 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre AI Capabilities Increasing Exponentially? A Competing Hypothesis
Feb 04, 2026Rapidly increasing AI capabilities have substantial real-world consequences, ranging from AI safety concerns to labor market consequences. The Model Evaluation & Threat Research (METR) report argues that AI capabilities have exhibited exponential growth since 2019. In this note, we argue that the data does not support exponential growth, even in shorter-term horizons. Whereas the METR study claims that fitting sigmoid/logistic curves results in inflection points far in the future, we fit a sigmoid curve to their current data and find that the inflection point has already passed. In addition, we propose a more complex model that decomposes AI capabilities into base and reasoning capabilities, exhibiting individual rates of improvement. We prove that this model supports our hypothesis that AI capabilities will exhibit an inflection point in the near future. Our goal is not to establish a rigorous forecast of our own, but to highlight the fragility of existing forecasts of exponential growth.
Hiring under Congestion and Algorithmic Monoculture: Value of Strategic Behavior
Feb 27, 2025We study the impact of strategic behavior in a setting where firms compete to hire from a shared pool of applicants, and firms use a common algorithm to evaluate them. Each applicant is associated with a scalar score that is observed by all firms, provided by the algorithm. Firms simultaneously make interview decisions, where the number of interviews is capacity-constrained. Job offers are given to those who pass the interview, and an applicant who receives multiple offers accepts one of them uniformly at random. We fully characterize the set of Nash equilibria under this model. Defining social welfare as the total number of applicants who find a job, we then compare the social welfare at a Nash equilibrium to a naive baseline where all firms interview applicants with the highest scores. We show that the Nash equilibrium greatly improves upon social welfare compared to the naive baseline, especially when the interview capacity is small and the number of firms is large. We also show that the price of anarchy is small, providing further appeal for the equilibrium solution. We then study how the firms may converge to a Nash equilibrium. We show that when firms make interview decisions sequentially and each firm takes the best response action assuming they are the last to act, this process converges to an equilibrium when interview capacities are small. However, we show that the task of computing the best response is difficult if firms have to use its own historical samples to estimate it, while this task becomes trivial if firms have information on the degree of competition for each applicant. Therefore, converging to an equilibrium can be greatly facilitated if firms have information on the level of competition for each applicant.
Stochastic Online Conformal Prediction with Semi-Bandit Feedback
May 22, 2024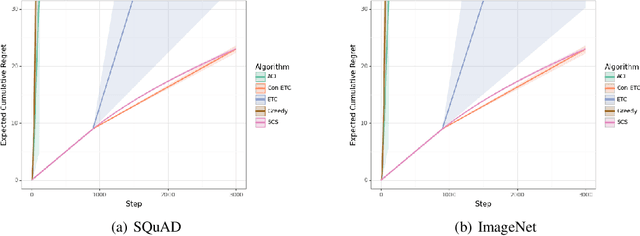
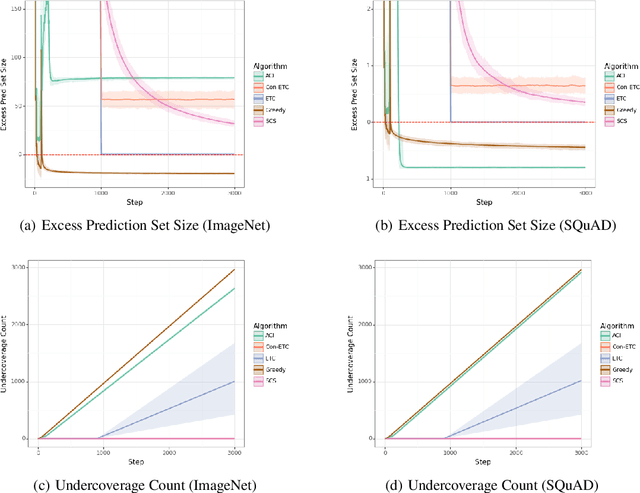
Conformal prediction has emerged as an effective strategy for uncertainty quantification by modifying a model to output sets of labels instead of a single label. These prediction sets come with the guarantee that they contain the true label with high probability. However, conformal prediction typically requires a large calibration dataset of i.i.d. examples. We consider the online learning setting, where examples arrive over time, and the goal is to construct prediction sets dynamically. Departing from existing work, we assume semi-bandit feedback, where we only observe the true label if it is contained in the prediction set. For instance, consider calibrating a document retrieval model to a new domain; in this setting, a user would only be able to provide the true label if the target document is in the prediction set of retrieved documents. We propose a novel conformal prediction algorithm targeted at this setting, and prove that it obtains sublinear regret compared to the optimal conformal predictor. We evaluate our algorithm on a retrieval task and an image classification task, and demonstrate that it empirically achieves good performance.
Stochastic Bandits with ReLU Neural Networks
May 12, 2024We study the stochastic bandit problem with ReLU neural network structure. We show that a $\tilde{O}(\sqrt{T})$ regret guarantee is achievable by considering bandits with one-layer ReLU neural networks; to the best of our knowledge, our work is the first to achieve such a guarantee. In this specific setting, we propose an OFU-ReLU algorithm that can achieve this upper bound. The algorithm first explores randomly until it reaches a linear regime, and then implements a UCB-type linear bandit algorithm to balance exploration and exploitation. Our key insight is that we can exploit the piecewise linear structure of ReLU activations and convert the problem into a linear bandit in a transformed feature space, once we learn the parameters of ReLU relatively accurately during the exploration stage. To remove dependence on model parameters, we design an OFU-ReLU+ algorithm based on a batching strategy, which can provide the same theoretical guarantee.
Generative Adversarial Bayesian Optimization for Surrogate Objectives
Feb 09, 2024Offline model-based policy optimization seeks to optimize a learned surrogate objective function without querying the true oracle objective during optimization. However, inaccurate surrogate model predictions are frequently encountered along the optimization trajectory. To address this limitation, we propose generative adversarial Bayesian optimization (GABO) using adaptive source critic regularization, a task-agnostic framework for Bayesian optimization that employs a Lipschitz-bounded source critic model to constrain the optimization trajectory to regions where the surrogate function is reliable. We show that under certain assumptions for the continuous input space prior, our algorithm dynamically adjusts the strength of the source critic regularization. GABO outperforms existing baselines on a number of different offline optimization tasks across a variety of scientific domains. Our code is available at https://github.com/michael-s-yao/gabo
Rethinking Fairness for Human-AI Collaboration
Oct 05, 2023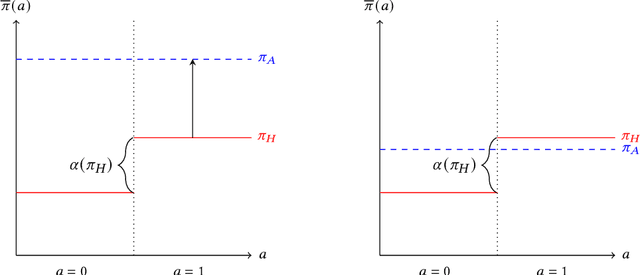
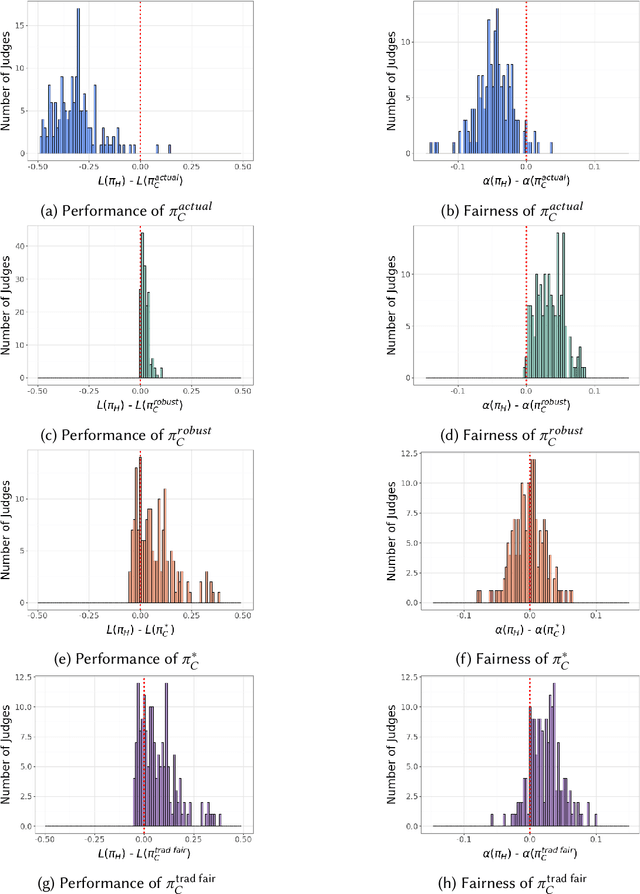
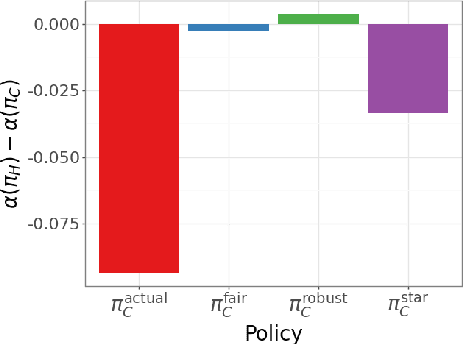
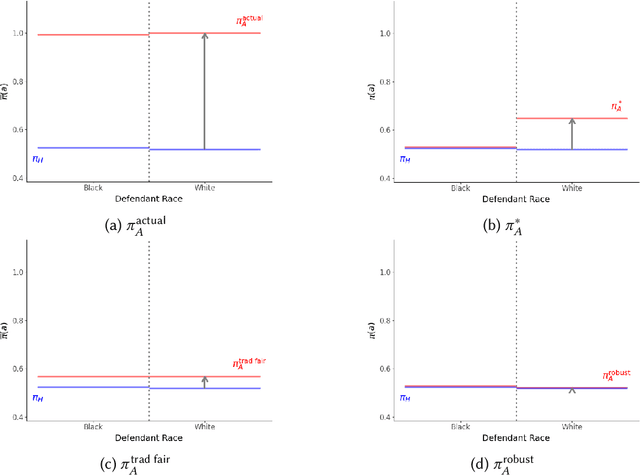
Existing approaches to algorithmic fairness aim to ensure equitable outcomes if human decision-makers comply perfectly with algorithmic decisions. However, perfect compliance with the algorithm is rarely a reality or even a desirable outcome in human-AI collaboration. Yet, recent studies have shown that selective compliance with fair algorithms can amplify discrimination relative to the prior human policy. As a consequence, ensuring equitable outcomes requires fundamentally different algorithmic design principles that ensure robustness to the decision-maker's (a priori unknown) compliance pattern. We define the notion of compliance-robustly fair algorithmic recommendations that are guaranteed to (weakly) improve fairness in decisions, regardless of the human's compliance pattern. We propose a simple optimization strategy to identify the best performance-improving compliance-robustly fair policy. However, we show that it may be infeasible to design algorithmic recommendations that are simultaneously fair in isolation, compliance-robustly fair, and more accurate than the human policy; thus, if our goal is to improve the equity and accuracy of human-AI collaboration, it may not be desirable to enforce traditional fairness constraints.
Optimal Heterogeneous Collaborative Linear Regression and Contextual Bandits
Jun 09, 2023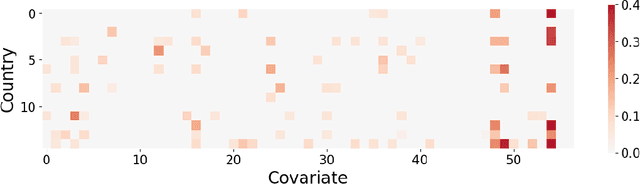

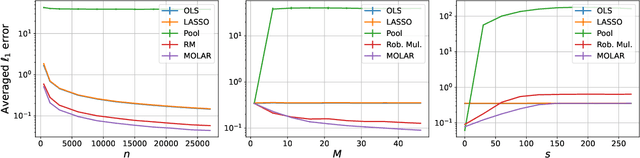
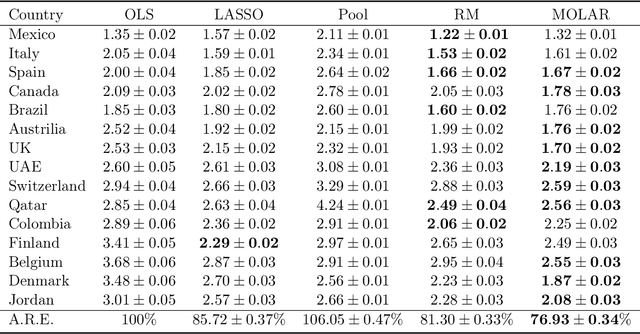
Large and complex datasets are often collected from several, possibly heterogeneous sources. Collaborative learning methods improve efficiency by leveraging commonalities across datasets while accounting for possible differences among them. Here we study collaborative linear regression and contextual bandits, where each instance's associated parameters are equal to a global parameter plus a sparse instance-specific term. We propose a novel two-stage estimator called MOLAR that leverages this structure by first constructing an entry-wise median of the instances' linear regression estimates, and then shrinking the instance-specific estimates towards the median. MOLAR improves the dependence of the estimation error on the data dimension, compared to independent least squares estimates. We then apply MOLAR to develop methods for sparsely heterogeneous collaborative contextual bandits, which lead to improved regret guarantees compared to independent bandit methods. We further show that our methods are minimax optimal by providing a number of lower bounds. Finally, we support the efficiency of our methods by performing experiments on both synthetic data and the PISA dataset on student educational outcomes from heterogeneous countries.
Decision-Aware Learning for Optimizing Health Supply Chains
Nov 15, 2022



We study the problem of allocating limited supply of medical resources in developing countries, in particular, Sierra Leone. We address this problem by combining machine learning (to predict demand) with optimization (to optimize allocations). A key challenge is the need to align the loss function used to train the machine learning model with the decision loss associated with the downstream optimization problem. Traditional solutions have limited flexibility in the model architecture and scale poorly to large datasets. We propose a decision-aware learning algorithm that uses a novel Taylor expansion of the optimal decision loss to derive the machine learning loss. Importantly, our approach only requires a simple re-weighting of the training data, ensuring it is both flexible and scalable, e.g., we incorporate it into a random forest trained using a multitask learning framework. We apply our framework to optimize the distribution of essential medicines in collaboration with policymakers in Sierra Leone; highly uncertain demand and limited budgets currently result in excessive unmet demand. Out-of-sample results demonstrate that our end-to-end approach can significantly reduce unmet demand across 1040 health facilities throughout Sierra Leone.
Bandits for Online Calibration: An Application to Content Moderation on Social Media Platforms
Nov 11, 2022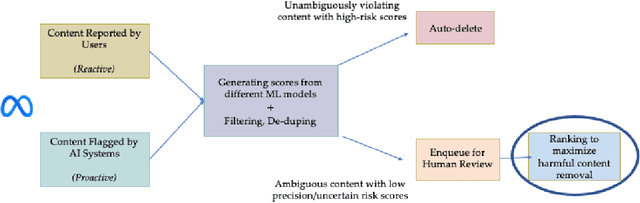
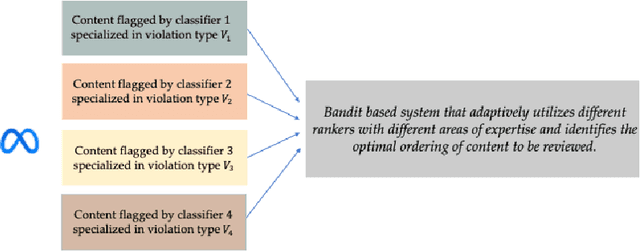
We describe the current content moderation strategy employed by Meta to remove policy-violating content from its platforms. Meta relies on both handcrafted and learned risk models to flag potentially violating content for human review. Our approach aggregates these risk models into a single ranking score, calibrating them to prioritize more reliable risk models. A key challenge is that violation trends change over time, affecting which risk models are most reliable. Our system additionally handles production challenges such as changing risk models and novel risk models. We use a contextual bandit to update the calibration in response to such trends. Our approach increases Meta's top-line metric for measuring the effectiveness of its content moderation strategy by 13%.
Learning Across Bandits in High Dimension via Robust Statistics
Dec 28, 2021
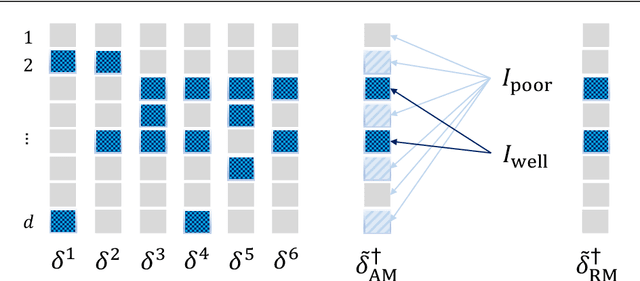
Decision-makers often face the "many bandits" problem, where one must simultaneously learn across related but heterogeneous contextual bandit instances. For instance, a large retailer may wish to dynamically learn product demand across many stores to solve pricing or inventory problems, making it desirable to learn jointly for stores serving similar customers; alternatively, a hospital network may wish to dynamically learn patient risk across many providers to allocate personalized interventions, making it desirable to learn jointly for hospitals serving similar patient populations. We study the setting where the unknown parameter in each bandit instance can be decomposed into a global parameter plus a sparse instance-specific term. Then, we propose a novel two-stage estimator that exploits this structure in a sample-efficient way by using a combination of robust statistics (to learn across similar instances) and LASSO regression (to debias the results). We embed this estimator within a bandit algorithm, and prove that it improves asymptotic regret bounds in the context dimension $d$; this improvement is exponential for data-poor instances. We further demonstrate how our results depend on the underlying network structure of bandit instances.