 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-SIF: Document Embeddings Using Partition Averaging
May 18, 2020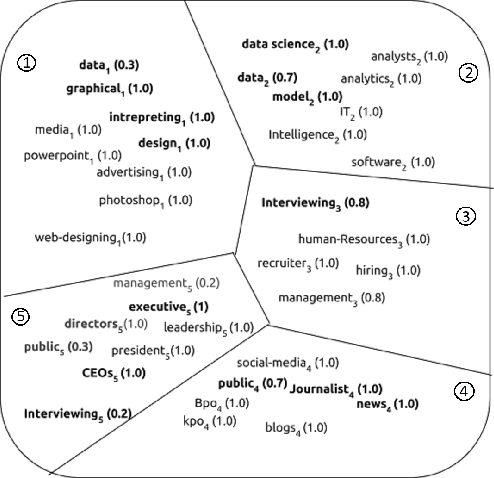


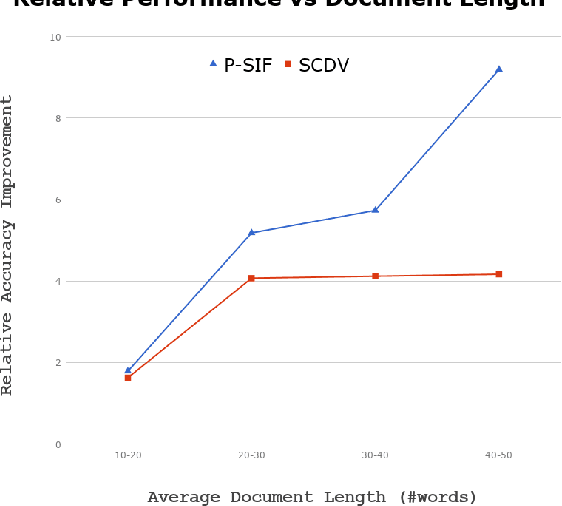
Simple weighted averaging of word vectors often yields effective representations for sentences which outperform sophisticated seq2seq neural models in many tasks. While it is desirable to use the same method to represent documents as well, unfortunately, the effectiveness is lost when representing long documents involving multiple sentences. One of the key reasons is that a longer document is likely to contain words from many different topics; hence, creating a single vector while ignoring all the topical structure is unlikely to yield an effective document representation. This problem is less acute in single sentences and other short text fragments where the presence of a single topic is most likely. To alleviate this problem, we present P-SIF, a partitioned word averaging model to represent long documents. P-SIF retains the simplicity of simple weighted word averaging while taking a document's topical structure into account. In particular, P-SIF learns topic-specific vectors from a document and finally concatenates them all to represent the overall document. We provide theoretical justifications on the correctness of P-SIF. Through a comprehensive set of experiments, we demonstrate P-SIF's effectiveness compared to simple weighted averaging and many other baselines.
Improving Document Classification with Multi-Sense Embeddings
Nov 18, 2019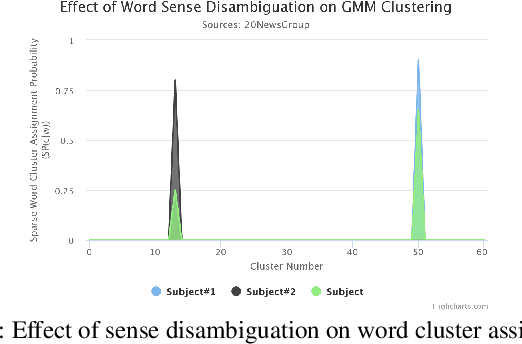

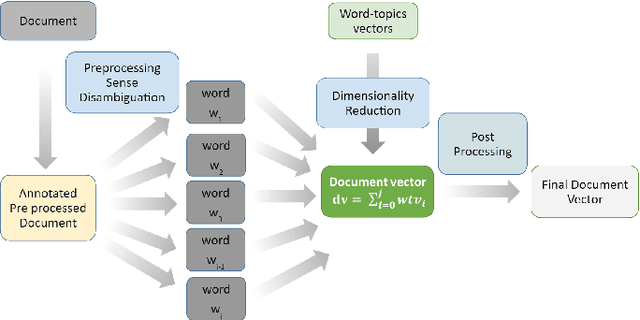
Efficient representation of text documents is an important building block in many NLP tasks. Research on long text categorization has shown that simple weighted averaging of word vectors for sentence representation often outperforms more sophisticated neural models. Recently proposed Sparse Composite Document Vector (SCDV) (Mekala et. al, 2017) extends this approach from sentences to documents using soft clustering over word vectors. However, SCDV disregards the multi-sense nature of words, and it also suffers from the curse of higher dimensionality. In this work, we address these shortcomings and propose SCDV-MS. SCDV-MS utilizes multi-sense word embeddings and learns a lower dimensional manifold. Through extensive experiments on multiple real-world datasets, we show that SCDV-MS embeddings outperform previous state-of-the-art embeddings on multi-class and multi-label text categorization tasks. Furthermore, SCDV-MS embeddings are more efficient than SCDV in terms of time and space complexity on textual classification tasks.