 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Machine Learning for Combinatorial Optimization Competition (ML4CO): Results and Insights
Mar 17, 2022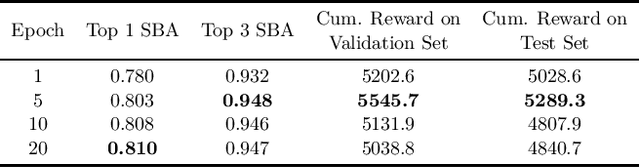

Combinatorial optimization is a well-established area in operations research and computer science. Until recently, its methods have focused on solving problem instances in isolation, ignoring that they often stem from related data distributions in practice. However, recent years have seen a surge of interest in using machine learning as a new approach for solving combinatorial problems, either directly as solvers or by enhancing exact solvers. Based on this context, the ML4CO aims at improving state-of-the-art combinatorial optimization solvers by replacing key heuristic components. The competition featured three challenging tasks: finding the best feasible solution, producing the tightest optimality certificate, and giving an appropriate solver configuration. Three realistic datasets were considered: balanced item placement, workload apportionment, and maritime inventory routing. This last dataset was kept anonymous for the contestants.
Synthetic Design: An Optimization Approach to Experimental Design with Synthetic Controls
Dec 01, 2021
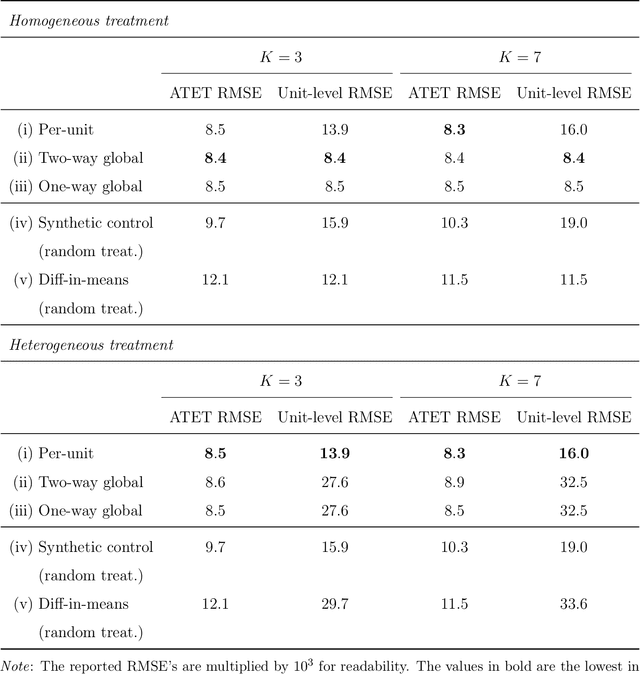
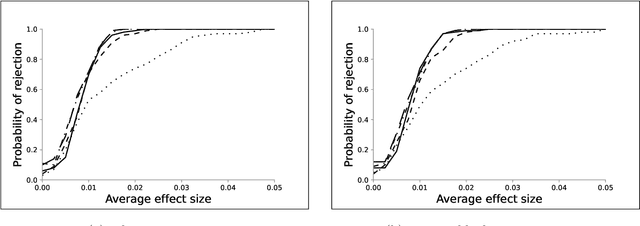
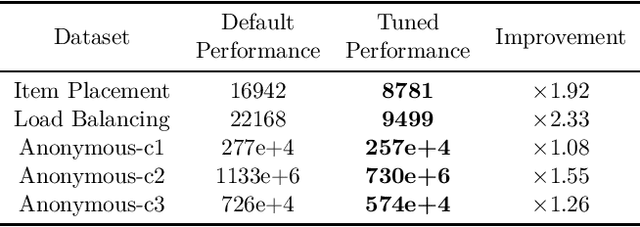
We investigate the optimal design of experimental studies that have pre-treatment outcome data available. The average treatment effect is estimated as the difference between the weighted average outcomes of the treated and control units. A number of commonly used approaches fit this formulation, including the difference-in-means estimator and a variety of synthetic-control techniques. We propose several methods for choosing the set of treated units in conjunction with the weights. Observing the NP-hardness of the problem, we introduce a mixed-integer programming formulation which selects both the treatment and control sets and unit weightings. We prove that these proposed approaches lead to qualitatively different experimental units being selected for treatment. We use simulations based on publicly available data from the US Bureau of Labor Statistics that show improvements in terms of mean squared error and statistical power when compared to simple and commonly used alternatives such as randomized trials.
REGAL: Transfer Learning For Fast Optimization of Computation Graphs
May 30, 2019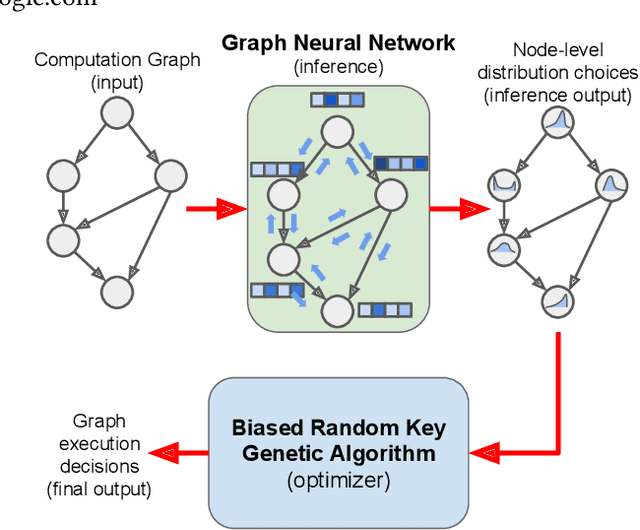
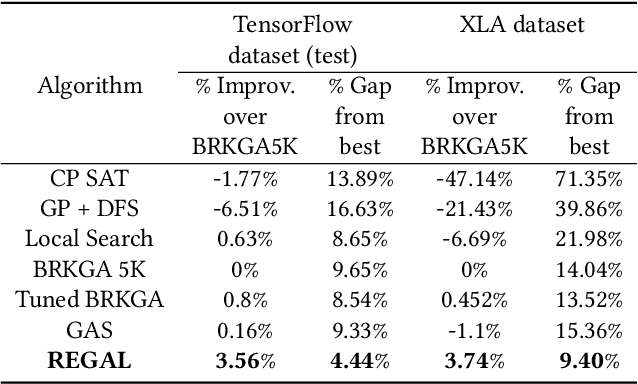
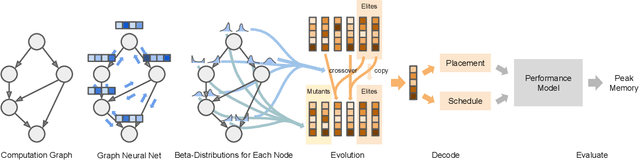
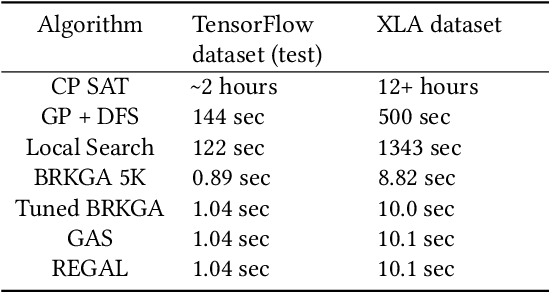
We present a deep reinforcement learning approach to optimizing the execution cost of computation graphs in a static compiler. The key idea is to combine a neural network policy with a genetic algorithm, the Biased Random-Key Genetic Algorithm (BRKGA). The policy is trained to predict, given an input graph to be optimized, the node-level probability distributions for sampling mutations and crossovers in BRKGA. Our approach, "REINFORCE-based Genetic Algorithm Learning" (REGAL), uses the policy's ability to transfer to new graphs to significantly improve the solution quality of the genetic algorithm for the same objective evaluation budget. As a concrete application, we show results for minimizing peak memory in TensorFlow graphs by jointly optimizing device placement and scheduling. REGAL achieves on average 3.56% lower peak memory than BRKGA on previously unseen graphs, outperforming all the algorithms we compare to, and giving 4.4x bigger improvement than the next best algorithm. We also evaluate REGAL on a production compiler team's performance benchmark of XLA graphs and achieve on average 3.74% lower peak memory than BRKGA, again outperforming all others. Our approach and analysis is made possible by collecting a dataset of 372 unique real-world TensorFlow graphs, more than an order of magnitude more data than previous work.