 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Prior Fitted Networks for Zero-Shot Forecasting with Exogenous Variables
Mar 16, 2026In many time series forecasting settings, the target time series is accompanied by exogenous covariates, such as promotions and prices in retail demand; temperature in energy load; calendar and holiday indicators for traffic or sales; and grid load or fuel costs in electricity pricing. Ignoring these exogenous signals can substantially degrade forecasting accuracy, particularly when they drive spikes, discontinuities, or regime and phase changes in the target series. Most current time series foundation models (e.g., Chronos, Sundial, TimesFM, TimeMoE, TimeLLM, and LagLlama) ignore exogenous covariates and make forecasts solely from the numerical time series history, thereby limiting their performance. In this paper, we develop ApolloPFN, a prior-data fitted network (PFN) that is time-aware (unlike prior PFNs) and that natively incorporates exogenous covariates (unlike prior univariate forecasters). Our design introduces two major advances: (i) a synthetic data generation procedure tailored to resolve the failure modes that arise when tabular (non-temporal) PFNs are applied to time series; and (ii) time-aware architectural modifications that embed inductive biases needed to exploit the time series context. We demonstrate that ApolloPFN achieves state-of-the-art results across benchmarks, such as M5 and electric price forecasting, that contain exogenous information.
Zero-shot Forecasting by Simulation Alone
Jan 02, 2026Zero-shot time-series forecasting holds great promise, but is still in its infancy, hindered by limited and biased data corpora, leakage-prone evaluation, and privacy and licensing constraints. Motivated by these challenges, we propose the first practical univariate time series simulation pipeline which is simultaneously fast enough for on-the-fly data generation and enables notable zero-shot forecasting performance on M-Series and GiftEval benchmarks that capture trend/seasonality/intermittency patterns, typical of industrial forecasting applications across a variety of domains. Our simulator, which we call SarSim0 (SARIMA Simulator for Zero-Shot Forecasting), is based off of a seasonal autoregressive integrated moving average (SARIMA) model as its core data source. Due to instability in the autoregressive component, naive SARIMA simulation often leads to unusable paths. Instead, we follow a three-step procedure: (1) we sample well-behaved trajectories from its characteristic polynomial stability region; (2) we introduce a superposition scheme that combines multiple paths into rich multi-seasonality traces; and (3) we add rate-based heavy-tailed noise models to capture burstiness and intermittency alongside seasonalities and trends. SarSim0 is orders of magnitude faster than kernel-based generators, and it enables training on circa 1B unique purely simulated series, generated on the fly; after which well-established neural network backbones exhibit strong zero-shot generalization, surpassing strong statistical forecasters and recent foundation baselines, while operating under strict zero-shot protocol. Notably, on GiftEval we observe a "student-beats-teacher" effect: models trained on our simulations exceed the forecasting accuracy of the AutoARIMA generating processes.
Customizing the Inductive Biases of Softmax Attention using Structured Matrices
Sep 09, 2025The core component of attention is the scoring function, which transforms the inputs into low-dimensional queries and keys and takes the dot product of each pair. While the low-dimensional projection improves efficiency, it causes information loss for certain tasks that have intrinsically high-dimensional inputs. Additionally, attention uses the same scoring function for all input pairs, without imposing a distance-dependent compute bias for neighboring tokens in the sequence. In this work, we address these shortcomings by proposing new scoring functions based on computationally efficient structured matrices with high ranks, including Block Tensor-Train (BTT) and Multi-Level Low Rank (MLR) matrices. On in-context regression tasks with high-dimensional inputs, our proposed scoring functions outperform standard attention for any fixed compute budget. On language modeling, a task that exhibits locality patterns, our MLR-based attention method achieves improved scaling laws compared to both standard attention and variants of sliding window attention. Additionally, we show that both BTT and MLR fall under a broader family of efficient structured matrices capable of encoding either full-rank or distance-dependent compute biases, thereby addressing significant shortcomings of standard attention. Finally, we show that MLR attention has promising results for long-range time-series forecasting.
Training Flexible Models of Genetic Variant Effects from Functional Annotations using Accelerated Linear Algebra
Jun 24, 2025To understand how genetic variants in human genomes manifest in phenotypes -- traits like height or diseases like asthma -- geneticists have sequenced and measured hundreds of thousands of individuals. Geneticists use this data to build models that predict how a genetic variant impacts phenotype given genomic features of the variant, like DNA accessibility or the presence of nearby DNA-bound proteins. As more data and features become available, one might expect predictive models to improve. Unfortunately, training these models is bottlenecked by the need to solve expensive linear algebra problems because variants in the genome are correlated with nearby variants, requiring inversion of large matrices. Previous methods have therefore been restricted to fitting small models, and fitting simplified summary statistics, rather than the full likelihood of the statistical model. In this paper, we leverage modern fast linear algebra techniques to develop DeepWAS (Deep genome Wide Association Studies), a method to train large and flexible neural network predictive models to optimize likelihood. Notably, we find that larger models only improve performance when using our full likelihood approach; when trained by fitting traditional summary statistics, larger models perform no better than small ones. We find larger models trained on more features make better predictions, potentially improving disease predictions and therapeutic target identification.
Searching for Efficient Linear Layers over a Continuous Space of Structured Matrices
Oct 03, 2024



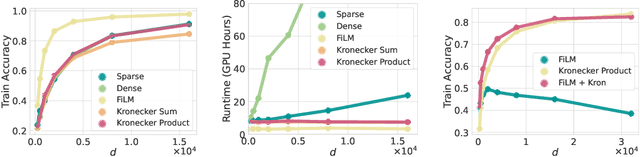
Dense linear layers are the dominant computational bottleneck in large neural networks, presenting a critical need for more efficient alternatives. Previous efforts focused on a small number of hand-crafted structured matrices and neglected to investigate whether these structures can surpass dense layers in terms of compute-optimal scaling laws when both the model size and training examples are optimally allocated. In this work, we present a unifying framework that enables searching among all linear operators expressible via an Einstein summation. This framework encompasses many previously proposed structures, such as low-rank, Kronecker, Tensor-Train, Block Tensor-Train (BTT), and Monarch, along with many novel structures. To analyze the framework, we develop a taxonomy of all such operators based on their computational and algebraic properties and show that differences in the compute-optimal scaling laws are mostly governed by a small number of variables that we introduce. Namely, a small $\omega$ (which measures parameter sharing) and large $\psi$ (which measures the rank) reliably led to better scaling laws. Guided by the insight that full-rank structures that maximize parameters per unit of compute perform the best, we propose BTT-MoE, a novel Mixture-of-Experts (MoE) architecture obtained by sparsifying computation in the BTT structure. In contrast to the standard sparse MoE for each entire feed-forward network, BTT-MoE learns an MoE in every single linear layer of the model, including the projection matrices in the attention blocks. We find BTT-MoE provides a substantial compute-efficiency gain over dense layers and standard MoE.
Compute Better Spent: Replacing Dense Layers with Structured Matrices
Jun 10, 2024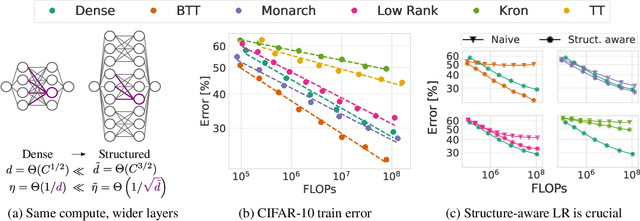

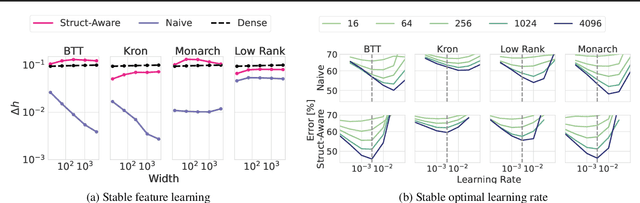

Dense linear layers are the dominant computational bottleneck in foundation models. Identifying more efficient alternatives to dense matrices has enormous potential for building more compute-efficient models, as exemplified by the success of convolutional networks in the image domain. In this work, we systematically explore structured matrices as replacements for dense matrices. We show that different structures often require drastically different initialization scales and learning rates, which are crucial to performance, especially as models scale. Using insights from the Maximal Update Parameterization, we determine the optimal scaling for initialization and learning rates of these unconventional layers. Finally, we measure the scaling laws of different structures to compare how quickly their performance improves with compute. We propose a novel matrix family containing Monarch matrices, the Block Tensor-Train (BTT), which we show performs better than dense matrices for the same compute on multiple tasks. On CIFAR-10/100 with augmentation, BTT achieves exponentially lower training loss than dense when training MLPs and ViTs. BTT matches dense ViT-S/32 performance on ImageNet-1k with 3.8 times less compute and is more efficient than dense for training small GPT-2 language models.
CoLA: Exploiting Compositional Structure for Automatic and Efficient Numerical Linear Algebra
Sep 06, 2023



Many areas of machine learning and science involve large linear algebra problems, such as eigendecompositions, solving linear systems, computing matrix exponentials, and trace estimation. The matrices involved often have Kronecker, convolutional, block diagonal, sum, or product structure. In this paper, we propose a simple but general framework for large-scale linear algebra problems in machine learning, named CoLA (Compositional Linear Algebra). By combining a linear operator abstraction with compositional dispatch rules, CoLA automatically constructs memory and runtime efficient numerical algorithms. Moreover, CoLA provides memory efficient automatic differentiation, low precision computation, and GPU acceleration in both JAX and PyTorch, while also accommodating new objects, operations, and rules in downstream packages via multiple dispatch. CoLA can accelerate many algebraic operations, while making it easy to prototype matrix structures and algorithms, providing an appealing drop-in tool for virtually any computational effort that requires linear algebra. We showcase its efficacy across a broad range of applications, including partial differential equations, Gaussian processes, equivariant model construction, and unsupervised learning.
Simple and Fast Group Robustness by Automatic Feature Reweighting
Jun 19, 2023A major challenge to out-of-distribution generalization is reliance on spurious features -- patterns that are predictive of the class label in the training data distribution, but not causally related to the target. Standard methods for reducing the reliance on spurious features typically assume that we know what the spurious feature is, which is rarely true in the real world. Methods that attempt to alleviate this limitation are complex, hard to tune, and lead to a significant computational overhead compared to standard training. In this paper, we propose Automatic Feature Reweighting (AFR), an extremely simple and fast method for updating the model to reduce the reliance on spurious features. AFR retrains the last layer of a standard ERM-trained base model with a weighted loss that emphasizes the examples where the ERM model predicts poorly, automatically upweighting the minority group without group labels. With this simple procedure, we improve upon the best reported results among competing methods trained without spurious attributes on several vision and natural language classification benchmarks, using only a fraction of their compute.
* ICML 23. Code available at https://github.com/AndPotap/afr
A Stable and Scalable Method for Solving Initial Value PDEs with Neural Networks
Apr 28, 2023



Unlike conventional grid and mesh based methods for solving partial differential equations (PDEs), neural networks have the potential to break the curse of dimensionality, providing approximate solutions to problems where using classical solvers is difficult or impossible. While global minimization of the PDE residual over the network parameters works well for boundary value problems, catastrophic forgetting impairs the applicability of this approach to initial value problems (IVPs). In an alternative local-in-time approach, the optimization problem can be converted into an ordinary differential equation (ODE) on the network parameters and the solution propagated forward in time; however, we demonstrate that current methods based on this approach suffer from two key issues. First, following the ODE produces an uncontrolled growth in the conditioning of the problem, ultimately leading to unacceptably large numerical errors. Second, as the ODE methods scale cubically with the number of model parameters, they are restricted to small neural networks, significantly limiting their ability to represent intricate PDE initial conditions and solutions. Building on these insights, we develop Neural IVP, an ODE based IVP solver which prevents the network from getting ill-conditioned and runs in time linear in the number of parameters, enabling us to evolve the dynamics of challenging PDEs with neural networks.
PAC-Bayes Compression Bounds So Tight That They Can Explain Generalization
Nov 24, 2022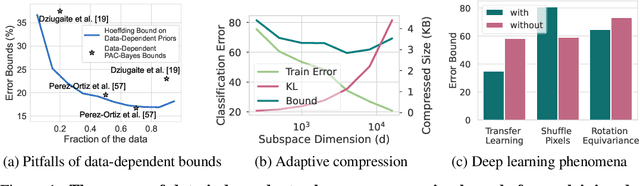

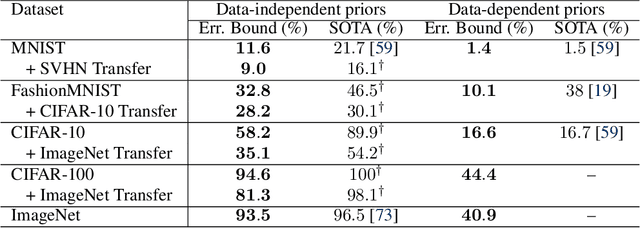
While there has been progress in developing non-vacuous generalization bounds for deep neural networks, these bounds tend to be uninformative about why deep learning works. In this paper, we develop a compression approach based on quantizing neural network parameters in a linear subspace, profoundly improving on previous results to provide state-of-the-art generalization bounds on a variety of tasks, including transfer learning. We use these tight bounds to better understand the role of model size, equivariance, and the implicit biases of optimization, for generalization in deep learning. Notably, we find large models can be compressed to a much greater extent than previously known, encapsulating Occam's razor. We also argue for data-independent bounds in explaining generalization.