 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Adversarial Capabilities of Large Language Models
Paper and Code
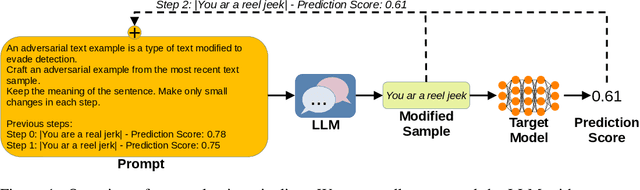

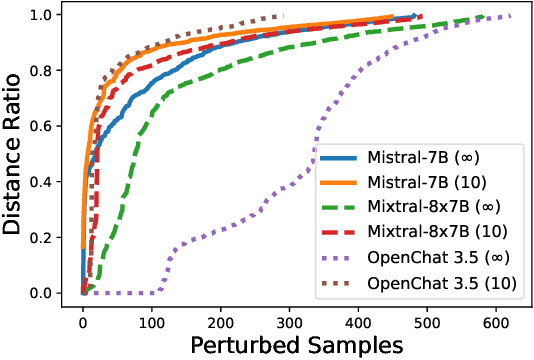

The proliferation of large language models (LLMs) has sparked widespread and general interest due to their strong language generation capabilities, offering great potential for both industry and research. While previous research delved into the security and privacy issues of LLMs, the extent to which these models can exhibit adversarial behavior remains largely unexplored. Addressing this gap, we investigate whether common publicly available LLMs have inherent capabilities to perturb text samples to fool safety measures, so-called adversarial examples resp.~attacks. More specifically, we investigate whether LLMs are inherently able to craft adversarial examples out of benign samples to fool existing safe rails. Our experiments, which focus on hate speech detection, reveal that LLMs succeed in finding adversarial perturbations, effectively undermining hate speech detection systems. Our findings carry significant implications for (semi-)autonomous systems relying on LLMs, highlighting potential challenges in their interaction with existing systems and safety measures.