 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble and Single Descent in Causal Inference with an Application to High-Dimensional Synthetic Control
Paper and Code
May 01, 2023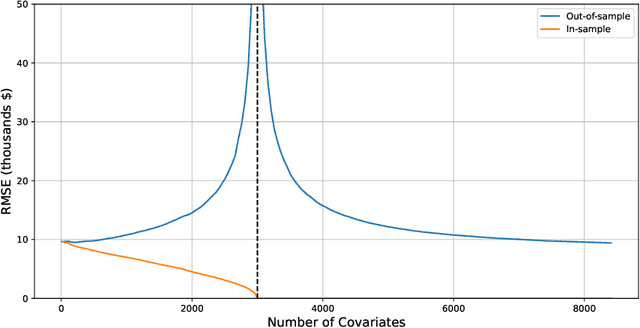
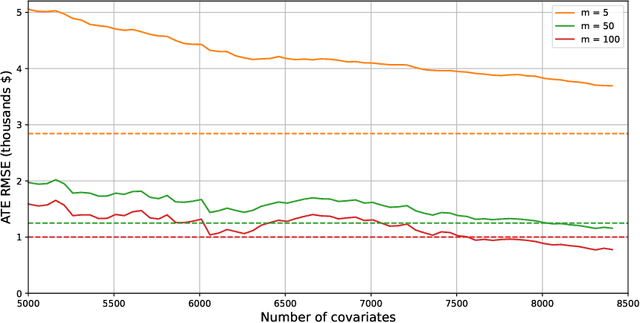
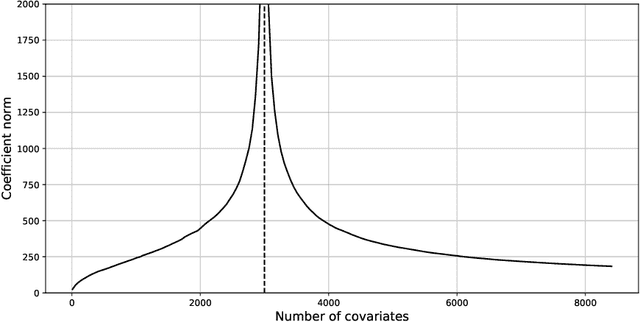
Motivated by a recent literature on the double-descent phenomenon in machine learning, we consider highly over-parametrized models in causal inference, including synthetic control with many control units. In such models, there may be so many free parameters that the model fits the training data perfectly. As a motivating example, we first investigate high-dimensional linear regression for imputing wage data, where we find that models with many more covariates than sample size can outperform simple ones. As our main contribution, we document the performance of high-dimensional synthetic control estimators with many control units. We find that adding control units can help improve imputation performance even beyond the point where the pre-treatment fit is perfect. We then provide a unified theoretical perspective on the performance of these high-dimensional models. Specifically, we show that more complex models can be interpreted as model-averaging estimators over simpler ones, which we link to an improvement in average performance. This perspective yields concrete insights into the use of synthetic control when control units are many relative to the number of pre-treatment periods.