treatment effect is estimated as the difference between the weighted average outcomes of the treated and control units. A number of commonly used approaches fit this formulation, including the difference-in-means estimator and a variety of synthetic-control techniques. We propose several methods for choosing the set of treated units in conjunction with the weights. Observing the NP-hardness of the problem, we introduce a mixed-integer programming formulation which selects both the treatment and control sets and unit weightings. We prove that these proposed approaches lead to qualitatively different experimental units being selected for treatment. We use simulations based on publicly available data from the US Bureau of Labor Statistics that show improvements in terms of mean squared error and statistical power when compared to simple and commonly used alternatives such as randomized trials.
On the Fairness of Machine-Assisted Human Decisions
Oct 28, 2021
When machine-learning algorithms are deployed in high-stakes decisions, we want to ensure that their deployment leads to fair and equitable outcomes. This concern has motivated a fast-growing literature that focuses on diagnosing and addressing disparities in machine predictions. However, many machine predictions are deployed to assist in decisions where a human decision-maker retains the ultimate decision authority. In this article, we therefore consider how properties of machine predictions affect the resulting human decisions. We show in a formal model that the inclusion of a biased human decision-maker can revert common relationships between the structure of the algorithm and the qualities of resulting decisions. Specifically, we document that excluding information about protected groups from the prediction may fail to reduce, and may even increase, ultimate disparities. While our concrete results rely on specific assumptions about the data, algorithm, and decision-maker, they show more broadly that any study of critical properties of complex decision systems, such as the fairness of machine-assisted human decisions, should go beyond focusing on the underlying algorithmic predictions in isolation.
Unpacking the Black Box: Regulating Algorithmic Decisions
Oct 05, 2021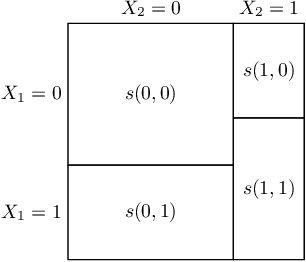
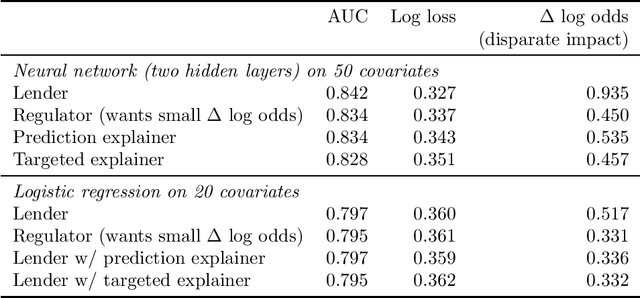
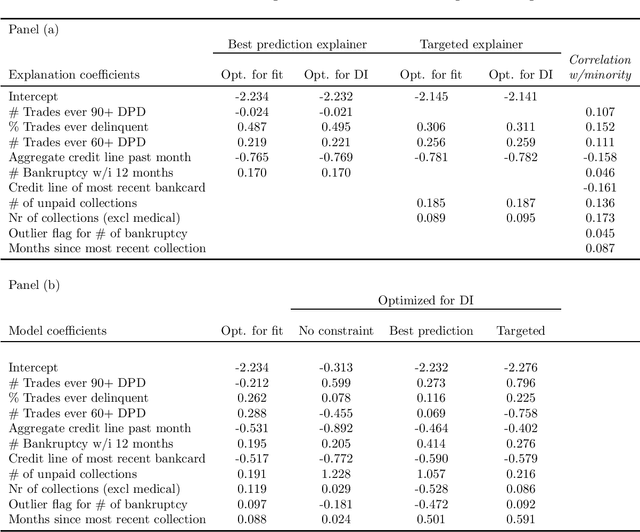
We characterize optimal oversight of algorithms in a world where an agent designs a complex prediction function but a principal is limited in the amount of information she can learn about the prediction function. We show that limiting agents to prediction functions that are simple enough to be fully transparent is inefficient as long as the bias induced by misalignment between principal's and agent's preferences is small relative to the uncertainty about the true state of the world. Algorithmic audits can improve welfare, but the gains depend on the design of the audit tools. Tools that focus on minimizing overall information loss, the focus of many post-hoc explainer tools, will generally be inefficient since they focus on explaining the average behavior of the prediction function rather than sources of mis-prediction, which matter for welfare-relevant outcomes. Targeted tools that focus on the source of incentive misalignment, e.g., excess false positives or racial disparities, can provide first-best solutions. We provide empirical support for our theoretical findings using an application in consumer lending.