 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Inference-Time Steering of Protein Diffusion Models via Embedding Optimization
Feb 05, 2026In many biophysical inverse problems, the goal is to generate biomolecular conformations that are both physically plausible and consistent with experimental measurements. As recent sequence-to-structure diffusion models provide powerful data-driven priors, posterior sampling has emerged as a popular framework by guiding atomic coordinates to target conformations using experimental likelihoods. However, when the target lies in a low-density region of the prior, posterior sampling requires aggressive and brittle weighting of the likelihood guidance. Motivated by this limitation, we propose EmbedOpt, an alternative inference-time approach for steering diffusion models to optimize experimental likelihoods in the conditional embedding space. As this space encodes rich sequence and coevolutionary signals, optimizing over it effectively shifts the diffusion prior to align with experimental constraints. We validate EmbedOpt on two benchmarks simulating cryo-electron microscopy map fitting and experimental distance constraints. We show that EmbedOpt outperforms the coordinate-based posterior sampling method in map fitting tasks, matches performance on distance constraint tasks, and exhibits superior engineering robustness across hyperparameters spanning two orders of magnitude. Moreover, its smooth optimization behavior enables a significant reduction in the number of diffusion steps required for inference, leading to better efficiency.
Posterior Uncertainty Quantification in Neural Networks using Data Augmentation
Mar 18, 2024



In this paper, we approach the problem of uncertainty quantification in deep learning through a predictive framework, which captures uncertainty in model parameters by specifying our assumptions about the predictive distribution of unseen future data. Under this view, we show that deep ensembling (Lakshminarayanan et al., 2017) is a fundamentally mis-specified model class, since it assumes that future data are supported on existing observations only -- a situation rarely encountered in practice. To address this limitation, we propose MixupMP, a method that constructs a more realistic predictive distribution using popular data augmentation techniques. MixupMP operates as a drop-in replacement for deep ensembles, where each ensemble member is trained on a random simulation from this predictive distribution. Grounded in the recently-proposed framework of Martingale posteriors (Fong et al., 2023), MixupMP returns samples from an implicitly defined Bayesian posterior. Our empirical analysis showcases that MixupMP achieves superior predictive performance and uncertainty quantification on various image classification datasets, when compared with existing Bayesian and non-Bayesian approaches.
Practical and Asymptotically Exact Conditional Sampling in Diffusion Models
Jun 30, 2023Diffusion models have been successful on a range of conditional generation tasks including molecular design and text-to-image generation. However, these achievements have primarily depended on task-specific conditional training or error-prone heuristic approximations. Ideally, a conditional generation method should provide exact samples for a broad range of conditional distributions without requiring task-specific training. To this end, we introduce the Twisted Diffusion Sampler, or TDS. TDS is a sequential Monte Carlo (SMC) algorithm that targets the conditional distributions of diffusion models. The main idea is to use twisting, an SMC technique that enjoys good computational efficiency, to incorporate heuristic approximations without compromising asymptotic exactness. We first find in simulation and on MNIST image inpainting and class-conditional generation tasks that TDS provides a computational statistical trade-off, yielding more accurate approximations with many particles but with empirical improvements over heuristics with as few as two particles. We then turn to motif-scaffolding, a core task in protein design, using a TDS extension to Riemannian diffusion models. On benchmark test cases, TDS allows flexible conditioning criteria and often outperforms the state of the art.
Denoising Deep Generative Models
Dec 05, 2022

Likelihood-based deep generative models have recently been shown to exhibit pathological behaviour under the manifold hypothesis as a consequence of using high-dimensional densities to model data with low-dimensional structure. In this paper we propose two methodologies aimed at addressing this problem. Both are based on adding Gaussian noise to the data to remove the dimensionality mismatch during training, and both provide a denoising mechanism whose goal is to sample from the model as though no noise had been added to the data. Our first approach is based on Tweedie's formula, and the second on models which take the variance of added noise as a conditional input. We show that surprisingly, while well motivated, these approaches only sporadically improve performance over not adding noise, and that other methods of addressing the dimensionality mismatch are more empirically adequate.
Variational Nearest Neighbor Gaussian Processes
Feb 03, 2022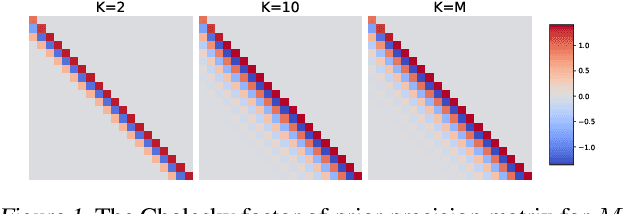



Variational approximations to Gaussian processes (GPs) typically use a small set of inducing points to form a low-rank approximation to the covariance matrix. In this work, we instead exploit a sparse approximation of the precision matrix. We propose variational nearest neighbor Gaussian process (VNNGP), which introduces a prior that only retains correlations within K nearest-neighboring observations, thereby inducing sparse precision structure. Using the variational framework, VNNGP's objective can be factorized over both observations and inducing points, enabling stochastic optimization with a time complexity of O($K^3$). Hence, we can arbitrarily scale the inducing point size, even to the point of putting inducing points at every observed location. We compare VNNGP to other scalable GPs through various experiments, and demonstrate that VNNGP (1) can dramatically outperform low-rank methods, and (2) is less prone to overfitting than other nearest neighbor methods.
Hierarchical Inducing Point Gaussian Process for Inter-domain Observations
Feb 28, 2021
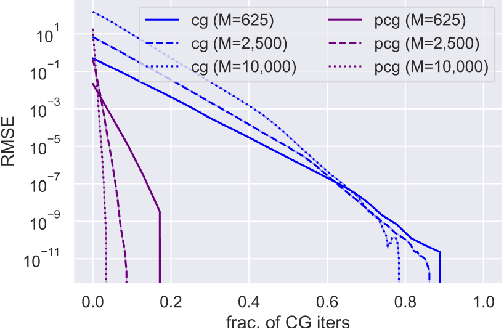
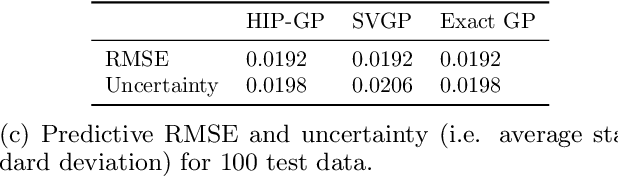
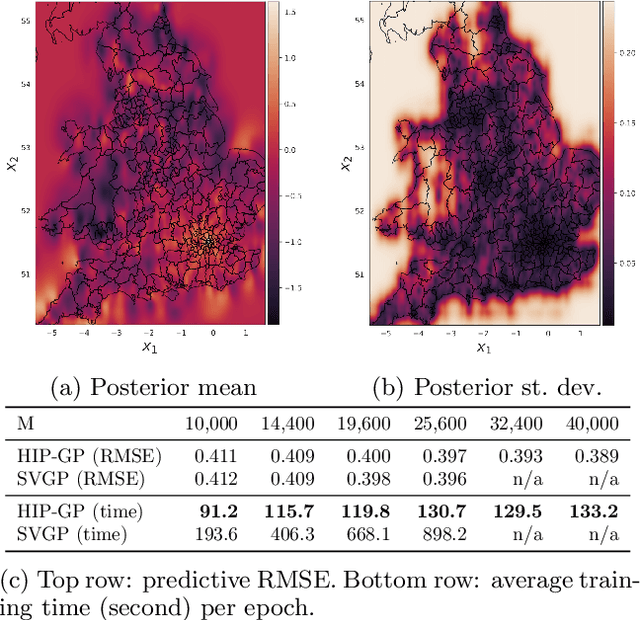
We examine the general problem of inter-domain Gaussian Processes (GPs): problems where the GP realization and the noisy observations of that realization lie on different domains. When the mapping between those domains is linear, such as integration or differentiation, inference is still closed form. However, many of the scaling and approximation techniques that our community has developed do not apply to this setting. In this work, we introduce the hierarchical inducing point GP (HIP-GP), a scalable inter-domain GP inference method that enables us to improve the approximation accuracy by increasing the number of inducing points to the millions. HIP-GP, which relies on inducing points with grid structure and a stationary kernel assumption, is suitable for low-dimensional problems. In developing HIP-GP, we introduce (1) a fast whitening strategy, and (2) a novel preconditioner for conjugate gradients which can be helpful in general GP settings.
Bias-Free Scalable Gaussian Processes via Randomized Truncations
Feb 12, 2021

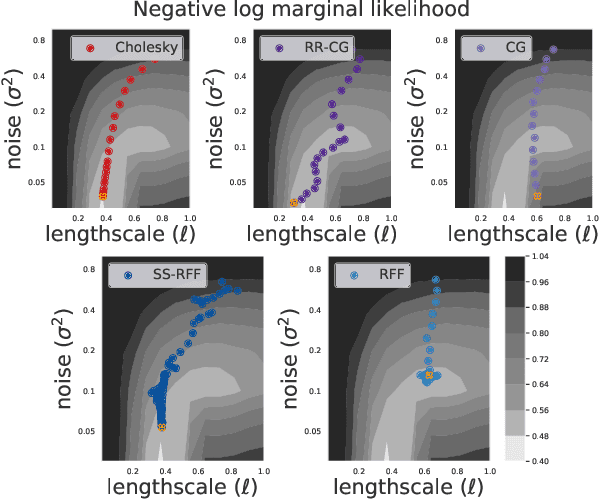
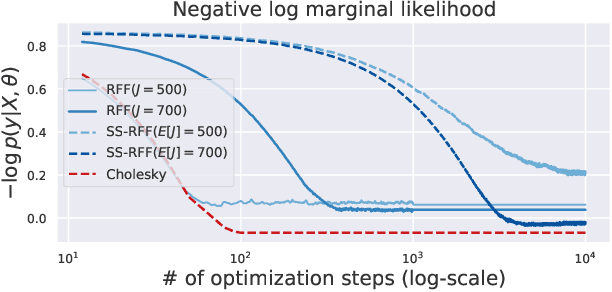
Scalable Gaussian Process methods are computationally attractive, yet introduce modeling biases that require rigorous study. This paper analyzes two common techniques: early truncated conjugate gradients (CG) and random Fourier features (RFF). We find that both methods introduce a systematic bias on the learned hyperparameters: CG tends to underfit while RFF tends to overfit. We address these issues using randomized truncation estimators that eliminate bias in exchange for increased variance. In the case of RFF, we show that the bias-to-variance conversion is indeed a trade-off: the additional variance proves detrimental to optimization. However, in the case of CG, our unbiased learning procedure meaningfully outperforms its biased counterpart with minimal additional computation.
Particle Smoothing Variational Objectives
Sep 20, 2019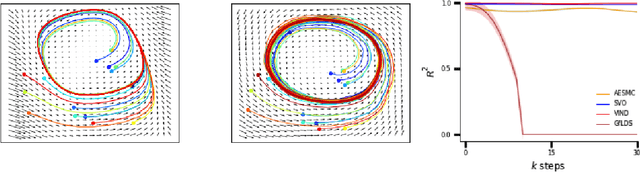
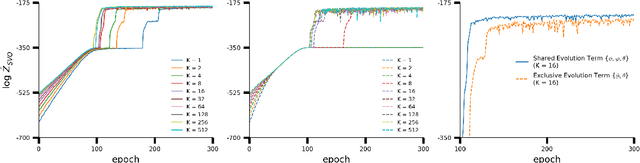
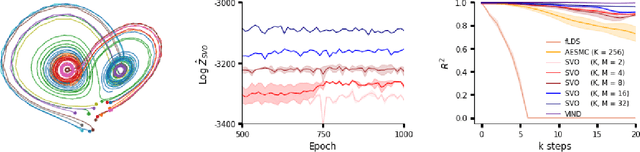

A body of recent work has focused on constructing a variational family of filtered distributions using Sequential Monte Carlo (SMC). Inspired by this work, we introduce Particle Smoothing Variational Objectives (SVO), a novel backward simulation technique and smoothed approximate posterior defined through a subsampling process. SVO augments support of the proposal and boosts particle diversity. Recent literature argues that increasing the number of samples K to obtain tighter variational bounds may hurt the proposal learning, due to a signal-to-noise ratio (SNR) of gradient estimators decreasing at the rate $\mathcal{O}(1/\sqrt{K})$. As a second contribution, we develop theoretical and empirical analysis of the SNR in filtering SMC, which motivates our choice of biased gradient estimators. We prove that introducing bias by dropping Categorical terms from the gradient estimate or using Gumbel-Softmax mitigates the adverse effect on the SNR. We apply SVO to three nonlinear latent dynamics tasks and provide statistics to rigorously quantify the predictions of filtered and smoothed objectives. SVO consistently outperforms filtered objectives when given fewer Monte Carlo samples on three nonlinear systems of increasing complexity.