 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Universal and Independent: Multilingual Probing Framework for Exhaustive Model Interpretation and Evaluation
Oct 24, 2022



Linguistic analysis of language models is one of the ways to explain and describe their reasoning, weaknesses, and limitations. In the probing part of the model interpretability research, studies concern individual languages as well as individual linguistic structures. The question arises: are the detected regularities linguistically coherent, or on the contrary, do they dissonate at the typological scale? Moreover, the majority of studies address the inherent set of languages and linguistic structures, leaving the actual typological diversity knowledge out of scope. In this paper, we present and apply the GUI-assisted framework allowing us to easily probe a massive number of languages for all the morphosyntactic features present in the Universal Dependencies data. We show that reflecting the anglo-centric trend in NLP over the past years, most of the regularities revealed in the mBERT model are typical for the western-European languages. Our framework can be integrated with the existing probing toolboxes, model cards, and leaderboards, allowing practitioners to use and share their standard probing methods to interpret multilingual models. Thus we propose a toolkit to systematize the multilingual flaws in multilingual models, providing a reproducible experimental setup for 104 languages and 80 morphosyntactic features. https://github.com/AIRI-Institute/Probing_framework
Is neural language acquisition similar to natural? A chronological probing study
Jul 01, 2022
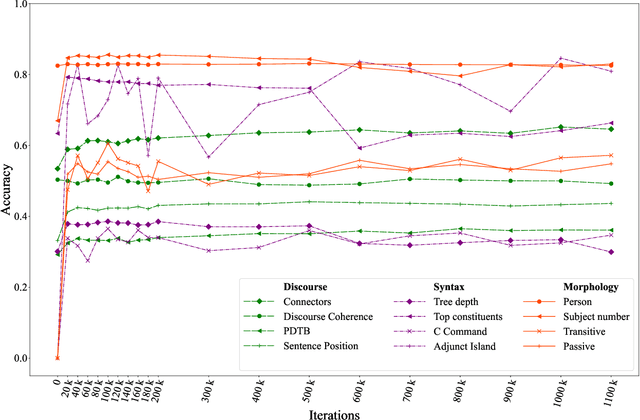

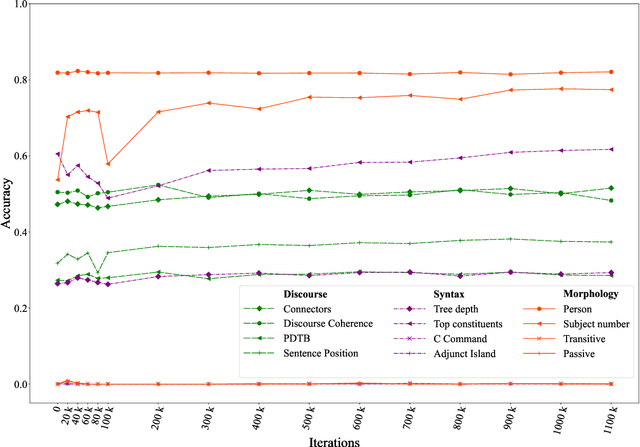
The probing methodology allows one to obtain a partial representation of linguistic phenomena stored in the inner layers of the neural network, using external classifiers and statistical analysis. Pre-trained transformer-based language models are widely used both for natural language understanding (NLU) and natural language generation (NLG) tasks making them most commonly used for downstream applications. However, little analysis was carried out, whether the models were pre-trained enough or contained knowledge correlated with linguistic theory. We are presenting the chronological probing study of transformer English models such as MultiBERT and T5. We sequentially compare the information about the language learned by the models in the process of training on corpora. The results show that 1) linguistic information is acquired in the early stages of training 2) both language models demonstrate capabilities to capture various features from various levels of language, including morphology, syntax, and even discourse, while they also can inconsistently fail on tasks that are perceived as easy. We also introduce the open-source framework for chronological probing research, compatible with other transformer-based models. https://github.com/EkaterinaVoloshina/chronological_probing
Razmecheno: Named Entity Recognition from Digital Archive of Diaries "Prozhito"
Jan 24, 2022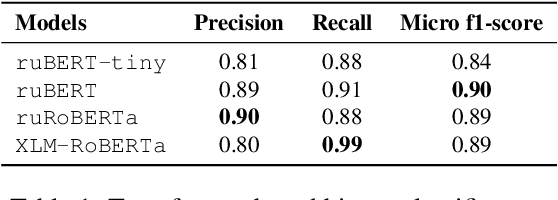

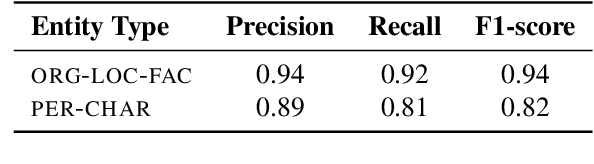
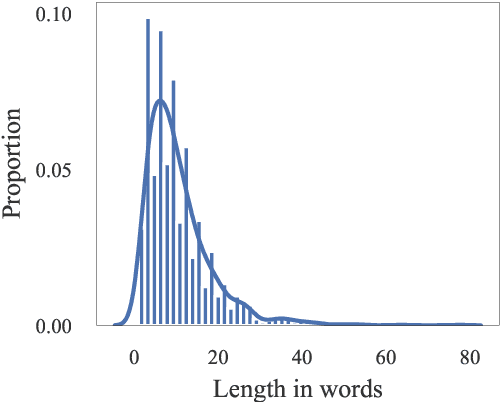
The vast majority of existing datasets for Named Entity Recognition (NER) are built primarily on news, research papers and Wikipedia with a few exceptions, created from historical and literary texts. What is more, English is the main source for data for further labelling. This paper aims to fill in multiple gaps by creating a novel dataset "Razmecheno", gathered from the diary texts of the project "Prozhito" in Russian. Our dataset is of interest for multiple research lines: literary studies of diary texts, transfer learning from other domains, low-resource or cross-lingual named entity recognition. Razmecheno comprises 1331 sentences and 14119 tokens, sampled from diaries, written during the Perestroika. The annotation schema consists of five commonly used entity tags: person, characteristics, location, organisation, and facility. The labelling is carried out on the crowdsourcing platfrom Yandex.Toloka in two stages. First, workers selected sentences, which contain an entity of particular type. Second, they marked up entity spans. As a result 1113 entities were obtained. Empirical evaluation of Razmecheno is carried out with off-the-shelf NER tools and by fine-tuning pre-trained contextualized encoders. We release the annotated dataset for open access.