 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Heterogeneous Collaborative Linear Regression and Contextual Bandits
Paper and Code
Jun 09, 2023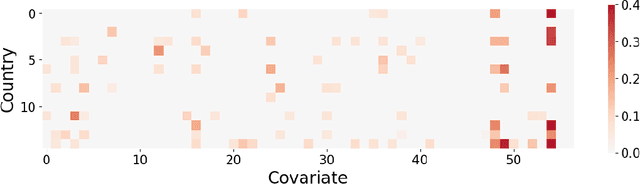

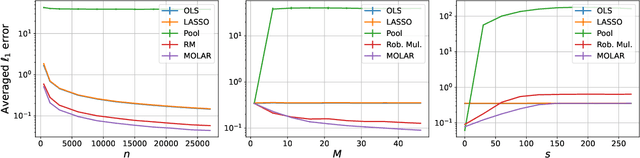
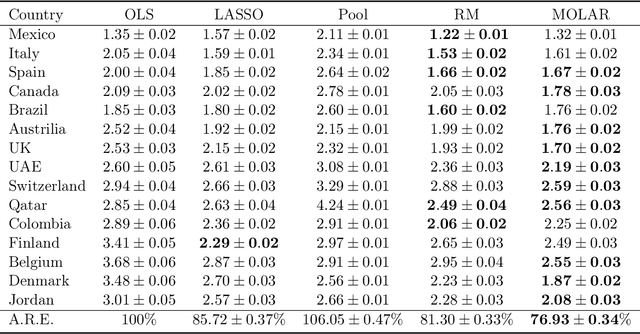
Large and complex datasets are often collected from several, possibly heterogeneous sources. Collaborative learning methods improve efficiency by leveraging commonalities across datasets while accounting for possible differences among them. Here we study collaborative linear regression and contextual bandits, where each instance's associated parameters are equal to a global parameter plus a sparse instance-specific term. We propose a novel two-stage estimator called MOLAR that leverages this structure by first constructing an entry-wise median of the instances' linear regression estimates, and then shrinking the instance-specific estimates towards the median. MOLAR improves the dependence of the estimation error on the data dimension, compared to independent least squares estimates. We then apply MOLAR to develop methods for sparsely heterogeneous collaborative contextual bandits, which lead to improved regret guarantees compared to independent bandit methods. We further show that our methods are minimax optimal by providing a number of lower bounds. Finally, we support the efficiency of our methods by performing experiments on both synthetic data and the PISA dataset on student educational outcomes from heterogeneous countries.