 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Local Interpretability of Machine Learning Models
Paper and Code
Feb 09, 2019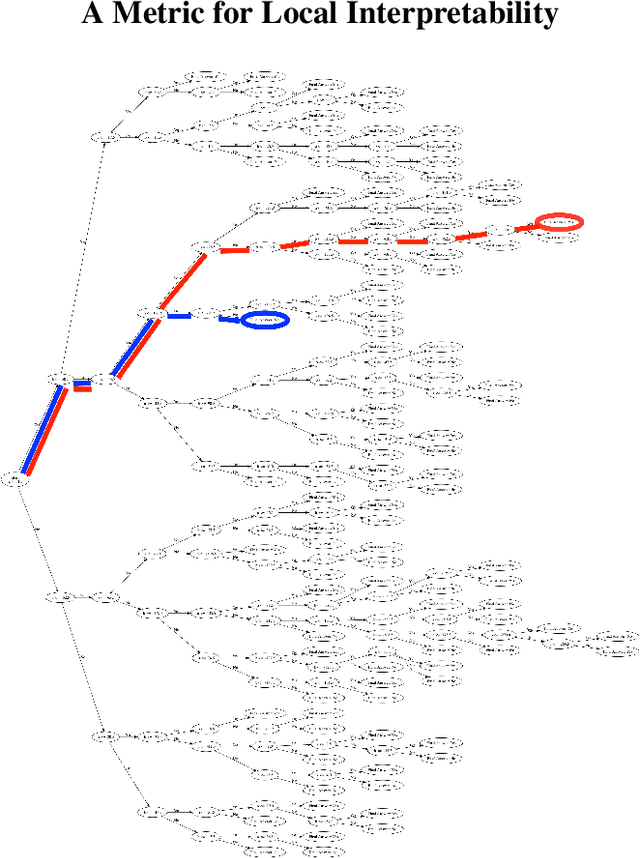
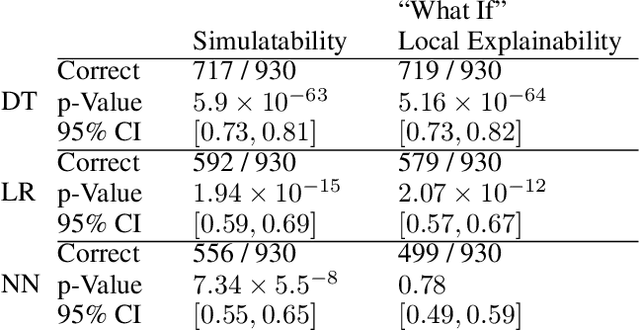


The increasing adoption of machine learning tools has led to calls for accountability via model interpretability. But what does it mean for a machine learning model to be interpretable by humans, and how can this be assessed? We focus on two definitions of interpretability that have been introduced in the machine learning literature: simulatability (a user's ability to run a model on a given input) and "what if" local explainability (a user's ability to correctly indicate the outcome to a model under local changes to the input). Through a user study with 1000 participants, we test whether humans perform well on tasks that mimic the definitions of simulatability and "what if" local explainability on models that are typically considered locally interpretable. We find evidence consistent with the common intuition that decision trees and logistic regression models are interpretable and are more interpretable than neural networks. We propose a metric - the runtime operation count on the simulatability task - to indicate the relative interpretability of models and show that as the number of operations increases the users' accuracy on the local interpretability tasks decreases.