 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information-Theoretic Definition for Open-Ended Learning
Jun 06, 2026A growing body of work points to the great promise of AI systems that can continually expand their capabilities as they operate in an open-ended environment. But yet there is no coherent definition of open-endedness or theory about how an agent ought to explore an open-ended environment. We introduce an information-theoretic definition based on a new concept -- the ${\textit bit-equivalent}$ -- which quantifies the information required to attain each level of expected reward. We consider an environment to be open-ended if an agent can attain linear growth in the bit-equivalent. We establish that classical bandit environments are not open-ended and formulate a bandit environment that is. We also introduce an algorithm that achieves open-ended learning in this environment.
On Aligning Prediction Models with Clinical Experiential Learning: A Prostate Cancer Case Study
Sep 04, 2025



Over the past decade, the use of machine learning (ML) models in healthcare applications has rapidly increased. Despite high performance, modern ML models do not always capture patterns the end user requires. For example, a model may predict a non-monotonically decreasing relationship between cancer stage and survival, keeping all other features fixed. In this paper, we present a reproducible framework for investigating this misalignment between model behavior and clinical experiential learning, focusing on the effects of underspecification of modern ML pipelines. In a prostate cancer outcome prediction case study, we first identify and address these inconsistencies by incorporating clinical knowledge, collected by a survey, via constraints into the ML model, and subsequently analyze the impact on model performance and behavior across degrees of underspecification. The approach shows that aligning the ML model with clinical experiential learning is possible without compromising performance. Motivated by recent literature in generative AI, we further examine the feasibility of a feedback-driven alignment approach in non-generative AI clinical risk prediction models through a randomized experiment with clinicians. Our findings illustrate that, by eliciting clinicians' model preferences using our proposed methodology, the larger the difference in how the constrained and unconstrained models make predictions for a patient, the more apparent the difference is in clinical interpretation.
Provably Learning from Language Feedback
Jun 12, 2025Interactively learning from observation and language feedback is an increasingly studied area driven by the emergence of large language model (LLM) agents. While impressive empirical demonstrations have been shown, so far a principled framing of these decision problems remains lacking. In this paper, we formalize the Learning from Language Feedback (LLF) problem, assert sufficient assumptions to enable learning despite latent rewards, and introduce $\textit{transfer eluder dimension}$ as a complexity measure to characterize the hardness of LLF problems. We show that transfer eluder dimension captures the intuition that information in the feedback changes the learning complexity of the LLF problem. We demonstrate cases where learning from rich language feedback can be exponentially faster than learning from reward. We develop a no-regret algorithm, called $\texttt{HELiX}$, that provably solves LLF problems through sequential interactions, with performance guarantees that scale with the transfer eluder dimension of the problem. Across several empirical domains, we show that $\texttt{HELiX}$ performs well even when repeatedly prompting LLMs does not work reliably. Our contributions mark a first step towards designing principled interactive learning algorithms from generic language feedback.
Exploration Unbound
Jul 16, 2024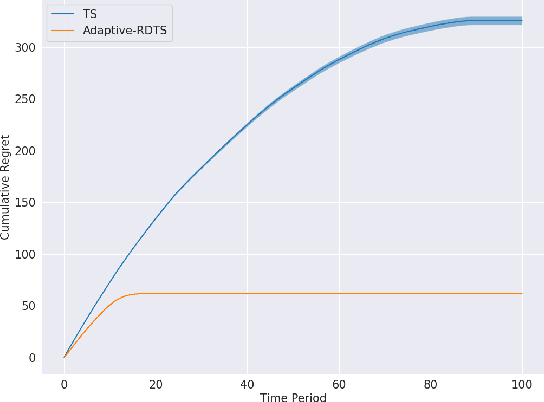
A sequential decision-making agent balances between exploring to gain new knowledge about an environment and exploiting current knowledge to maximize immediate reward. For environments studied in the traditional literature, optimal decisions gravitate over time toward exploitation as the agent accumulates sufficient knowledge and the benefits of further exploration vanish. What if, however, the environment offers an unlimited amount of useful knowledge and there is large benefit to further exploration no matter how much the agent has learned? We offer a simple, quintessential example of such a complex environment. In this environment, rewards are unbounded and an agent can always increase the rate at which rewards accumulate by exploring to learn more. Consequently, an optimal agent forever maintains a propensity to explore.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
RLHF and IIA: Perverse Incentives
Dec 02, 2023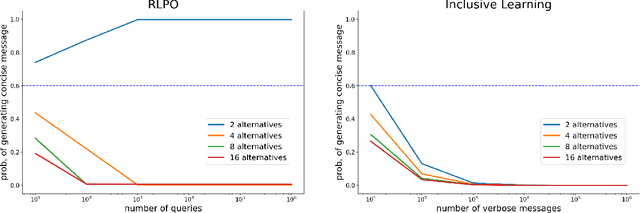
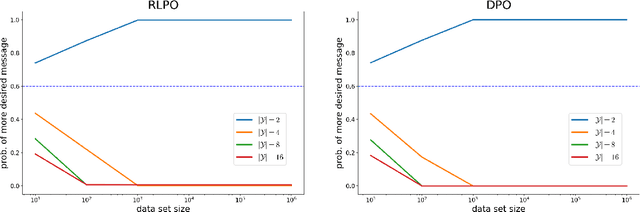
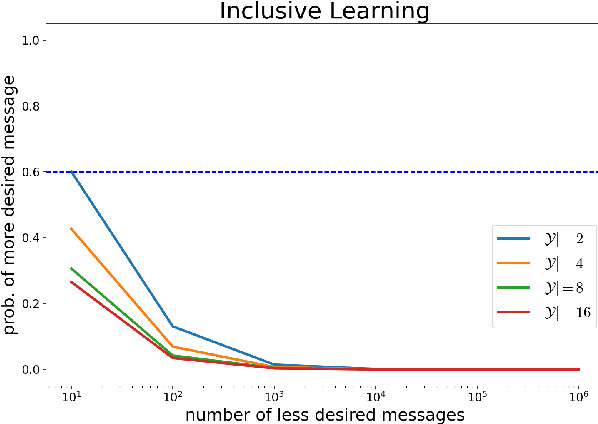
Existing algorithms for reinforcement learning from human feedback (RLHF) can incentivize responses at odds with preferences because they are based on models that assume independence of irrelevant alternatives (IIA). The perverse incentives induced by IIA give rise to egregious behavior when innovating on query formats or learning algorithms.
Shattering the Agent-Environment Interface for Fine-Tuning Inclusive Language Models
May 19, 2023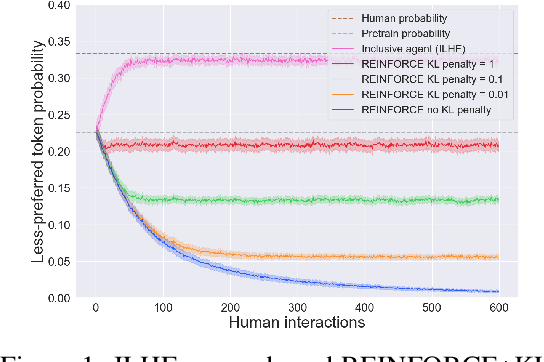

A centerpiece of the ever-popular reinforcement learning from human feedback (RLHF) approach to fine-tuning autoregressive language models is the explicit training of a reward model to emulate human feedback, distinct from the language model itself. This reward model is then coupled with policy-gradient methods to dramatically improve the alignment between language model outputs and desired responses. In this work, we adopt a novel perspective wherein a pre-trained language model is itself simultaneously a policy, reward function, and transition function. An immediate consequence of this is that reward learning and language model fine-tuning can be performed jointly and directly, without requiring any further downstream policy optimization. While this perspective does indeed break the traditional agent-environment interface, we nevertheless maintain that there can be enormous statistical benefits afforded by bringing to bear traditional algorithmic concepts from reinforcement learning. Our experiments demonstrate one concrete instance of this through efficient exploration based on the representation and resolution of epistemic uncertainty. In order to illustrate these ideas in a transparent manner, we restrict attention to a simple didactic data generating process and leave for future work extension to systems of practical scale.
Posterior Sampling for Continuing Environments
Nov 29, 2022We develop an extension of posterior sampling for reinforcement learning (PSRL) that is suited for a continuing agent-environment interface and integrates naturally into agent designs that scale to complex environments. The approach maintains a statistically plausible model of the environment and follows a policy that maximizes expected $\gamma$-discounted return in that model. At each time, with probability $1-\gamma$, the model is replaced by a sample from the posterior distribution over environments. For a suitable schedule of $\gamma$, we establish an $\tilde{O}(\tau S \sqrt{A T})$ bound on the Bayesian regret, where $S$ is the number of environment states, $A$ is the number of actions, and $\tau$ denotes the reward averaging time, which is a bound on the duration required to accurately estimate the average reward of any policy.
Safely Bridging Offline and Online Reinforcement Learning
Oct 25, 2021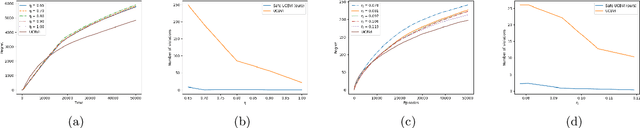
A key challenge to deploying reinforcement learning in practice is exploring safely. We propose a natural safety property -- \textit{uniformly} outperforming a conservative policy (adaptively estimated from all data observed thus far), up to a per-episode exploration budget. We then design an algorithm that uses a UCB reinforcement learning policy for exploration, but overrides it as needed to ensure safety with high probability. We experimentally validate our results on a sepsis treatment task, demonstrating that our algorithm can learn while ensuring good performance compared to the baseline policy for every patient.