 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
Jan 06, 2026Can we learn more from data than existed in the generating process itself? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable content in data be evaluated without considering a downstream task? On these questions, Shannon information and Kolmogorov complexity come up nearly empty-handed, in part because they assume observers with unlimited computational capacity and fail to target the useful information content. In this work, we identify and exemplify three seeming paradoxes in information theory: (1) information cannot be increased by deterministic transformations; (2) information is independent of the order of data; (3) likelihood modeling is merely distribution matching. To shed light on the tension between these results and modern practice, and to quantify the value of data, we introduce epiplexity, a formalization of information capturing what computationally bounded observers can learn from data. Epiplexity captures the structural content in data while excluding time-bounded entropy, the random unpredictable content exemplified by pseudorandom number generators and chaotic dynamical systems. With these concepts, we demonstrate how information can be created with computation, how it depends on the ordering of the data, and how likelihood modeling can produce more complex programs than present in the data generating process itself. We also present practical procedures to estimate epiplexity which we show capture differences across data sources, track with downstream performance, and highlight dataset interventions that improve out-of-distribution generalization. In contrast to principles of model selection, epiplexity provides a theoretical foundation for data selection, guiding how to select, generate, or transform data for learning systems.
Customizing the Inductive Biases of Softmax Attention using Structured Matrices
Sep 09, 2025The core component of attention is the scoring function, which transforms the inputs into low-dimensional queries and keys and takes the dot product of each pair. While the low-dimensional projection improves efficiency, it causes information loss for certain tasks that have intrinsically high-dimensional inputs. Additionally, attention uses the same scoring function for all input pairs, without imposing a distance-dependent compute bias for neighboring tokens in the sequence. In this work, we address these shortcomings by proposing new scoring functions based on computationally efficient structured matrices with high ranks, including Block Tensor-Train (BTT) and Multi-Level Low Rank (MLR) matrices. On in-context regression tasks with high-dimensional inputs, our proposed scoring functions outperform standard attention for any fixed compute budget. On language modeling, a task that exhibits locality patterns, our MLR-based attention method achieves improved scaling laws compared to both standard attention and variants of sliding window attention. Additionally, we show that both BTT and MLR fall under a broader family of efficient structured matrices capable of encoding either full-rank or distance-dependent compute biases, thereby addressing significant shortcomings of standard attention. Finally, we show that MLR attention has promising results for long-range time-series forecasting.
Scaling Collapse Reveals Universal Dynamics in Compute-Optimally Trained Neural Networks
Jul 02, 2025What scaling limits govern neural network training dynamics when model size and training time grow in tandem? We show that despite the complex interactions between architecture, training algorithms, and data, compute-optimally trained models exhibit a remarkably precise universality. Specifically, loss curves from models of varying sizes collapse onto a single universal curve when training compute and loss are normalized to unity at the end of training. With learning rate decay, the collapse becomes so tight that differences in the normalized curves across models fall below the noise floor of individual loss curves across random seeds, a phenomenon we term supercollapse. We observe supercollapse across learning rate schedules, datasets, and architectures, including transformers trained on next-token prediction, and find it breaks down when hyperparameters are scaled suboptimally, providing a precise and practical indicator of good scaling. We explain these phenomena by connecting collapse to the power-law structure in typical neural scaling laws, and analyzing a simple yet surprisingly effective model of SGD noise dynamics that accurately predicts loss curves across various learning rate schedules and quantitatively explains the origin of supercollapse.
Out-of-Distribution Detection Methods Answer the Wrong Questions
Jul 02, 2025To detect distribution shifts and improve model safety, many out-of-distribution (OOD) detection methods rely on the predictive uncertainty or features of supervised models trained on in-distribution data. In this paper, we critically re-examine this popular family of OOD detection procedures, and we argue that these methods are fundamentally answering the wrong questions for OOD detection. There is no simple fix to this misalignment, since a classifier trained only on in-distribution classes cannot be expected to identify OOD points; for instance, a cat-dog classifier may confidently misclassify an airplane if it contains features that distinguish cats from dogs, despite generally appearing nothing alike. We find that uncertainty-based methods incorrectly conflate high uncertainty with being OOD, while feature-based methods incorrectly conflate far feature-space distance with being OOD. We show how these pathologies manifest as irreducible errors in OOD detection and identify common settings where these methods are ineffective. Additionally, interventions to improve OOD detection such as feature-logit hybrid methods, scaling of model and data size, epistemic uncertainty representation, and outlier exposure also fail to address this fundamental misalignment in objectives. We additionally consider unsupervised density estimation and generative models for OOD detection, which we show have their own fundamental limitations.
Searching for Efficient Linear Layers over a Continuous Space of Structured Matrices
Oct 03, 2024



Dense linear layers are the dominant computational bottleneck in large neural networks, presenting a critical need for more efficient alternatives. Previous efforts focused on a small number of hand-crafted structured matrices and neglected to investigate whether these structures can surpass dense layers in terms of compute-optimal scaling laws when both the model size and training examples are optimally allocated. In this work, we present a unifying framework that enables searching among all linear operators expressible via an Einstein summation. This framework encompasses many previously proposed structures, such as low-rank, Kronecker, Tensor-Train, Block Tensor-Train (BTT), and Monarch, along with many novel structures. To analyze the framework, we develop a taxonomy of all such operators based on their computational and algebraic properties and show that differences in the compute-optimal scaling laws are mostly governed by a small number of variables that we introduce. Namely, a small $\omega$ (which measures parameter sharing) and large $\psi$ (which measures the rank) reliably led to better scaling laws. Guided by the insight that full-rank structures that maximize parameters per unit of compute perform the best, we propose BTT-MoE, a novel Mixture-of-Experts (MoE) architecture obtained by sparsifying computation in the BTT structure. In contrast to the standard sparse MoE for each entire feed-forward network, BTT-MoE learns an MoE in every single linear layer of the model, including the projection matrices in the attention blocks. We find BTT-MoE provides a substantial compute-efficiency gain over dense layers and standard MoE.
Transferring Knowledge from Large Foundation Models to Small Downstream Models
Jun 11, 2024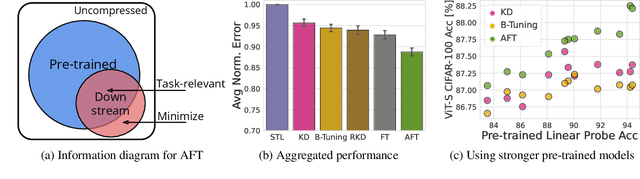

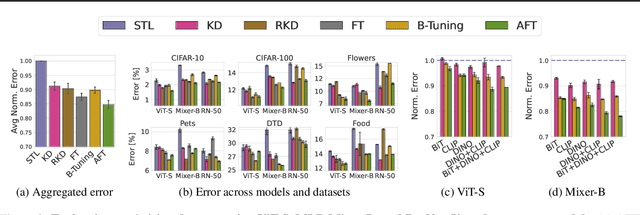

How do we transfer the relevant knowledge from ever larger foundation models into small, task-specific downstream models that can run at much lower costs? Standard transfer learning using pre-trained weights as the initialization transfers limited information and commits us to often massive pre-trained architectures. This procedure also precludes combining multiple pre-trained models that learn complementary information. To address these shortcomings, we introduce Adaptive Feature Transfer (AFT). Instead of transferring weights, AFT operates purely on features, thereby decoupling the choice of the pre-trained model from the smaller downstream model. Rather than indiscriminately compressing all pre-trained features, AFT adaptively transfers pre-trained features that are most useful for performing the downstream task, using a simple regularization that adds minimal overhead. Across multiple vision, language, and multi-modal datasets, AFT achieves significantly better downstream performance compared to alternatives with a similar computational cost. Furthermore, AFT reliably translates improvement in pre-trained models into improvement in downstream performance, even if the downstream model is over $50\times$ smaller, and can effectively transfer complementary information learned by multiple pre-trained models.
Compute Better Spent: Replacing Dense Layers with Structured Matrices
Jun 10, 2024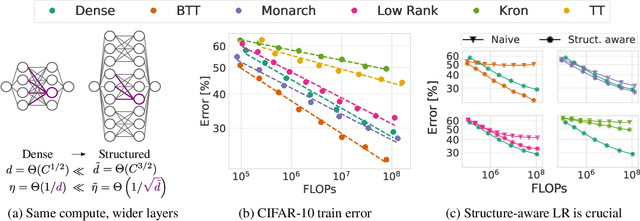

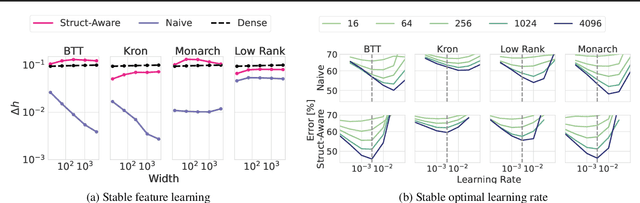

Dense linear layers are the dominant computational bottleneck in foundation models. Identifying more efficient alternatives to dense matrices has enormous potential for building more compute-efficient models, as exemplified by the success of convolutional networks in the image domain. In this work, we systematically explore structured matrices as replacements for dense matrices. We show that different structures often require drastically different initialization scales and learning rates, which are crucial to performance, especially as models scale. Using insights from the Maximal Update Parameterization, we determine the optimal scaling for initialization and learning rates of these unconventional layers. Finally, we measure the scaling laws of different structures to compare how quickly their performance improves with compute. We propose a novel matrix family containing Monarch matrices, the Block Tensor-Train (BTT), which we show performs better than dense matrices for the same compute on multiple tasks. On CIFAR-10/100 with augmentation, BTT achieves exponentially lower training loss than dense when training MLPs and ViTs. BTT matches dense ViT-S/32 performance on ImageNet-1k with 3.8 times less compute and is more efficient than dense for training small GPT-2 language models.
Function-Space Regularization in Neural Networks: A Probabilistic Perspective
Dec 28, 2023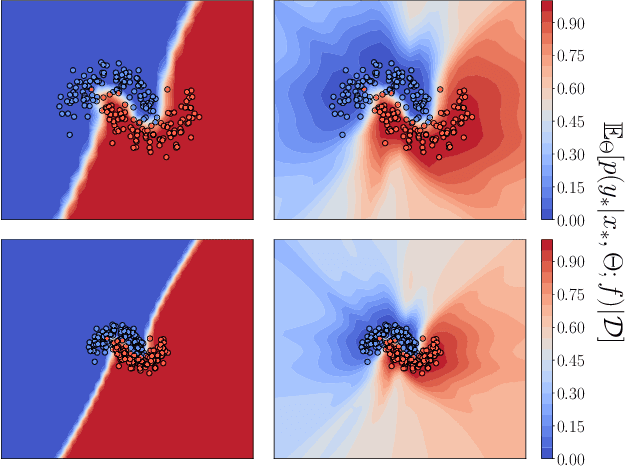
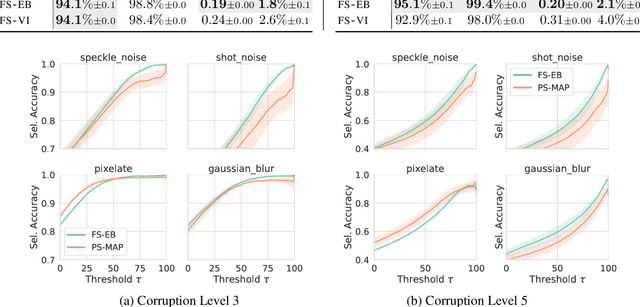
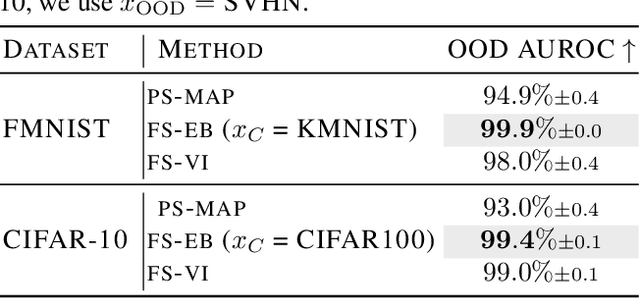
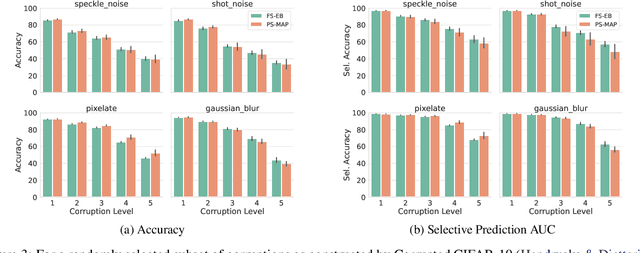
Parameter-space regularization in neural network optimization is a fundamental tool for improving generalization. However, standard parameter-space regularization methods make it challenging to encode explicit preferences about desired predictive functions into neural network training. In this work, we approach regularization in neural networks from a probabilistic perspective and show that by viewing parameter-space regularization as specifying an empirical prior distribution over the model parameters, we can derive a probabilistically well-motivated regularization technique that allows explicitly encoding information about desired predictive functions into neural network training. This method -- which we refer to as function-space empirical Bayes (FSEB) -- includes both parameter- and function-space regularization, is mathematically simple, easy to implement, and incurs only minimal computational overhead compared to standard regularization techniques. We evaluate the utility of this regularization technique empirically and demonstrate that the proposed method leads to near-perfect semantic shift detection, highly-calibrated predictive uncertainty estimates, successful task adaption from pre-trained models, and improved generalization under covariate shift.
Should We Learn Most Likely Functions or Parameters?
Nov 27, 2023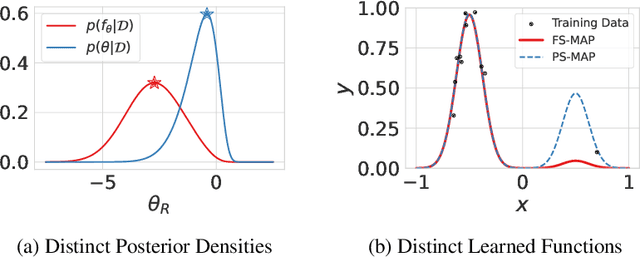

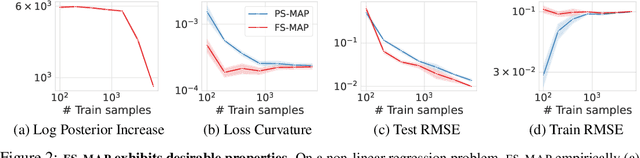
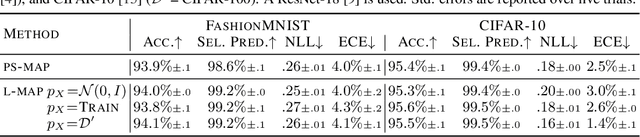
Standard regularized training procedures correspond to maximizing a posterior distribution over parameters, known as maximum a posteriori (MAP) estimation. However, model parameters are of interest only insomuch as they combine with the functional form of a model to provide a function that can make good predictions. Moreover, the most likely parameters under the parameter posterior do not generally correspond to the most likely function induced by the parameter posterior. In fact, we can re-parametrize a model such that any setting of parameters can maximize the parameter posterior. As an alternative, we investigate the benefits and drawbacks of directly estimating the most likely function implied by the model and the data. We show that this procedure leads to pathological solutions when using neural networks and prove conditions under which the procedure is well-behaved, as well as a scalable approximation. Under these conditions, we find that function-space MAP estimation can lead to flatter minima, better generalization, and improved robustness to overfitting.
Large Language Models Are Zero-Shot Time Series Forecasters
Oct 11, 2023By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.