 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePetKaz at SemEval-2024 Task 8: Can Linguistics Capture the Specifics of LLM-generated Text?
Apr 08, 2024In this paper, we present our submission to the SemEval-2024 Task 8 "Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection", focusing on the detection of machine-generated texts (MGTs) in English. Specifically, our approach relies on combining embeddings from the RoBERTa-base with diversity features and uses a resampled training set. We score 12th from 124 in the ranking for Subtask A (monolingual track), and our results show that our approach is generalizable across unseen models and domains, achieving an accuracy of 0.91.
PetKaz at SemEval-2024 Task 3: Advancing Emotion Classification with an LLM for Emotion-Cause Pair Extraction in Conversations
Apr 08, 2024In this paper, we present our submission to the SemEval-2023 Task~3 "The Competition of Multimodal Emotion Cause Analysis in Conversations", focusing on extracting emotion-cause pairs from dialogs. Specifically, our approach relies on combining fine-tuned GPT-3.5 for emotion classification and a BiLSTM-based neural network to detect causes. We score 2nd in the ranking for Subtask 1, demonstrating the effectiveness of our approach through one of the highest weighted-average proportional F1 scores recorded at 0.264.
Razmecheno: Named Entity Recognition from Digital Archive of Diaries "Prozhito"
Jan 24, 2022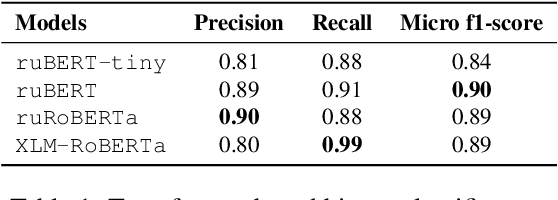

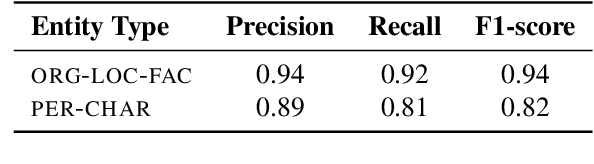
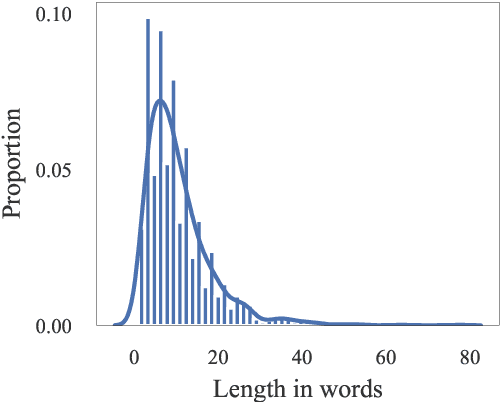
The vast majority of existing datasets for Named Entity Recognition (NER) are built primarily on news, research papers and Wikipedia with a few exceptions, created from historical and literary texts. What is more, English is the main source for data for further labelling. This paper aims to fill in multiple gaps by creating a novel dataset "Razmecheno", gathered from the diary texts of the project "Prozhito" in Russian. Our dataset is of interest for multiple research lines: literary studies of diary texts, transfer learning from other domains, low-resource or cross-lingual named entity recognition. Razmecheno comprises 1331 sentences and 14119 tokens, sampled from diaries, written during the Perestroika. The annotation schema consists of five commonly used entity tags: person, characteristics, location, organisation, and facility. The labelling is carried out on the crowdsourcing platfrom Yandex.Toloka in two stages. First, workers selected sentences, which contain an entity of particular type. Second, they marked up entity spans. As a result 1113 entities were obtained. Empirical evaluation of Razmecheno is carried out with off-the-shelf NER tools and by fine-tuning pre-trained contextualized encoders. We release the annotated dataset for open access.