 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Exploration of New Products under Assortment Decisions
Apr 20, 2026We study online learning for new products on a platform that makes capacity-constrained assortment decisions on which products to offer. For a newly listed product, its quality is initially unknown, and quality information propagates through social learning: when a customer purchases a new product and leaves a review, its quality is revealed to both the platform and future customers. Since reviews require purchases, the platform must feature new products in the assortment ("explore") to generate reviews to learn about new products. Such exploration is costly because customer demand for new products is lower than for incumbent products. We characterize the optimal assortments for exploration to minimize regret, addressing two questions. (1) Should the platform offer a new product alone or alongside incumbent products? The former maximizes the purchase probability of the new product but yields lower short-term revenue. Despite the lower purchase probability, we show it is always optimal to pair the new product with the top incumbent products. (2) With multiple new products, should the platform explore them simultaneously or one at a time? We show that the optimal number of new products to explore simultaneously has a simple threshold structure: it increases with the "potential" of the new products and, surprisingly, does not depend on their individual purchase probabilities. We also show that two canonical bandit algorithms, UCB and Thompson Sampling, both fail in this setting for opposite reasons: UCB over-explores while Thompson Sampling under-explores. Our results provide structural insights on how platforms should learn about new products through assortment decisions.
AI Agents for Inventory Control: Human-LLM-OR Complementarity
Feb 13, 2026Inventory control is a fundamental operations problem in which ordering decisions are traditionally guided by theoretically grounded operations research (OR) algorithms. However, such algorithms often rely on rigid modeling assumptions and can perform poorly when demand distributions shift or relevant contextual information is unavailable. Recent advances in large language models (LLMs) have generated interest in AI agents that can reason flexibly and incorporate rich contextual signals, but it remains unclear how best to incorporate LLM-based methods into traditional decision-making pipelines. We study how OR algorithms, LLMs, and humans can interact and complement each other in a multi-period inventory control setting. We construct InventoryBench, a benchmark of over 1,000 inventory instances spanning both synthetic and real-world demand data, designed to stress-test decision rules under demand shifts, seasonality, and uncertain lead times. Through this benchmark, we find that OR-augmented LLM methods outperform either method in isolation, suggesting that these methods are complementary rather than substitutes. We further investigate the role of humans through a controlled classroom experiment that embeds LLM recommendations into a human-in-the-loop decision pipeline. Contrary to prior findings that human-AI collaboration can degrade performance, we show that, on average, human-AI teams achieve higher profits than either humans or AI agents operating alone. Beyond this population-level finding, we formalize an individual-level complementarity effect and derive a distribution-free lower bound on the fraction of individuals who benefit from AI collaboration; empirically, we find this fraction to be substantial.
Evaluating LLM-persona Generated Distributions for Decision-making
Feb 06, 2026LLMs can generate a wealth of data, ranging from simulated personas imitating human valuations and preferences, to demand forecasts based on world knowledge. But how well do such LLM-generated distributions support downstream decision-making? For example, when pricing a new product, a firm could prompt an LLM to simulate how much consumers are willing to pay based on a product description, but how useful is the resulting distribution for optimizing the price? We refer to this approach as LLM-SAA, in which an LLM is used to construct an estimated distribution and the decision is then optimized under that distribution. In this paper, we study metrics to evaluate the quality of these LLM-generated distributions, based on the decisions they induce. Taking three canonical decision-making problems (assortment optimization, pricing, and newsvendor) as examples, we find that LLM-generated distributions are practically useful, especially in low-data regimes. We also show that decision-agnostic metrics such as Wasserstein distance can be misleading when evaluating these distributions for decision-making.
Hiring under Congestion and Algorithmic Monoculture: Value of Strategic Behavior
Feb 27, 2025We study the impact of strategic behavior in a setting where firms compete to hire from a shared pool of applicants, and firms use a common algorithm to evaluate them. Each applicant is associated with a scalar score that is observed by all firms, provided by the algorithm. Firms simultaneously make interview decisions, where the number of interviews is capacity-constrained. Job offers are given to those who pass the interview, and an applicant who receives multiple offers accepts one of them uniformly at random. We fully characterize the set of Nash equilibria under this model. Defining social welfare as the total number of applicants who find a job, we then compare the social welfare at a Nash equilibrium to a naive baseline where all firms interview applicants with the highest scores. We show that the Nash equilibrium greatly improves upon social welfare compared to the naive baseline, especially when the interview capacity is small and the number of firms is large. We also show that the price of anarchy is small, providing further appeal for the equilibrium solution. We then study how the firms may converge to a Nash equilibrium. We show that when firms make interview decisions sequentially and each firm takes the best response action assuming they are the last to act, this process converges to an equilibrium when interview capacities are small. However, we show that the task of computing the best response is difficult if firms have to use its own historical samples to estimate it, while this task becomes trivial if firms have information on the degree of competition for each applicant. Therefore, converging to an equilibrium can be greatly facilitated if firms have information on the level of competition for each applicant.
When Collaborative Filtering is not Collaborative: Unfairness of PCA for Recommendations
Oct 15, 2023



We study the fairness of dimensionality reduction methods for recommendations. We focus on the established method of principal component analysis (PCA), which identifies latent components and produces a low-rank approximation via the leading components while discarding the trailing components. Prior works have defined notions of "fair PCA"; however, these definitions do not answer the following question: what makes PCA unfair? We identify two underlying mechanisms of PCA that induce unfairness at the item level. The first negatively impacts less popular items, due to the fact that less popular items rely on trailing latent components to recover their values. The second negatively impacts the highly popular items, since the leading PCA components specialize in individual popular items instead of capturing similarities between items. To address these issues, we develop a polynomial-time algorithm, Item-Weighted PCA, a modification of PCA that uses item-specific weights in the objective. On a stylized class of matrices, we prove that Item-Weighted PCA using a specific set of weights minimizes a popularity-normalized error metric. Our evaluations on real-world datasets show that Item-Weighted PCA not only improves overall recommendation quality by up to $0.1$ item-level AUC-ROC but also improves on both popular and less popular items.
Policy Optimization for Personalized Interventions in Behavioral Health
Mar 21, 2023



Problem definition: Behavioral health interventions, delivered through digital platforms, have the potential to significantly improve health outcomes, through education, motivation, reminders, and outreach. We study the problem of optimizing personalized interventions for patients to maximize some long-term outcome, in a setting where interventions are costly and capacity-constrained. Methodology/results: This paper provides a model-free approach to solving this problem. We find that generic model-free approaches from the reinforcement learning literature are too data intensive for healthcare applications, while simpler bandit approaches make progress at the expense of ignoring long-term patient dynamics. We present a new algorithm we dub DecompPI that approximates one step of policy iteration. Implementing DecompPI simply consists of a prediction task from offline data, alleviating the need for online experimentation. Theoretically, we show that under a natural set of structural assumptions on patient dynamics, DecompPI surprisingly recovers at least 1/2 of the improvement possible between a naive baseline policy and the optimal policy. At the same time, DecompPI is both robust to estimation errors and interpretable. Through an empirical case study on a mobile health platform for improving treatment adherence for tuberculosis, we find that DecompPI can provide the same efficacy as the status quo with approximately half the capacity of interventions. Managerial implications: DecompPI is general and is easily implementable for organizations aiming to improve long-term behavior through targeted interventions. Our case study suggests that the platform's costs of deploying interventions can potentially be cut by 50%, which facilitates the ability to scale up the system in a cost-efficient fashion.
Fair Exploration via Axiomatic Bargaining
Jun 04, 2021
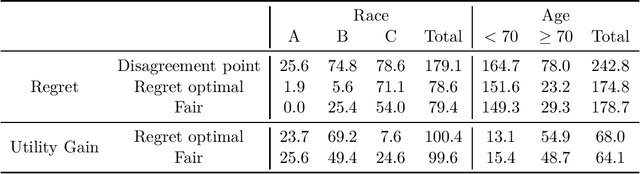
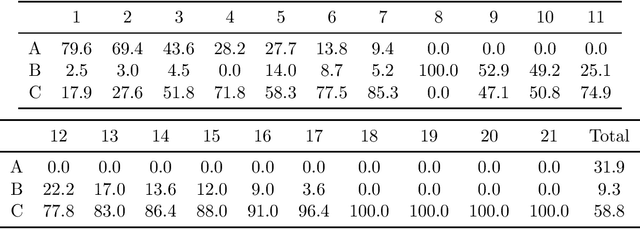
Motivated by the consideration of fairly sharing the cost of exploration between multiple groups in learning problems, we develop the Nash bargaining solution in the context of multi-armed bandits. Specifically, the 'grouped' bandit associated with any multi-armed bandit problem associates, with each time step, a single group from some finite set of groups. The utility gained by a given group under some learning policy is naturally viewed as the reduction in that group's regret relative to the regret that group would have incurred 'on its own'. We derive policies that yield the Nash bargaining solution relative to the set of incremental utilities possible under any policy. We show that on the one hand, the 'price of fairness' under such policies is limited, while on the other hand, regret optimal policies are arbitrarily unfair under generic conditions. Our theoretical development is complemented by a case study on contextual bandits for warfarin dosing where we are concerned with the cost of exploration across multiple races and age groups.
The Limits to Learning an SIR Process: Granular Forecasting for Covid-19
Jun 11, 2020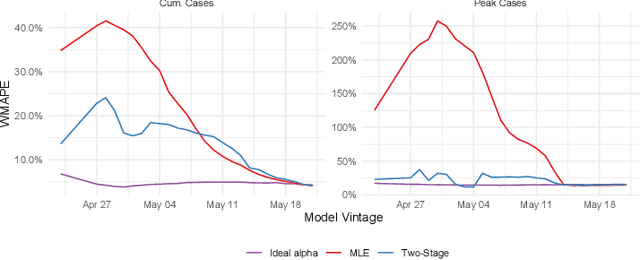
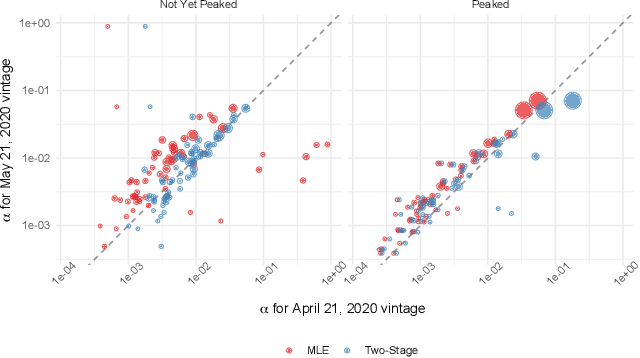
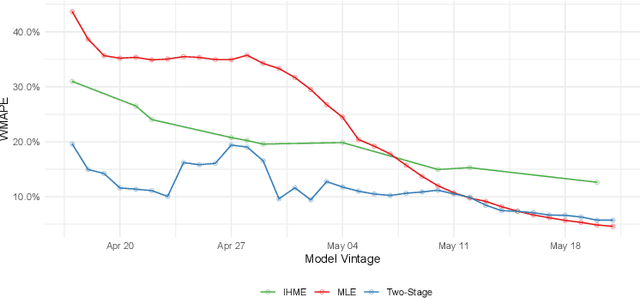
A multitude of forecasting efforts have arisen to support management of the ongoing COVID-19 epidemic. These efforts typically rely on a variant of the SIR process and have illustrated that building effective forecasts for an epidemic in its early stages is challenging. This is perhaps surprising since these models rely on a small number of parameters and typically provide an excellent retrospective fit to the evolution of a disease. So motivated, we provide an analysis of the limits to estimating an SIR process. We show that no unbiased estimator can hope to learn this process until observing enough of the epidemic so that one is approximately two-thirds of the way to reaching the peak for new infections. Our analysis provides insight into a regularization strategy that permits effective learning across simultaneously and asynchronously evolving epidemics. This strategy has been used to produce accurate, granular predictions for the COVID-19 epidemic that has found large-scale practical application in a large US state.
TS-UCB: Improving on Thompson Sampling With Little to No Additional Computation
Jun 11, 2020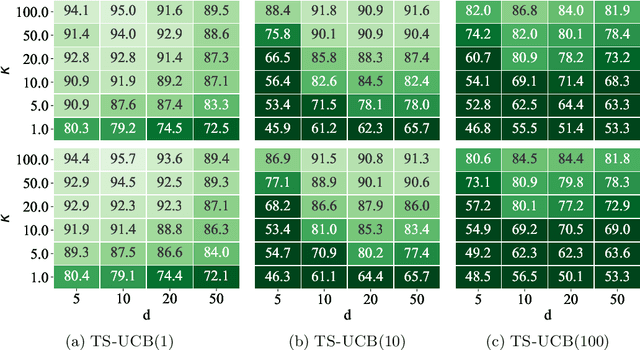
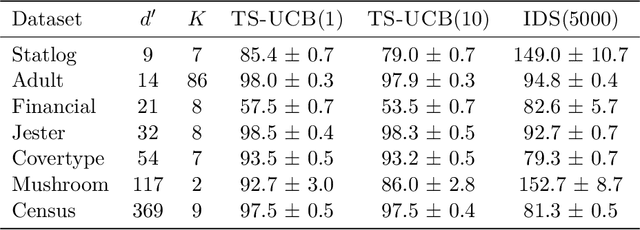
Thompson sampling has become a ubiquitous approach to online decision problems with bandit feedback. The key algorithmic task for Thompson sampling is drawing a sample from the posterior of the optimal action. We propose an alternative arm selection rule we dub TS-UCB, that requires negligible additional computational effort but provides significant performance improvements relative to Thompson sampling. At each step, TS-UCB computes a score for each arm using two ingredients: posterior sample(s) and upper confidence bounds. TS-UCB can be used in any setting where these two quantities are available, and it is flexible in the number of posterior samples it takes as input. This proves particularly valuable in heuristics for deep contextual bandits: we show that TS-UCB achieves materially lower regret on all problem instances in a deep bandit suite proposed in Riquelme et al. (2018). Finally, from a theoretical perspective, we establish optimal regret guarantees for TS-UCB for both the K-armed and linear bandit models.