 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre AI Capabilities Increasing Exponentially? A Competing Hypothesis
Feb 04, 2026Rapidly increasing AI capabilities have substantial real-world consequences, ranging from AI safety concerns to labor market consequences. The Model Evaluation & Threat Research (METR) report argues that AI capabilities have exhibited exponential growth since 2019. In this note, we argue that the data does not support exponential growth, even in shorter-term horizons. Whereas the METR study claims that fitting sigmoid/logistic curves results in inflection points far in the future, we fit a sigmoid curve to their current data and find that the inflection point has already passed. In addition, we propose a more complex model that decomposes AI capabilities into base and reasoning capabilities, exhibiting individual rates of improvement. We prove that this model supports our hypothesis that AI capabilities will exhibit an inflection point in the near future. Our goal is not to establish a rigorous forecast of our own, but to highlight the fragility of existing forecasts of exponential growth.
Stochastic Online Conformal Prediction with Semi-Bandit Feedback
May 22, 2024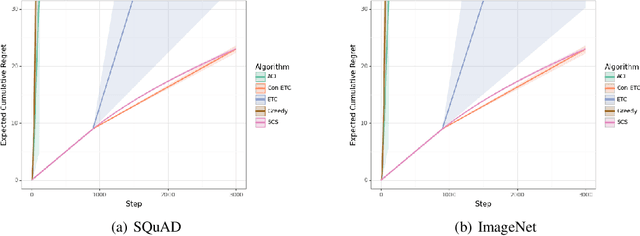
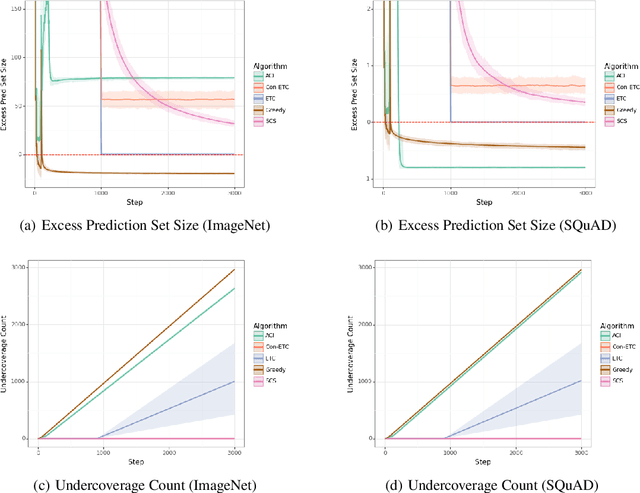
Conformal prediction has emerged as an effective strategy for uncertainty quantification by modifying a model to output sets of labels instead of a single label. These prediction sets come with the guarantee that they contain the true label with high probability. However, conformal prediction typically requires a large calibration dataset of i.i.d. examples. We consider the online learning setting, where examples arrive over time, and the goal is to construct prediction sets dynamically. Departing from existing work, we assume semi-bandit feedback, where we only observe the true label if it is contained in the prediction set. For instance, consider calibrating a document retrieval model to a new domain; in this setting, a user would only be able to provide the true label if the target document is in the prediction set of retrieved documents. We propose a novel conformal prediction algorithm targeted at this setting, and prove that it obtains sublinear regret compared to the optimal conformal predictor. We evaluate our algorithm on a retrieval task and an image classification task, and demonstrate that it empirically achieves good performance.
Rethinking Fairness for Human-AI Collaboration
Oct 05, 2023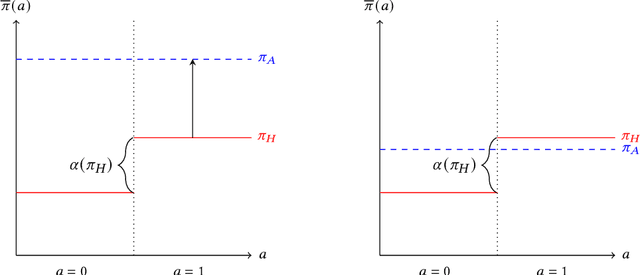
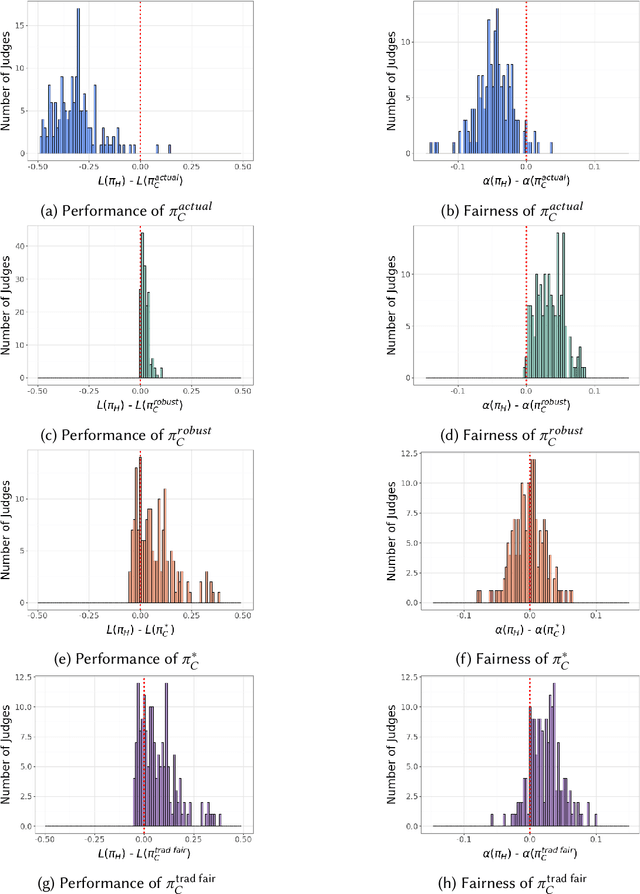
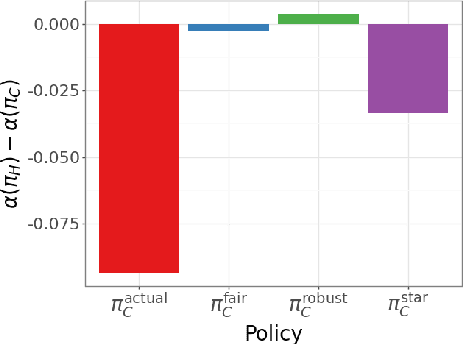
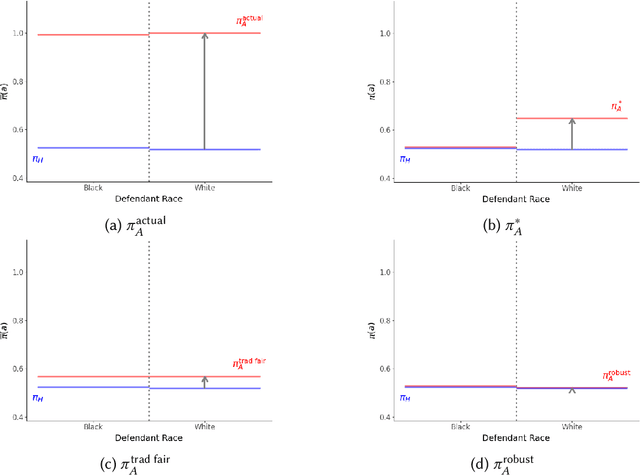
Existing approaches to algorithmic fairness aim to ensure equitable outcomes if human decision-makers comply perfectly with algorithmic decisions. However, perfect compliance with the algorithm is rarely a reality or even a desirable outcome in human-AI collaboration. Yet, recent studies have shown that selective compliance with fair algorithms can amplify discrimination relative to the prior human policy. As a consequence, ensuring equitable outcomes requires fundamentally different algorithmic design principles that ensure robustness to the decision-maker's (a priori unknown) compliance pattern. We define the notion of compliance-robustly fair algorithmic recommendations that are guaranteed to (weakly) improve fairness in decisions, regardless of the human's compliance pattern. We propose a simple optimization strategy to identify the best performance-improving compliance-robustly fair policy. However, we show that it may be infeasible to design algorithmic recommendations that are simultaneously fair in isolation, compliance-robustly fair, and more accurate than the human policy; thus, if our goal is to improve the equity and accuracy of human-AI collaboration, it may not be desirable to enforce traditional fairness constraints.
Transformer Encoder for Social Science
Aug 17, 2022
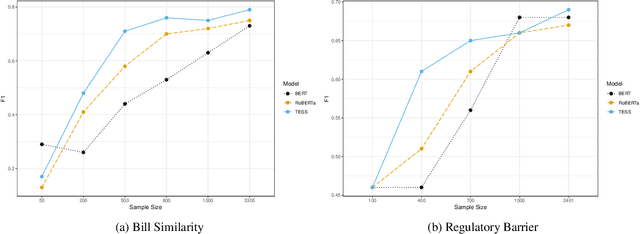
High-quality text data has become an important data source for social scientists. We have witnessed the success of pretrained deep neural network models, such as BERT and RoBERTa, in recent social science research. In this paper, we propose a compact pretrained deep neural network, Transformer Encoder for Social Science (TESS), explicitly designed to tackle text processing tasks in social science research. Using two validation tests, we demonstrate that TESS outperforms BERT and RoBERTa by 16.7% on average when the number of training samples is limited (<1,000 training instances). The results display the superiority of TESS over BERT and RoBERTa on social science text processing tasks. Lastly, we discuss the limitation of our model and present advice for future researchers.