 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence-Based Policy Learning
Paper and Code
Mar 12, 2021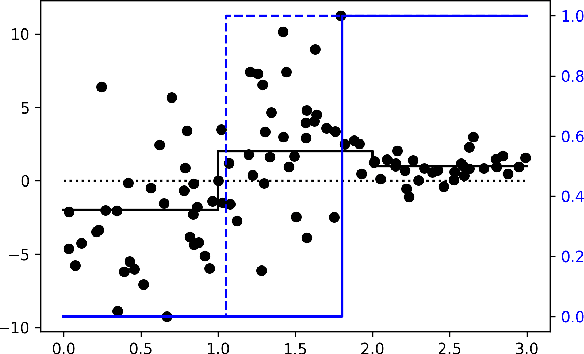
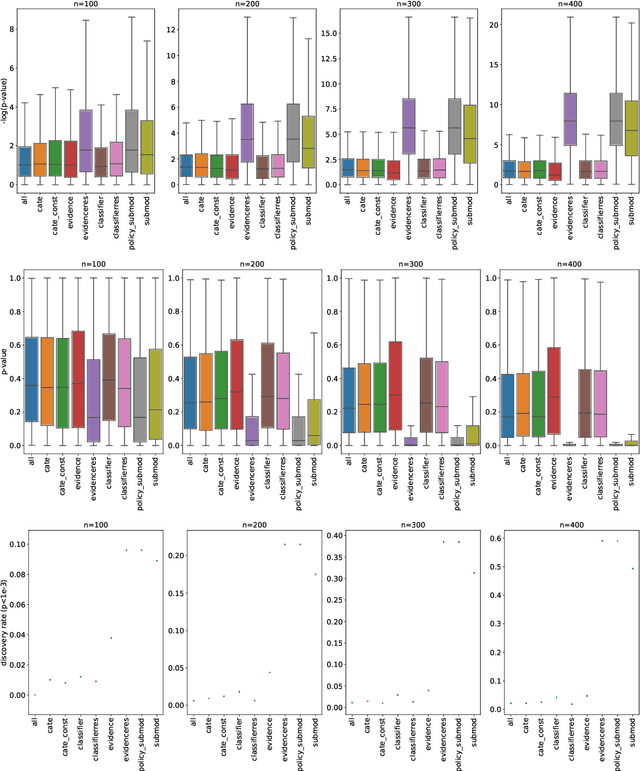
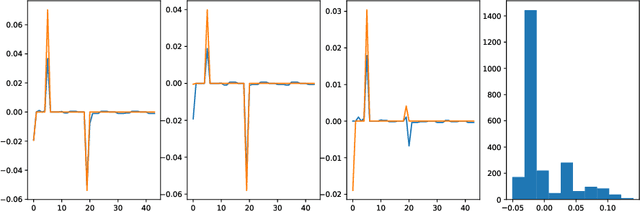
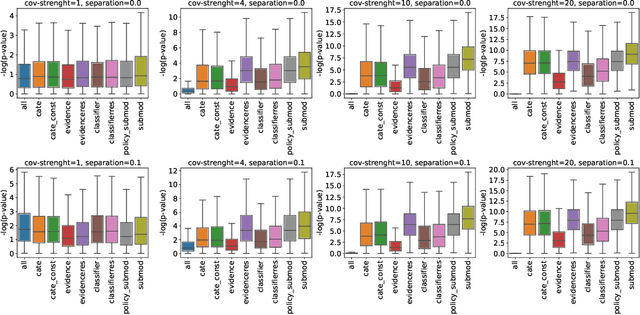
The past years have seen seen the development and deployment of machine-learning algorithms to estimate personalized treatment-assignment policies from randomized controlled trials. Yet such algorithms for the assignment of treatment typically optimize expected outcomes without taking into account that treatment assignments are frequently subject to hypothesis testing. In this article, we explicitly take significance testing of the effect of treatment-assignment policies into account, and consider assignments that optimize the probability of finding a subset of individuals with a statistically significant positive treatment effect. We provide an efficient implementation using decision trees, and demonstrate its gain over selecting subsets based on positive (estimated) treatment effects. Compared to standard tree-based regression and classification tools, this approach tends to yield substantially higher power in detecting subgroups with positive treatment effects.