 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandits with Deterministically Evolving States
Jul 21, 2023
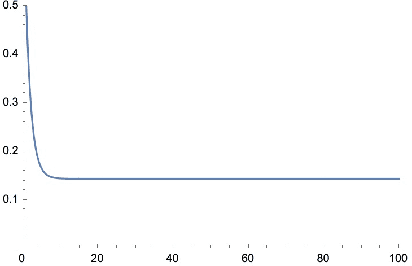
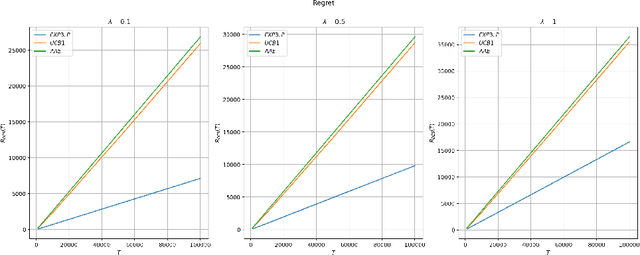
We propose a model for learning with bandit feedback while accounting for deterministically evolving and unobservable states that we call Bandits with Deterministically Evolving States. The workhorse applications of our model are learning for recommendation systems and learning for online ads. In both cases, the reward that the algorithm obtains at each round is a function of the short-term reward of the action chosen and how ``healthy'' the system is (i.e., as measured by its state). For example, in recommendation systems, the reward that the platform obtains from a user's engagement with a particular type of content depends not only on the inherent features of the specific content, but also on how the user's preferences have evolved as a result of interacting with other types of content on the platform. Our general model accounts for the different rate $\lambda \in [0,1]$ at which the state evolves (e.g., how fast a user's preferences shift as a result of previous content consumption) and encompasses standard multi-armed bandits as a special case. The goal of the algorithm is to minimize a notion of regret against the best-fixed sequence of arms pulled. We analyze online learning algorithms for any possible parametrization of the evolution rate $\lambda$. Specifically, the regret rates obtained are: for $\lambda \in [0, 1/T^2]$: $\widetilde O(\sqrt{KT})$; for $\lambda = T^{-a/b}$ with $b < a < 2b$: $\widetilde O (T^{b/a})$; for $\lambda \in (1/T, 1 - 1/\sqrt{T}): \widetilde O (K^{1/3}T^{2/3})$; and for $\lambda \in [1 - 1/\sqrt{T}, 1]: \widetilde O (K\sqrt{T})$.
Synthetic Design: An Optimization Approach to Experimental Design with Synthetic Controls
Dec 01, 2021
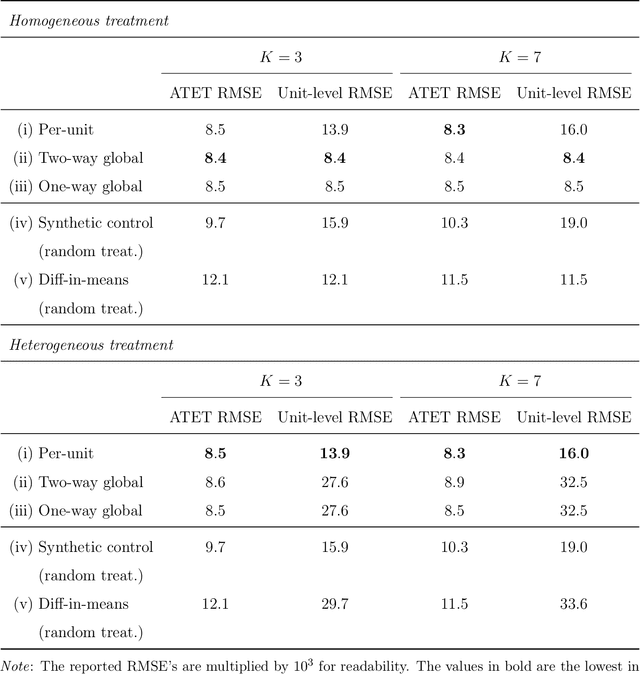
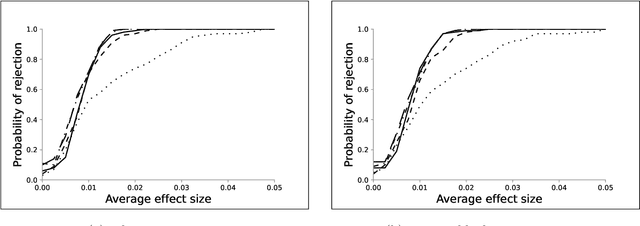
We investigate the optimal design of experimental studies that have pre-treatment outcome data available. The average treatment effect is estimated as the difference between the weighted average outcomes of the treated and control units. A number of commonly used approaches fit this formulation, including the difference-in-means estimator and a variety of synthetic-control techniques. We propose several methods for choosing the set of treated units in conjunction with the weights. Observing the NP-hardness of the problem, we introduce a mixed-integer programming formulation which selects both the treatment and control sets and unit weightings. We prove that these proposed approaches lead to qualitatively different experimental units being selected for treatment. We use simulations based on publicly available data from the US Bureau of Labor Statistics that show improvements in terms of mean squared error and statistical power when compared to simple and commonly used alternatives such as randomized trials.
Batched Neural Bandits
Feb 25, 2021
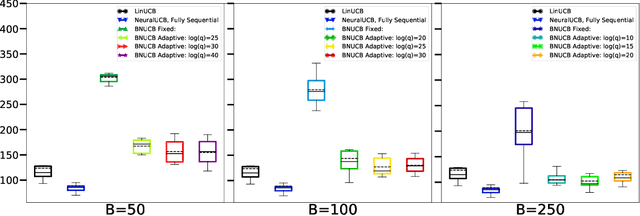


In many sequential decision-making problems, the individuals are split into several batches and the decision-maker is only allowed to change her policy at the end of batches. These batch problems have a large number of applications, ranging from clinical trials to crowdsourcing. Motivated by this, we study the stochastic contextual bandit problem for general reward distributions under the batched setting. We propose the BatchNeuralUCB algorithm which combines neural networks with optimism to address the exploration-exploitation tradeoff while keeping the total number of batches limited. We study BatchNeuralUCB under both fixed and adaptive batch size settings and prove that it achieves the same regret as the fully sequential version while reducing the number of policy updates considerably. We confirm our theoretical results via simulations on both synthetic and real-world datasets.
Optimal and Greedy Algorithms for Multi-Armed Bandits with Many Arms
Feb 24, 2020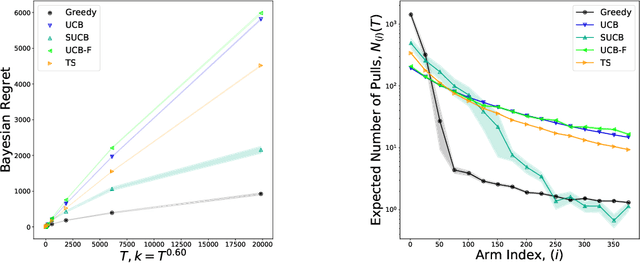
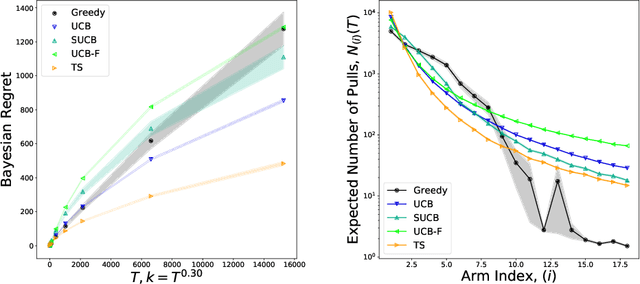
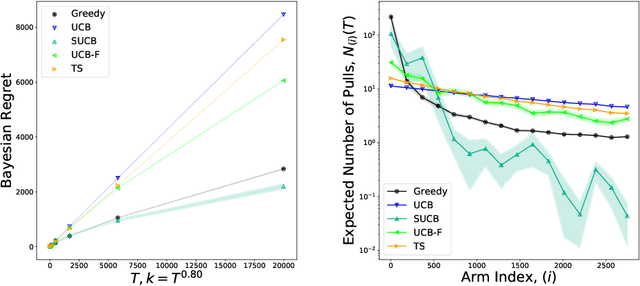
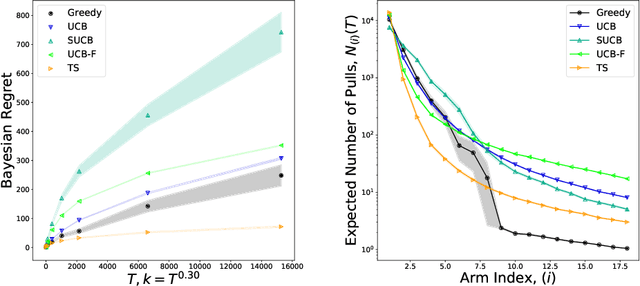
We characterize Bayesian regret in a stochastic multi-armed bandit problem with a large but finite number of arms. In particular, we assume the number of arms $k$ is $T^{\alpha}$, where $T$ is the time-horizon and $\alpha$ is in $(0,1)$. We consider a Bayesian setting where the reward distribution of each arm is drawn independently from a common prior, and provide a complete analysis of expected regret with respect to this prior. Our results exhibit a sharp distinction around $\alpha = 1/2$. When $\alpha < 1/2$, the fundamental lower bound on regret is $\Omega(k)$; and it is achieved by a standard UCB algorithm. When $\alpha > 1/2$, the fundamental lower bound on regret is $\Omega(\sqrt{T})$, and it is achieved by an algorithm that first subsamples $\sqrt{T}$ arms uniformly at random, then runs UCB on just this subset. Interestingly, we also find that a sufficiently large number of arms allows the decision-maker to benefit from "free" exploration if she simply uses a greedy algorithm. In particular, this greedy algorithm exhibits a regret of $\tilde{O}(\max(k,T/\sqrt{k}))$, which translates to a {\em sublinear} (though not optimal) regret in the time horizon. We show empirically that this is because the greedy algorithm rapidly disposes of underperforming arms, a beneficial trait in the many-armed regime. Technically, our analysis of the greedy algorithm involves a novel application of the Lundberg inequality, an upper bound for the ruin probability of a random walk; this approach may be of independent interest.
Non-Parametric Inference Adaptive to Intrinsic Dimension
Jan 11, 2019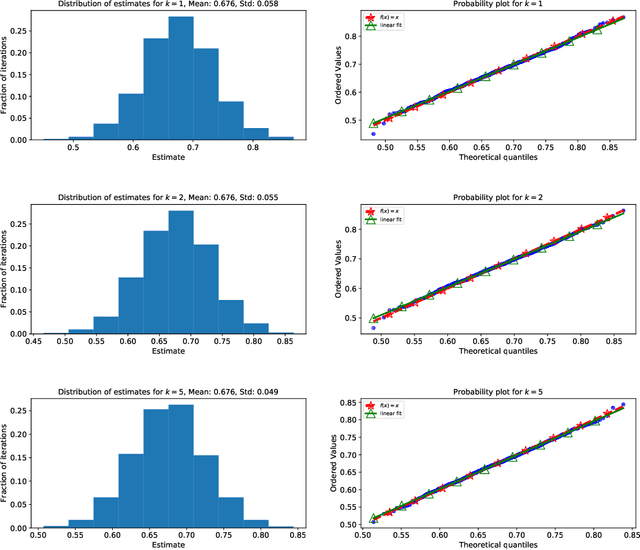
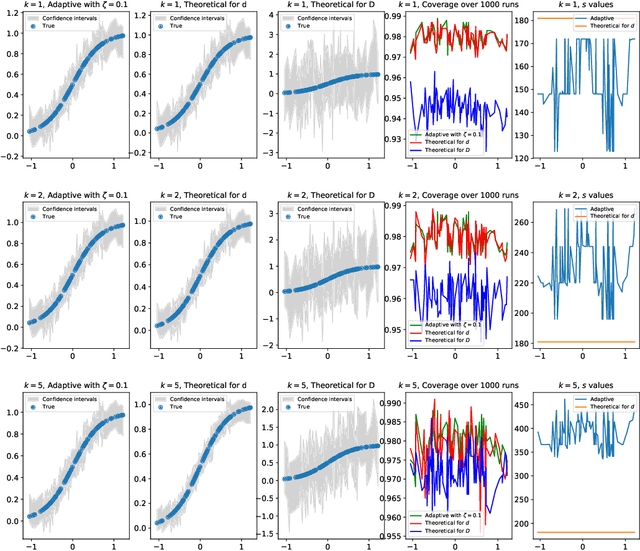
We consider non-parametric estimation and inference of conditional moment models in high dimensions. We show that even when the dimension $D$ of the conditioning variable is larger than the sample size $n$, estimation and inference is feasible as long as the distribution of the conditioning variable has small intrinsic dimension $d$, as measured by the doubling dimension. Our estimation is based on a sub-sampled ensemble of the $k$-nearest neighbors $Z$-estimator. We show that if the intrinsic dimension of the co-variate distribution is equal to $d$, then the finite sample estimation error of our estimator is of order $n^{-1/(d+2)}$ and our estimate is $n^{1/(d+2)}$-asymptotically normal, irrespective of $D$. We discuss extensions and applications to heterogeneous treatment effect estimation.
Mostly Exploration-Free Algorithms for Contextual Bandits
Oct 02, 2018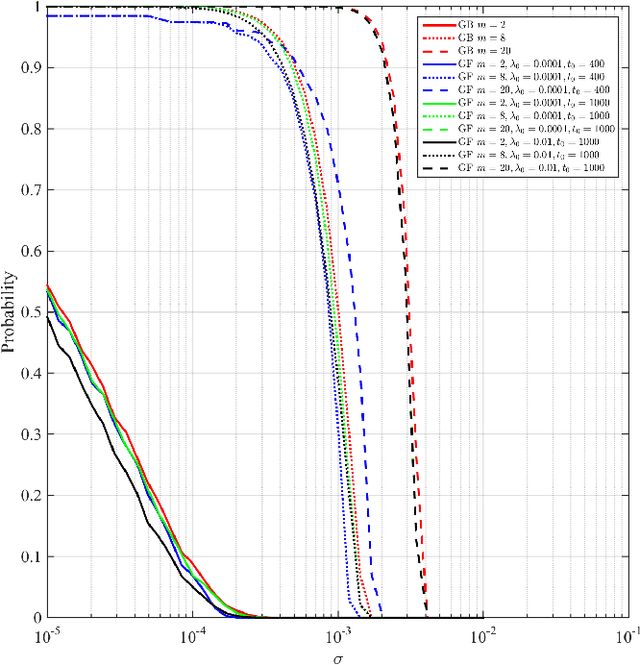
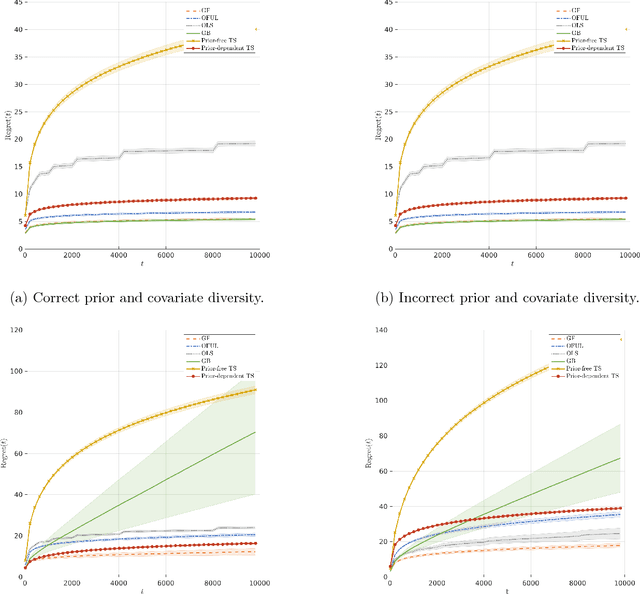
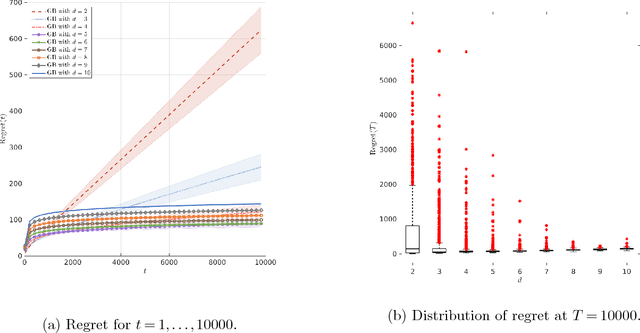
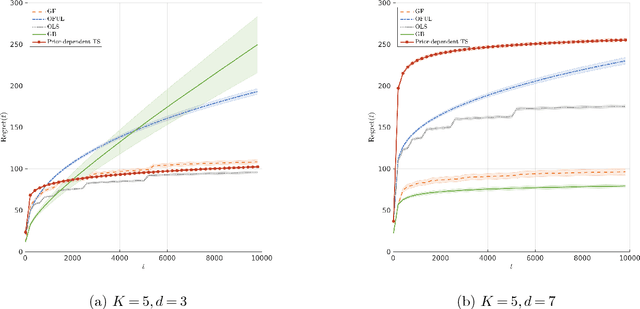
The contextual bandit literature has traditionally focused on algorithms that address the exploration-exploitation tradeoff. In particular, greedy algorithms that exploit current estimates without any exploration may be sub-optimal in general. However, exploration-free greedy algorithms are desirable in practical settings where exploration may be costly or unethical (e.g., clinical trials). Surprisingly, we find that a simple greedy algorithm can be rate-optimal (achieves asymptotically optimal regret) if there is sufficient randomness in the observed contexts (covariates). We prove that this is always the case for a two-armed bandit under a general class of context distributions that satisfy a condition we term $\textit{covariate diversity}$. Furthermore, even absent this condition, we show that a greedy algorithm can be rate optimal with positive probability. Thus, standard bandit algorithms may unnecessarily explore. Motivated by these results, we introduce Greedy-First, a new algorithm that uses only observed contexts and rewards to determine whether to follow a greedy algorithm or to explore. We prove that this algorithm is rate-optimal without any additional assumptions on the context distribution or the number of arms. Extensive simulations demonstrate that Greedy-First successfully reduces exploration and outperforms existing (exploration-based) contextual bandit algorithms such as Thompson sampling or upper confidence bound (UCB).
Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling
Mar 11, 2017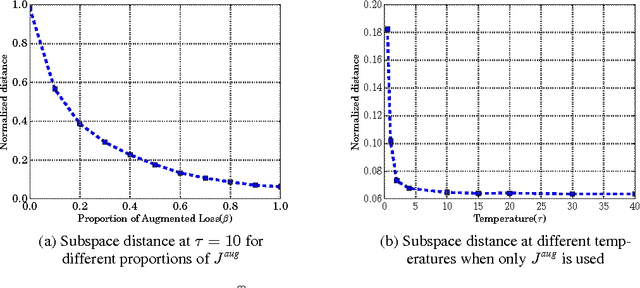
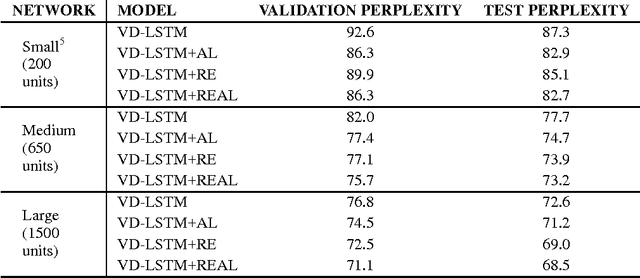
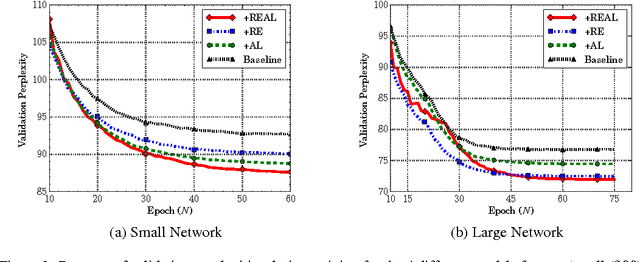

Recurrent neural networks have been very successful at predicting sequences of words in tasks such as language modeling. However, all such models are based on the conventional classification framework, where the model is trained against one-hot targets, and each word is represented both as an input and as an output in isolation. This causes inefficiencies in learning both in terms of utilizing all of the information and in terms of the number of parameters needed to train. We introduce a novel theoretical framework that facilitates better learning in language modeling, and show that our framework leads to tying together the input embedding and the output projection matrices, greatly reducing the number of trainable variables. Our framework leads to state of the art performance on the Penn Treebank with a variety of network models.