 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Query Synthesis via Bayesian Optimization
Mar 02, 2026Benchmark workloads are extremely important to the database management research community, especially as more machine learning components are integrated into database systems. Here, we propose a Bayesian optimization technique to automatically search for difficult benchmark queries, significantly reducing the amount of manual effort usually required. In preliminary experiments, we show that our approach can generate queries with more than double the optimization headroom compared to existing benchmarks.
Purely Agentic Black-Box Optimization for Biological Design
Jan 29, 2026Many key challenges in biological design-such as small-molecule drug discovery, antimicrobial peptide development, and protein engineering-can be framed as black-box optimization over vast, complex structured spaces. Existing methods rely mainly on raw structural data and struggle to exploit the rich scientific literature. While large language models (LLMs) have been added to these pipelines, they have been confined to narrow roles within structure-centered optimizers. We instead cast biological black-box optimization as a fully agentic, language-based reasoning process. We introduce Purely Agentic BLack-box Optimization (PABLO), a hierarchical agentic system that uses scientific LLMs pretrained on chemistry and biology literature to generate and iteratively refine biological candidates. On both the standard GuacaMol molecular design and antimicrobial peptide optimization tasks, PABLO achieves state-of-the-art performance, substantially improving sample efficiency and final objective values over established baselines. Compared to prior optimization methods that incorporate LLMs, PABLO achieves competitive token usage per run despite relying on LLMs throughout the optimization loop. Beyond raw performance, the agentic formulation offers key advantages for realistic design: it naturally incorporates semantic task descriptions, retrieval-augmented domain knowledge, and complex constraints. In follow-up in vitro validation, PABLO-optimized peptides showed strong activity against drug-resistant pathogens, underscoring the practical potential of PABLO for therapeutic discovery.
Large Scale Multi-Task Bayesian Optimization with Large Language Models
Mar 11, 2025



In multi-task Bayesian optimization, the goal is to leverage experience from optimizing existing tasks to improve the efficiency of optimizing new ones. While approaches using multi-task Gaussian processes or deep kernel transfer exist, the performance improvement is marginal when scaling to more than a moderate number of tasks. We introduce a novel approach leveraging large language models (LLMs) to learn from, and improve upon, previous optimization trajectories, scaling to approximately 2000 distinct tasks. Specifically, we propose an iterative framework in which an LLM is fine-tuned using the high quality solutions produced by BayesOpt to generate improved initializations that accelerate convergence for future optimization tasks based on previous search trajectories. We evaluate our method on two distinct domains: database query optimization and antimicrobial peptide design. Results demonstrate that our approach creates a positive feedback loop, where the LLM's generated initializations gradually improve, leading to better optimization performance. As this feedback loop continues, we find that the LLM is eventually able to generate solutions to new tasks in just a few shots that are better than the solutions produced by "from scratch" by Bayesian optimization while simultaneously requiring significantly fewer oracle calls.
Covering Multiple Objectives with a Small Set of Solutions Using Bayesian Optimization
Jan 31, 2025In multi-objective black-box optimization, the goal is typically to find solutions that optimize a set of T black-box objective functions, $f_1$, ..., $f_T$, simultaneously. Traditional approaches often seek a single Pareto-optimal set that balances trade-offs among all objectives. In this work, we introduce a novel problem setting that departs from this paradigm: finding a smaller set of K solutions, where K < T, that collectively "covers" the T objectives. A set of solutions is defined as "covering" if, for each objective $f_1$, ..., $f_T$, there is at least one good solution. A motivating example for this problem setting occurs in drug design. For example, we may have T pathogens and aim to identify a set of K < T antibiotics such that at least one antibiotic can be used to treat each pathogen. To address this problem, we propose Multi-Objective Coverage Bayesian Optimization (MOCOBO), a principled algorithm designed to efficiently find a covering set. We validate our approach through extensive experiments on challenging high-dimensional tasks, including applications in peptide and molecular design. Experiments demonstrate MOCOBO's ability to find high-performing covering sets of solutions. Additionally, we show that the small sets of K < T solutions found by MOCOBO can match or nearly match the performance of T individually optimized solutions for the same objectives. Our results highlight MOCOBO's potential to tackle complex multi-objective problems in domains where finding at least one high-performing solution for each objective is critical.
Improving Structural Diversity of Blackbox LLMs via Chain-of-Specification Prompting
Aug 12, 2024
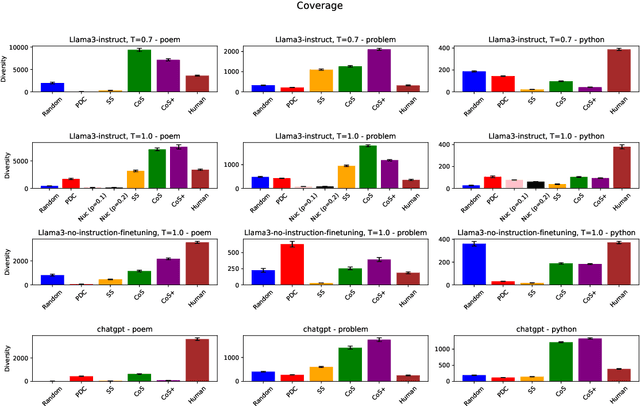
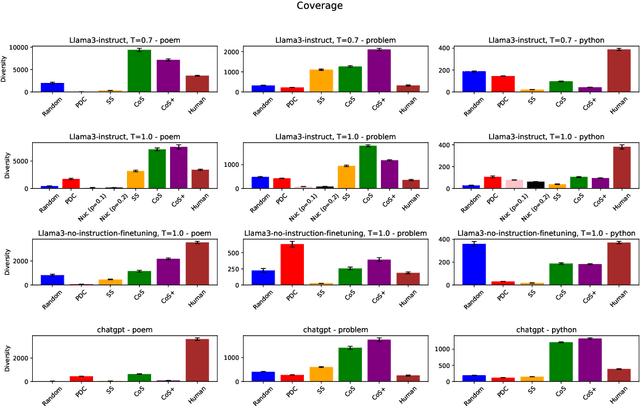
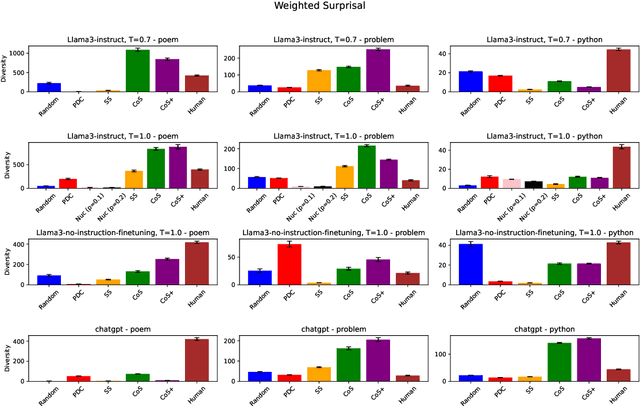
The capability to generate diverse text is a key challenge facing large language models (LLMs). Thus far, diversity has been studied via metrics such as $n$-gram diversity or diversity of BERT embeddings. However, for these kinds of diversity, the user has little control over the dimensions along which diversity is considered. For example, in the poetry domain, one might desire diversity in terms of rhyme and meter, whereas in the code domain, one might desire diversity in terms of the kinds of expressions used to solve a problem. We propose a diversity metric called structural diversity, where the user provides a mapping from generated text to features capturing the kinds of diversity that they care about. In addition, we propose a novel strategy called chain-of-specification (CoS) prompting for improving diversity by first having the LLM generate a specification encoding one instance of structural features, and then prompting the LLM to generate text that satisfies these features; notably, our strategy works with blackbox LLMs. In our experiments, we show that for structural diversity in the poetry and code domains, CoS significantly improves diversity compared to several baselines.
Zeroth-Order Fine-Tuning of LLMs with Extreme Sparsity
Jun 05, 2024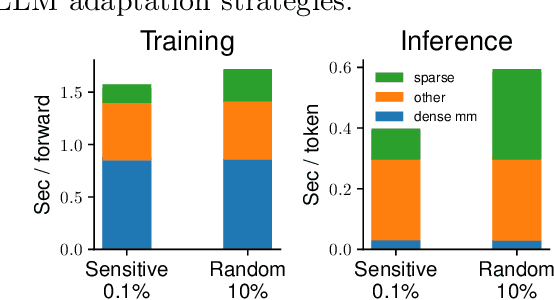
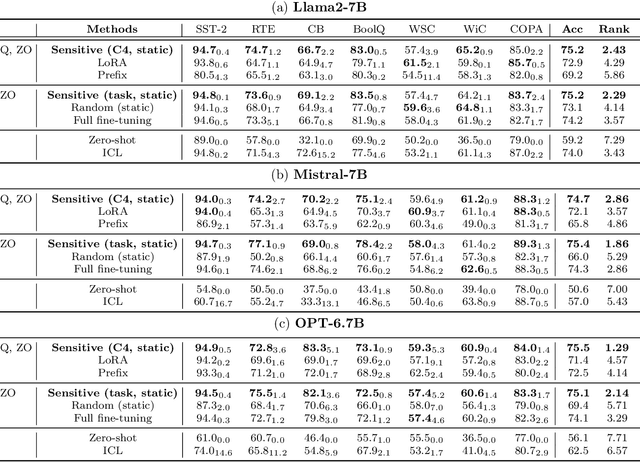
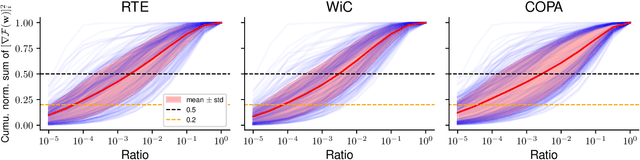
Zeroth-order optimization (ZO) is a memory-efficient strategy for fine-tuning Large Language Models using only forward passes. However, the application of ZO fine-tuning in memory-constrained settings such as mobile phones and laptops is still challenging since full precision forward passes are infeasible. In this study, we address this limitation by integrating sparsity and quantization into ZO fine-tuning of LLMs. Specifically, we investigate the feasibility of fine-tuning an extremely small subset of LLM parameters using ZO. This approach allows the majority of un-tuned parameters to be quantized to accommodate the constraint of limited device memory. Our findings reveal that the pre-training process can identify a set of "sensitive parameters" that can guide the ZO fine-tuning of LLMs on downstream tasks. Our results demonstrate that fine-tuning 0.1% sensitive parameters in the LLM with ZO can outperform the full ZO fine-tuning performance, while offering wall-clock time speedup. Additionally, we show that ZO fine-tuning targeting these 0.1% sensitive parameters, combined with 4 bit quantization, enables efficient ZO fine-tuning of an Llama2-7B model on a GPU device with less than 8 GiB of memory and notably reduced latency.
Generative Adversarial Bayesian Optimization for Surrogate Objectives
Feb 09, 2024


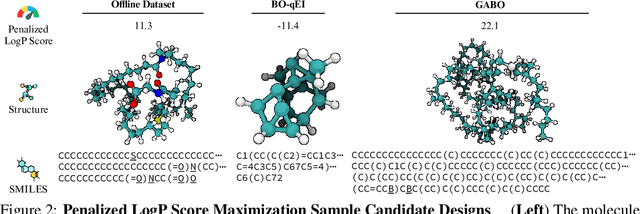
Offline model-based policy optimization seeks to optimize a learned surrogate objective function without querying the true oracle objective during optimization. However, inaccurate surrogate model predictions are frequently encountered along the optimization trajectory. To address this limitation, we propose generative adversarial Bayesian optimization (GABO) using adaptive source critic regularization, a task-agnostic framework for Bayesian optimization that employs a Lipschitz-bounded source critic model to constrain the optimization trajectory to regions where the surrogate function is reliable. We show that under certain assumptions for the continuous input space prior, our algorithm dynamically adjusts the strength of the source critic regularization. GABO outperforms existing baselines on a number of different offline optimization tasks across a variety of scientific domains. Our code is available at https://github.com/michael-s-yao/gabo
Cyclical Kernel Adaptive Metropolis
Jun 30, 2022


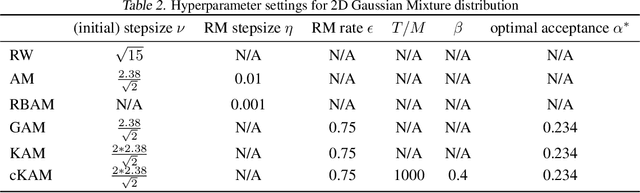
We propose cKAM, cyclical Kernel Adaptive Metropolis, which incorporates a cyclical stepsize scheme to allow control for exploration and sampling. We show that on a crafted bimodal distribution, existing Adaptive Metropolis type algorithms would fail to converge to the true posterior distribution. We point out that this is because adaptive samplers estimates the local/global covariance structure using past history of the chain, which will lead to adaptive algorithms be trapped in a local mode. We demonstrate that cKAM encourages exploration of the posterior distribution and allows the sampler to escape from a local mode, while maintaining the high performance of adaptive methods.