 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergizing Contrastive Learning and Optimal Transport for 3D Point Cloud Domain Adaptation
Aug 27, 2023



Recently, the fundamental problem of unsupervised domain adaptation (UDA) on 3D point clouds has been motivated by a wide variety of applications in robotics, virtual reality, and scene understanding, to name a few. The point cloud data acquisition procedures manifest themselves as significant domain discrepancies and geometric variations among both similar and dissimilar classes. The standard domain adaptation methods developed for images do not directly translate to point cloud data because of their complex geometric nature. To address this challenge, we leverage the idea of multimodality and alignment between distributions. We propose a new UDA architecture for point cloud classification that benefits from multimodal contrastive learning to get better class separation in both domains individually. Further, the use of optimal transport (OT) aims at learning source and target data distributions jointly to reduce the cross-domain shift and provide a better alignment. We conduct a comprehensive empirical study on PointDA-10 and GraspNetPC-10 and show that our method achieves state-of-the-art performance on GraspNetPC-10 (with approx 4-12% margin) and best average performance on PointDA-10. Our ablation studies and decision boundary analysis also validate the significance of our contrastive learning module and OT alignment.
ABD-Net: Attention Based Decomposition Network for 3D Point Cloud Decomposition
Jul 09, 2021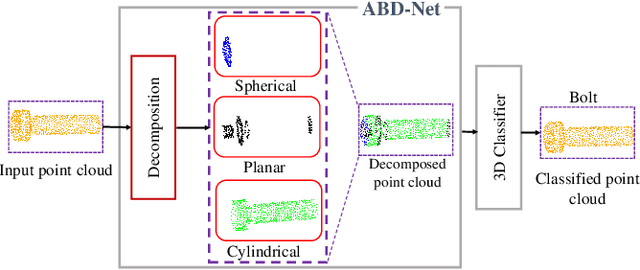
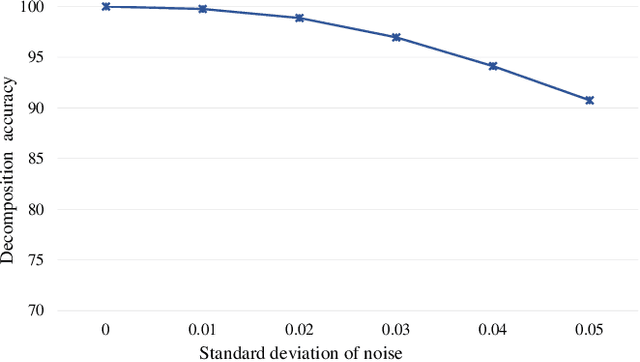
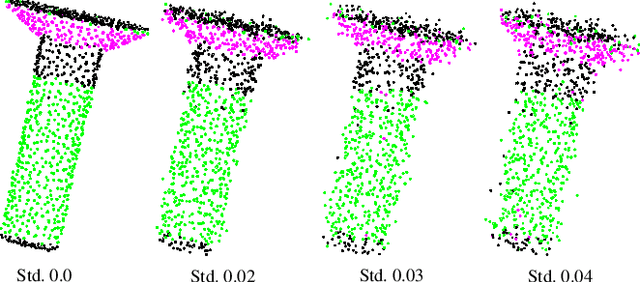
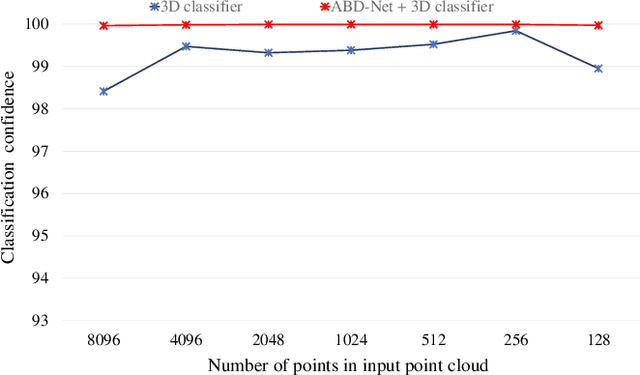
In this paper, we propose Attention Based Decomposition Network (ABD-Net), for point cloud decomposition into basic geometric shapes namely, plane, sphere, cone and cylinder. We show improved performance of 3D object classification using attention features based on primitive shapes in point clouds. Point clouds, being the simple and compact representation of 3D objects have gained increasing popularity. They demand robust methods for feature extraction due to unorderness in point sets. In ABD-Net the proposed Local Proximity Encapsulator captures the local geometric variations along with spatial encoding around each point from the input point sets. The encapsulated local features are further passed to proposed Attention Feature Encoder to learn basic shapes in point cloud. Attention Feature Encoder models geometric relationship between the neighborhoods of all the points resulting in capturing global point cloud information. We demonstrate the results of our proposed ABD-Net on ANSI mechanical component and ModelNet40 datasets. We also demonstrate the effectiveness of ABD-Net over the acquired attention features by improving the performance of 3D object classification on ModelNet40 benchmark dataset and compare them with state-of-the-art techniques.