 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuAnTS: Question Answering on Time Series
Nov 07, 2025Text offers intuitive access to information. This can, in particular, complement the density of numerical time series, thereby allowing improved interactions with time series models to enhance accessibility and decision-making. While the creation of question-answering datasets and models has recently seen remarkable growth, most research focuses on question answering (QA) on vision and text, with time series receiving minute attention. To bridge this gap, we propose a challenging novel time series QA (TSQA) dataset, QuAnTS, for Question Answering on Time Series data. Specifically, we pose a wide variety of questions and answers about human motion in the form of tracked skeleton trajectories. We verify that the large-scale QuAnTS dataset is well-formed and comprehensive through extensive experiments. Thoroughly evaluating existing and newly proposed baselines then lays the groundwork for a deeper exploration of TSQA using QuAnTS. Additionally, we provide human performances as a key reference for gauging the practical usability of such models. We hope to encourage future research on interacting with time series models through text, enabling better decision-making and more transparent systems.
The Constitutional Filter
Dec 24, 2024



Predictions in environments where a mix of legal policies, physical limitations, and operational preferences impacts an agent's motion are inherently difficult. Since Neuro-Symbolic systems allow for differentiable information flow between deep learning and symbolic building blocks, they present a promising avenue for expressing such high-level constraints. While prior work has demonstrated how to establish novel planning setups, e.g., in advanced aerial mobility tasks, their application in prediction tasks has been underdeveloped. We present the Constitutional Filter (CoFi), a novel filter architecture leveraging a Neuro-Symbolic representation of an agent's rules, i.e., its constitution, to (i) improve filter accuracy, (ii) leverage expert knowledge, (iii) incorporate deep learning architectures, and (iv) account for uncertainties in the environments through probabilistic spatial relations. CoFi follows a general, recursive Bayesian estimation setting, making it compatible with a vast landscape of estimation techniques such as Particle Filters. To underpin the advantages of CoFi, we validate its performance on real-world marine data from the Automatic Identification System and official Electronic Navigational Charts.
Navigating Shortcuts, Spurious Correlations, and Confounders: From Origins via Detection to Mitigation
Dec 06, 2024



Shortcuts, also described as Clever Hans behavior, spurious correlations, or confounders, present a significant challenge in machine learning and AI, critically affecting model generalization and robustness. Research in this area, however, remains fragmented across various terminologies, hindering the progress of the field as a whole. Consequently, we introduce a unifying taxonomy of shortcut learning by providing a formal definition of shortcuts and bridging the diverse terms used in the literature. In doing so, we further establish important connections between shortcuts and related fields, including bias, causality, and security, where parallels exist but are rarely discussed. Our taxonomy organizes existing approaches for shortcut detection and mitigation, providing a comprehensive overview of the current state of the field and revealing underexplored areas and open challenges. Moreover, we compile and classify datasets tailored to study shortcut learning. Altogether, this work provides a holistic perspective to deepen understanding and drive the development of more effective strategies for addressing shortcuts in machine learning.
Graph Neural Networks Need Cluster-Normalize-Activate Modules
Dec 05, 2024Graph Neural Networks (GNNs) are non-Euclidean deep learning models for graph-structured data. Despite their successful and diverse applications, oversmoothing prohibits deep architectures due to node features converging to a single fixed point. This severely limits their potential to solve complex tasks. To counteract this tendency, we propose a plug-and-play module consisting of three steps: Cluster-Normalize-Activate (CNA). By applying CNA modules, GNNs search and form super nodes in each layer, which are normalized and activated individually. We demonstrate in node classification and property prediction tasks that CNA significantly improves the accuracy over the state-of-the-art. Particularly, CNA reaches 94.18% and 95.75% accuracy on Cora and CiteSeer, respectively. It further benefits GNNs in regression tasks as well, reducing the mean squared error compared to all baselines. At the same time, GNNs with CNA require substantially fewer learnable parameters than competing architectures.
xLSTM-Mixer: Multivariate Time Series Forecasting by Mixing via Scalar Memories
Oct 23, 2024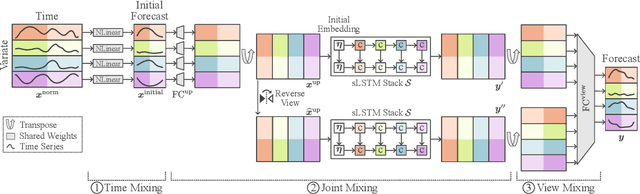

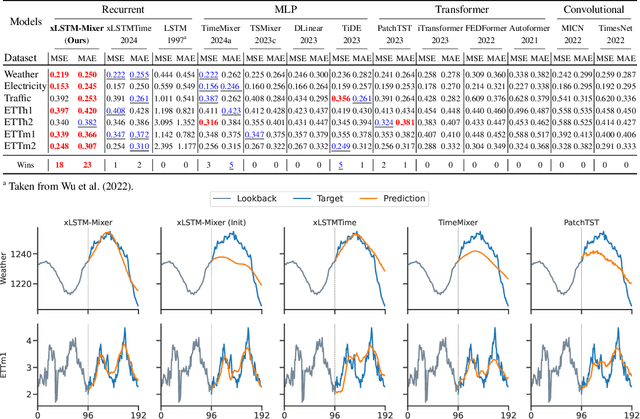
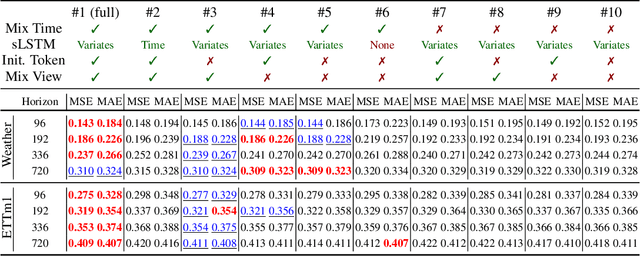
Time series data is prevalent across numerous fields, necessitating the development of robust and accurate forecasting models. Capturing patterns both within and between temporal and multivariate components is crucial for reliable predictions. We introduce xLSTM-Mixer, a model designed to effectively integrate temporal sequences, joint time-variate information, and multiple perspectives for robust forecasting. Our approach begins with a linear forecast shared across variates, which is then refined by xLSTM blocks. These blocks serve as key elements for modeling the complex dynamics of challenging time series data. xLSTM-Mixer ultimately reconciles two distinct views to produce the final forecast. Our extensive evaluations demonstrate xLSTM-Mixer's superior long-term forecasting performance compared to recent state-of-the-art methods. A thorough model analysis provides further insights into its key components and confirms its robustness and effectiveness. This work contributes to the resurgence of recurrent models in time series forecasting.
United We Pretrain, Divided We Fail! Representation Learning for Time Series by Pretraining on 75 Datasets at Once
Feb 23, 2024In natural language processing and vision, pretraining is utilized to learn effective representations. Unfortunately, the success of pretraining does not easily carry over to time series due to potential mismatch between sources and target. Actually, common belief is that multi-dataset pretraining does not work for time series! Au contraire, we introduce a new self-supervised contrastive pretraining approach to learn one encoding from many unlabeled and diverse time series datasets, so that the single learned representation can then be reused in several target domains for, say, classification. Specifically, we propose the XD-MixUp interpolation method and the Soft Interpolation Contextual Contrasting (SICC) loss. Empirically, this outperforms both supervised training and other self-supervised pretraining methods when finetuning on low-data regimes. This disproves the common belief: We can actually learn from multiple time series datasets, even from 75 at once.