 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqualizing Recourse across Groups
Sep 07, 2019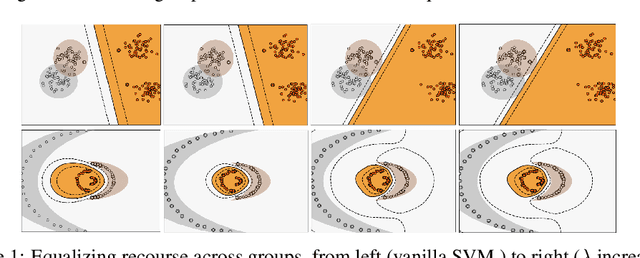
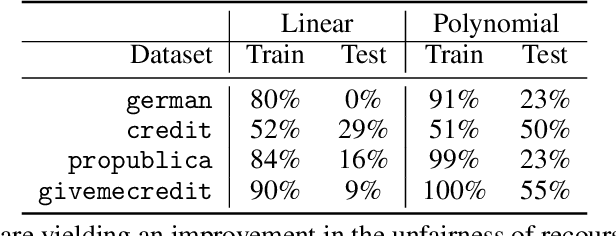

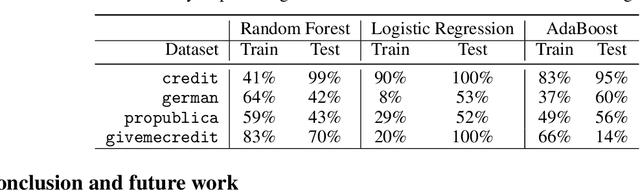
The rise in machine learning-assisted decision-making has led to concerns about the fairness of the decisions and techniques to mitigate problems of discrimination. If a negative decision is made about an individual (denying a loan, rejecting an application for housing, and so on) justice dictates that we be able to ask how we might change circumstances to get a favorable decision the next time. Moreover, the ability to change circumstances (a better education, improved credentials) should not be limited to only those with access to expensive resources. In other words, \emph{recourse} for negative decisions should be considered a desirable value that can be equalized across (demographically defined) groups. This paper describes how to build models that make accurate predictions while still ensuring that the penalties for a negative outcome do not disadvantage different groups disproportionately. We measure recourse as the distance of an individual from the decision boundary of a classifier. We then introduce a regularized objective to minimize the difference in recourse across groups. We explore linear settings and further extend recourse to non-linear settings as well as model-agnostic settings where the exact distance from boundary cannot be calculated. Our results show that we can successfully decrease the unfairness in recourse while maintaining classifier performance.
Assessing the Local Interpretability of Machine Learning Models
Feb 09, 2019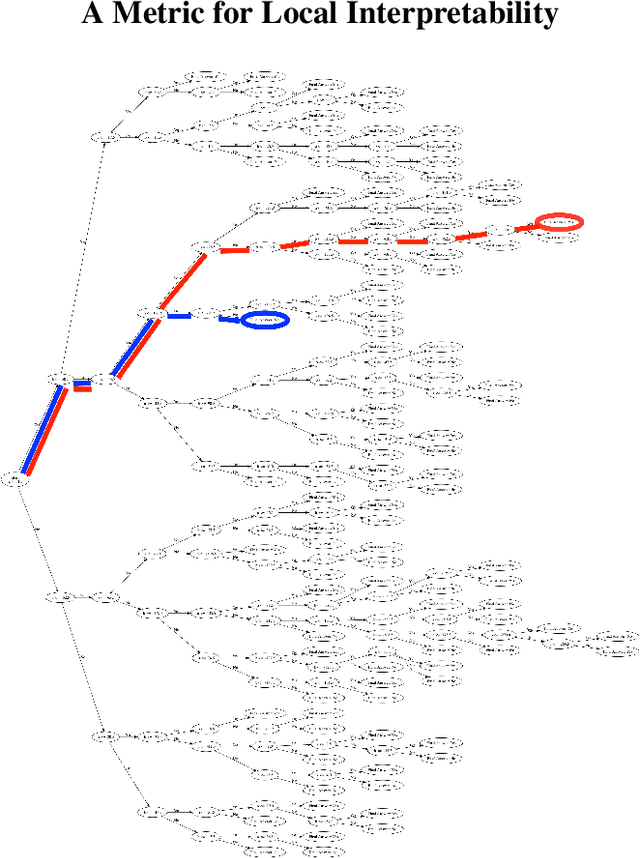
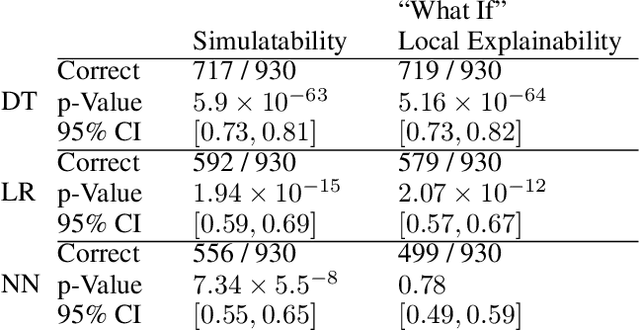


The increasing adoption of machine learning tools has led to calls for accountability via model interpretability. But what does it mean for a machine learning model to be interpretable by humans, and how can this be assessed? We focus on two definitions of interpretability that have been introduced in the machine learning literature: simulatability (a user's ability to run a model on a given input) and "what if" local explainability (a user's ability to correctly indicate the outcome to a model under local changes to the input). Through a user study with 1000 participants, we test whether humans perform well on tasks that mimic the definitions of simulatability and "what if" local explainability on models that are typically considered locally interpretable. We find evidence consistent with the common intuition that decision trees and logistic regression models are interpretable and are more interpretable than neural networks. We propose a metric - the runtime operation count on the simulatability task - to indicate the relative interpretability of models and show that as the number of operations increases the users' accuracy on the local interpretability tasks decreases.