 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScheduling with Uncertain Holding Costs and its Application to Content Moderation
May 27, 2025



In content moderation for social media platforms, the cost of delaying the review of a content is proportional to its view trajectory, which fluctuates and is apriori unknown. Motivated by such uncertain holding costs, we consider a queueing model where job states evolve based on a Markov chain with state-dependent instantaneous holding costs. We demonstrate that in the presence of such uncertain holding costs, the two canonical algorithmic principles, instantaneous-cost ($c\mu$-rule) and expected-remaining-cost ($c\mu/\theta$-rule), are suboptimal. By viewing each job as a Markovian ski-rental problem, we develop a new index-based algorithm, Opportunity-adjusted Remaining Cost (OaRC), that adjusts to the opportunity of serving jobs in the future when uncertainty partly resolves. We show that the regret of OaRC scales as $\tilde{O}(L^{1.5}\sqrt{N})$, where $L$ is the maximum length of a job's holding cost trajectory and $N$ is the system size. This regret bound shows that OaRC achieves asymptotic optimality when the system size $N$ scales to infinity. Moreover, its regret is independent of the state-space size, which is a desirable property when job states contain contextual information. We corroborate our results with an extensive simulation study based on two holding cost patterns (online ads and user-generated content) that arise in content moderation for social media platforms. Our simulations based on synthetic and real datasets demonstrate that OaRC consistently outperforms existing practice, which is based on the two canonical algorithmic principles.
Bandits for Online Calibration: An Application to Content Moderation on Social Media Platforms
Nov 11, 2022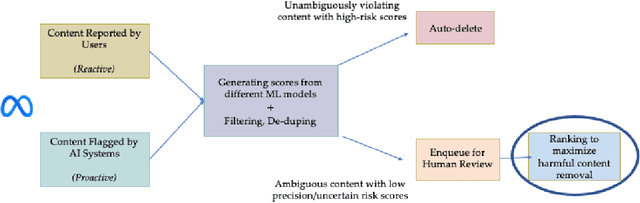
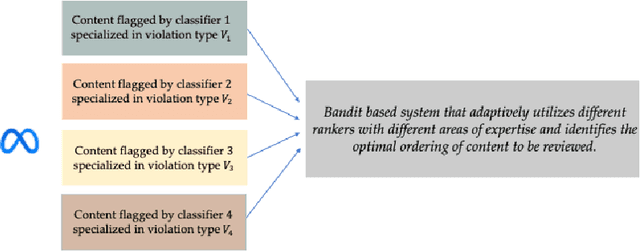
We describe the current content moderation strategy employed by Meta to remove policy-violating content from its platforms. Meta relies on both handcrafted and learned risk models to flag potentially violating content for human review. Our approach aggregates these risk models into a single ranking score, calibrating them to prioritize more reliable risk models. A key challenge is that violation trends change over time, affecting which risk models are most reliable. Our system additionally handles production challenges such as changing risk models and novel risk models. We use a contextual bandit to update the calibration in response to such trends. Our approach increases Meta's top-line metric for measuring the effectiveness of its content moderation strategy by 13%.
Optimizing Offer Sets in Sub-Linear Time
Nov 17, 2020

Personalization and recommendations are now accepted as core competencies in just about every online setting, ranging from media platforms to e-commerce to social networks. While the challenge of estimating user preferences has garnered significant attention, the operational problem of using such preferences to construct personalized offer sets to users is still a challenge, particularly in modern settings where a massive number of items and a millisecond response time requirement mean that even enumerating all of the items is impossible. Faced with such settings, existing techniques are either (a) entirely heuristic with no principled justification, or (b) theoretically sound, but simply too slow to work. Thus motivated, we propose an algorithm for personalized offer set optimization that runs in time sub-linear in the number of items while enjoying a uniform performance guarantee. Our algorithm works for an extremely general class of problems and models of user choice that includes the mixed multinomial logit model as a special case. We achieve a sub-linear runtime by leveraging the dimensionality reduction from learning an accurate latent factor model, along with existing sub-linear time approximate near neighbor algorithms. Our algorithm can be entirely data-driven, relying on samples of the user, where a `sample' refers to the user interaction data typically collected by firms. We evaluate our approach on a massive content discovery dataset from Outbrain that includes millions of advertisements. Results show that our implementation indeed runs fast and with increased performance relative to existing fast heuristics.
Multi-armed Bandits with Cost Subsidy
Nov 13, 2020

In this paper, we consider a novel variant of the multi-armed bandit (MAB) problem, MAB with cost subsidy, which models many real-life applications where the learning agent has to pay to select an arm and is concerned about optimizing cumulative costs and rewards. We present two applications, intelligent SMS routing problem and ad audience optimization problem faced by a number of businesses (especially online platforms) and show how our problem uniquely captures key features of these applications. We show that naive generalizations of existing MAB algorithms like Upper Confidence Bound and Thompson Sampling do not perform well for this problem. We then establish fundamental lower bound of $\Omega(K^{1/3} T^{2/3})$ on the performance of any online learning algorithm for this problem, highlighting the hardness of our problem in comparison to the classical MAB problem (where $T$ is the time horizon and $K$ is the number of arms). We also present a simple variant of explore-then-commit and establish near-optimal regret bounds for this algorithm. Lastly, we perform extensive numerical simulations to understand the behavior of a suite of algorithms for various instances and recommend a practical guide to employ different algorithms.
Multi-Purchase Behavior: Modeling and Optimization
Jun 14, 2020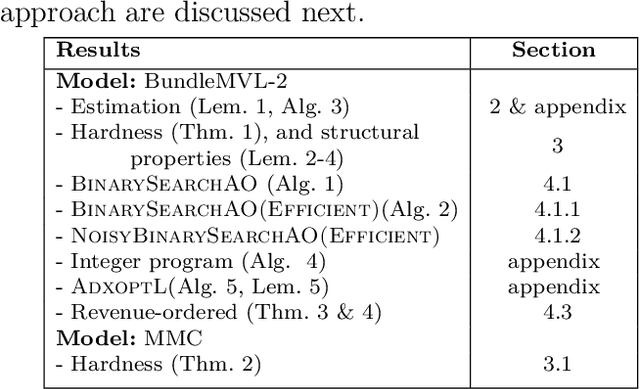
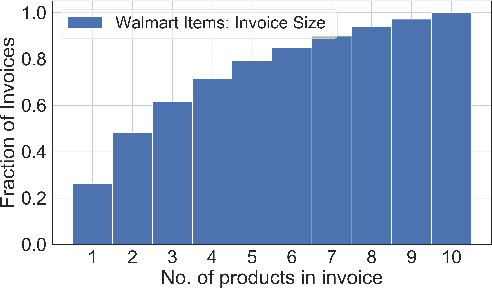

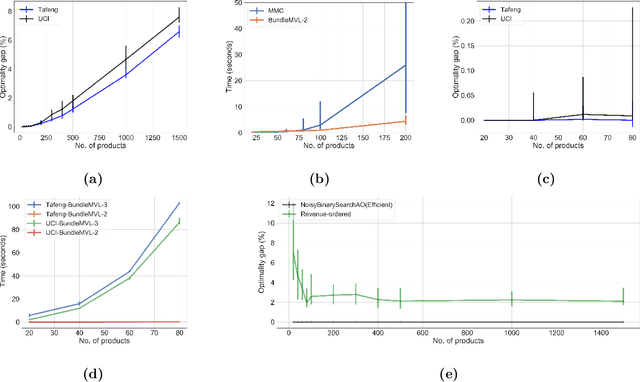
We study the problem of modeling purchase of multiple items and utilizing it to display optimized recommendations, which is a central problem for online e-commerce platforms. Rich personalized modeling of users and fast computation of optimal products to display given these models can lead to significantly higher revenues and simultaneously enhance the end user experience. We present a parsimonious multi-purchase family of choice models called the BundleMVL-K family, and develop a binary search based iterative strategy that efficiently computes optimized recommendations for this model. This is one of the first attempts at operationalizing multi-purchase class of choice models. We characterize structural properties of the optimal solution, which allow one to decide if a product is part of the optimal assortment in constant time, reducing the size of the instance that needs to be solved computationally. We also establish the hardness of computing optimal recommendation sets. We show one of the first quantitative links between modeling multiple purchase behavior and revenue gains. The efficacy of our modeling and optimization techniques compared to competing solutions is shown using several real world datasets on multiple metrics such as model fitness, expected revenue gains and run-time reductions. The benefit of taking multiple purchases into account is observed to be $6-8\%$ in relative terms for the Ta Feng and UCI shopping datasets when compared to the MNL model for instances with $\sim 1500$ products. Additionally, across $8$ real world datasets, the test log-likelihood fits of our models are on average $17\%$ better in relative terms. The simplicity of our models and the iterative nature of our optimization technique allows practitioners meet stringent computational constraints while increasing their revenues in practical recommendation applications at scale.
The Limits to Learning an SIR Process: Granular Forecasting for Covid-19
Jun 11, 2020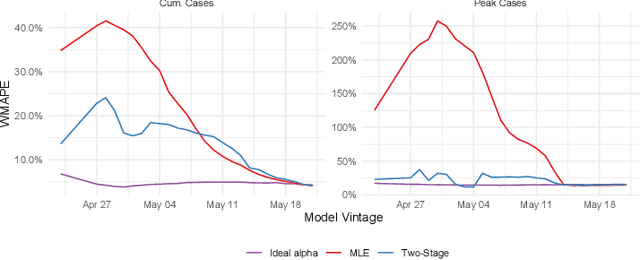
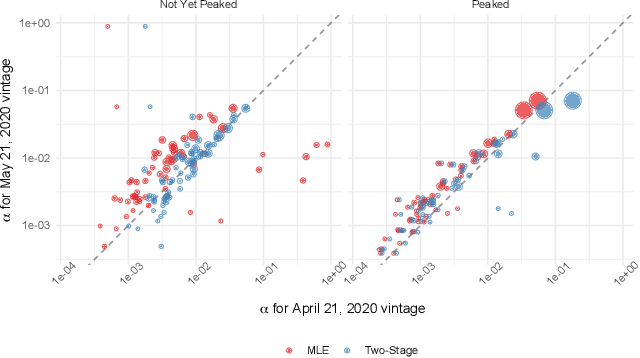
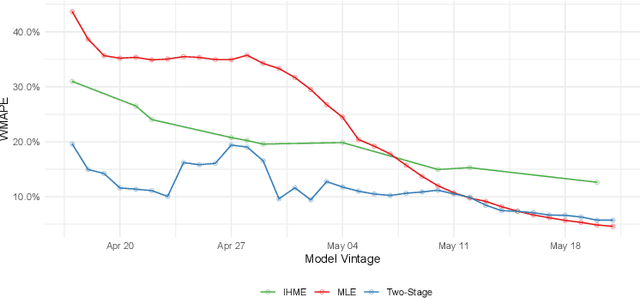
A multitude of forecasting efforts have arisen to support management of the ongoing COVID-19 epidemic. These efforts typically rely on a variant of the SIR process and have illustrated that building effective forecasts for an epidemic in its early stages is challenging. This is perhaps surprising since these models rely on a small number of parameters and typically provide an excellent retrospective fit to the evolution of a disease. So motivated, we provide an analysis of the limits to estimating an SIR process. We show that no unbiased estimator can hope to learn this process until observing enough of the epidemic so that one is approximately two-thirds of the way to reaching the peak for new infections. Our analysis provides insight into a regularization strategy that permits effective learning across simultaneously and asynchronously evolving epidemics. This strategy has been used to produce accurate, granular predictions for the COVID-19 epidemic that has found large-scale practical application in a large US state.
Optimizing Revenue while showing Relevant Assortments at Scale
Mar 06, 2020
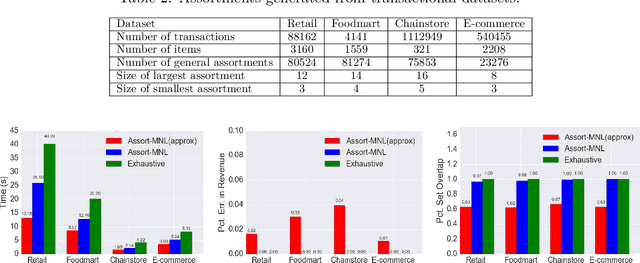
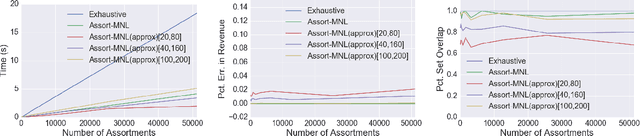
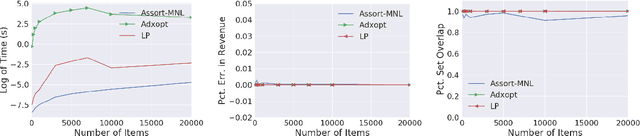
Scalable real-time assortment optimization has become essential in e-commerce operations due to the need for personalization and the availability of a large variety of items. While this can be done when there are simplistic assortment choices to be made, imposing constraints on the collection of feasible assortments gives more flexibility to incorporate insights of store-managers and historically well-performing assortments. We design fast and flexible algorithms based on variations of binary search that find the revenue of the (approximately) optimal assortment. In particular, we revisit the problem of large-scale assortment optimization under the multinomial logit choice model without any assumptions on the structure of the feasible assortments. We speed up the comparisons steps using novel vector space embeddings, based on advances in the fields of information retrieval and machine learning. For an arbitrary collection of assortments, our algorithms can find a solution in time that is sub-linear in the number of assortments and for the simpler case of cardinality constraints - linear in the number of items (existing methods are quadratic or worse). Empirical validations using the Billion Prices dataset and several retail transaction datasets show that our algorithms are competitive even when the number of items is $\sim 10^5$ ($100$x larger instances than previously studied).