 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpacking the Black Box: Regulating Algorithmic Decisions
Paper and Code
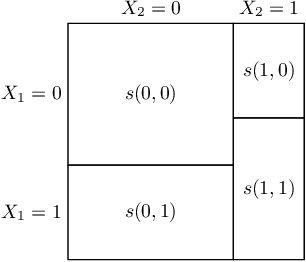
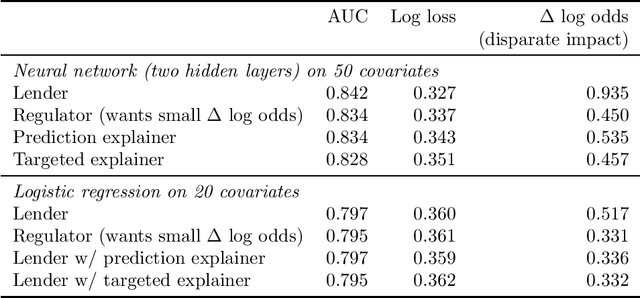
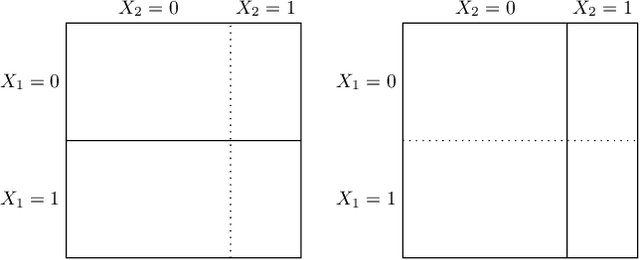
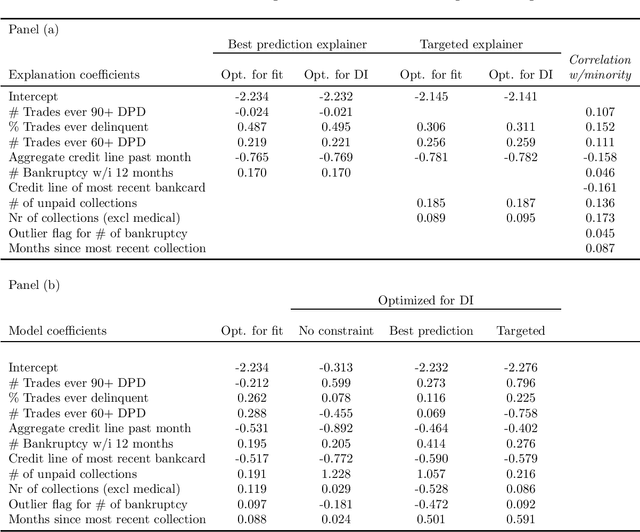
We characterize optimal oversight of algorithms in a world where an agent designs a complex prediction function but a principal is limited in the amount of information she can learn about the prediction function. We show that limiting agents to prediction functions that are simple enough to be fully transparent is inefficient as long as the bias induced by misalignment between principal's and agent's preferences is small relative to the uncertainty about the true state of the world. Algorithmic audits can improve welfare, but the gains depend on the design of the audit tools. Tools that focus on minimizing overall information loss, the focus of many post-hoc explainer tools, will generally be inefficient since they focus on explaining the average behavior of the prediction function rather than sources of mis-prediction, which matter for welfare-relevant outcomes. Targeted tools that focus on the source of incentive misalignment, e.g., excess false positives or racial disparities, can provide first-best solutions. We provide empirical support for our theoretical findings using an application in consumer lending.