 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024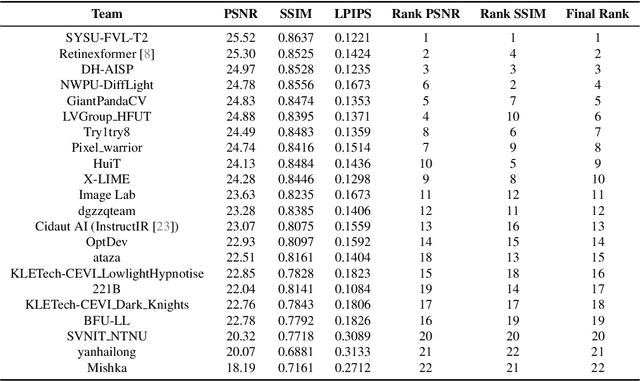


This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024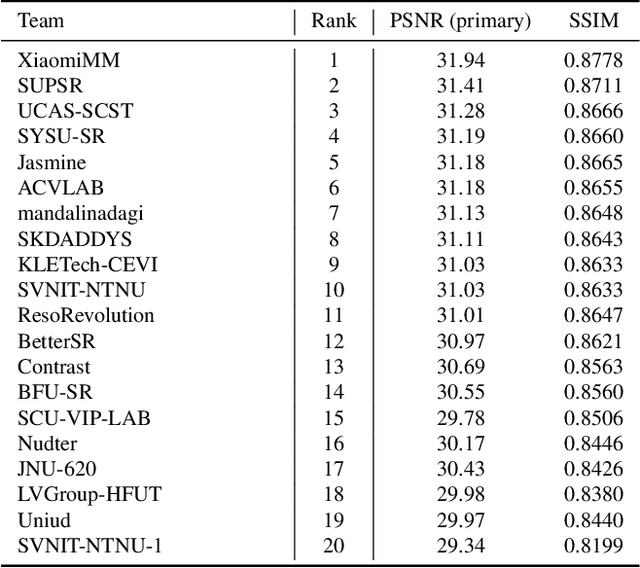
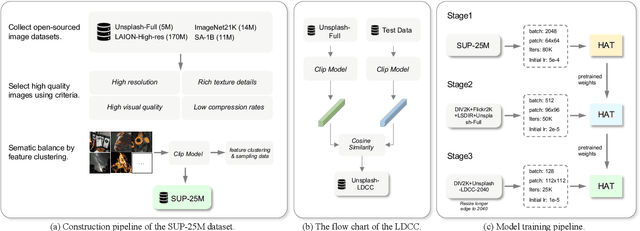
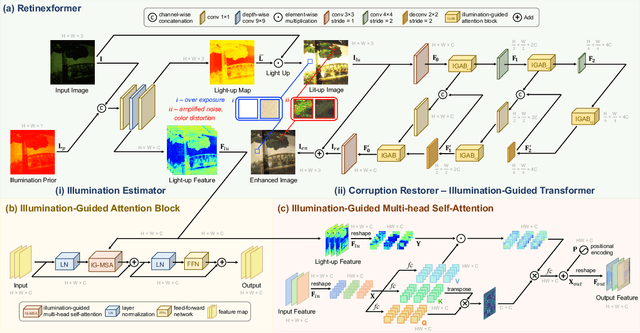
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
PointCLIMB: An Exemplar-Free Point Cloud Class Incremental Benchmark
Apr 13, 2023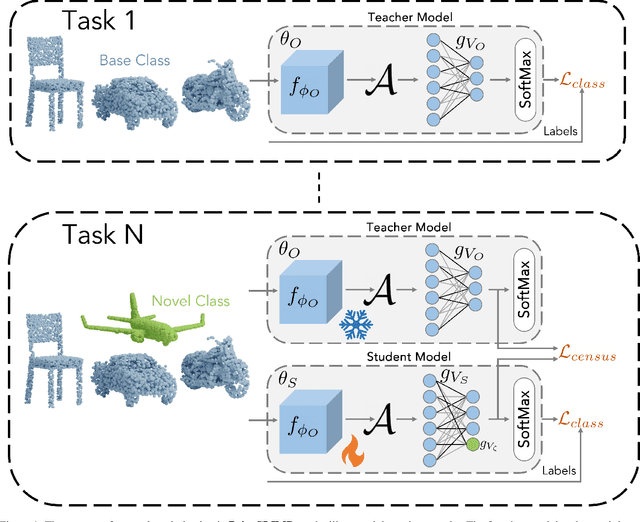
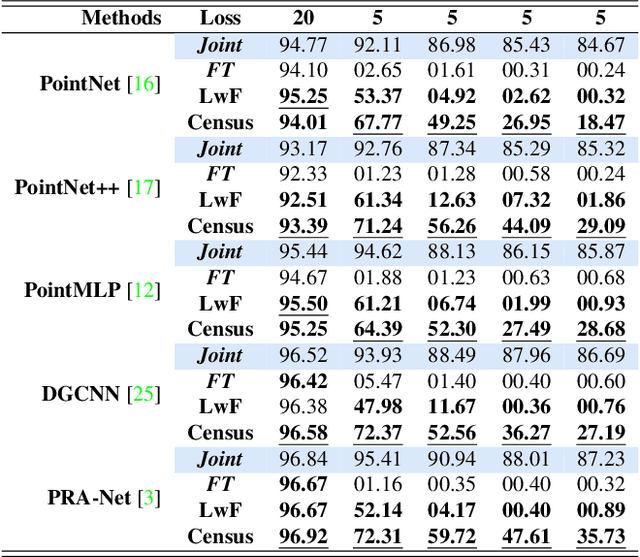


Point clouds offer comprehensive and precise data regarding the contour and configuration of objects. Employing such geometric and topological 3D information of objects in class incremental learning can aid endless application in 3D-computer vision. Well known 3D-point cloud class incremental learning methods for addressing catastrophic forgetting generally entail the usage of previously encountered data, which can present difficulties in situations where there are restrictions on memory or when there are concerns about the legality of the data. Towards this we pioneer to leverage exemplar free class incremental learning on Point Clouds. In this paper we propose PointCLIMB: An exemplar Free Class Incremental Learning Benchmark. We focus on a pragmatic perspective to consider novel classes for class incremental learning on 3D point clouds. We setup a benchmark for 3D Exemplar free class incremental learning. We investigate performance of various backbones on 3D-Exemplar Free Class Incremental Learning framework. We demonstrate our results on ModelNet40 dataset.
ABD-Net: Attention Based Decomposition Network for 3D Point Cloud Decomposition
Jul 09, 2021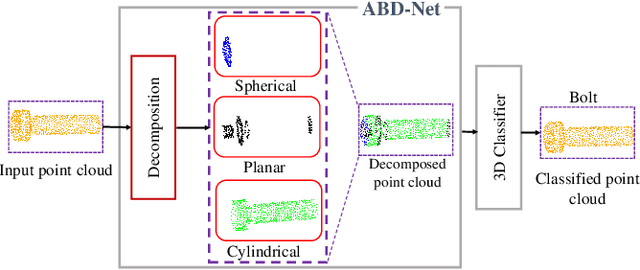
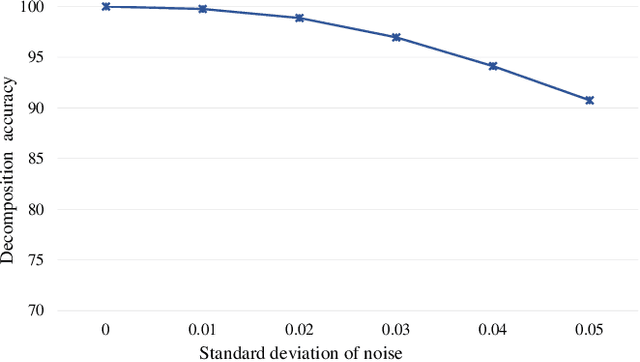
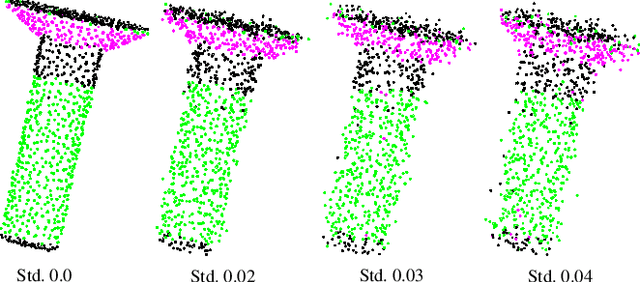
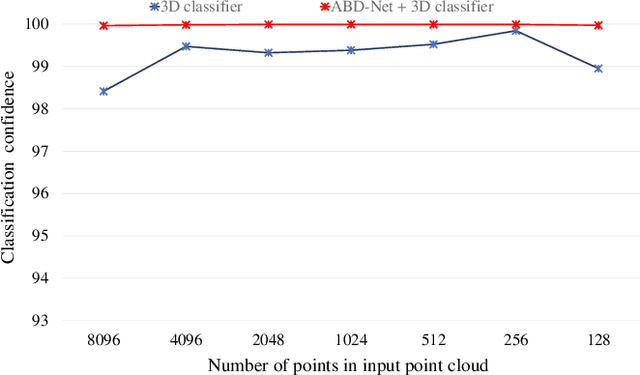
In this paper, we propose Attention Based Decomposition Network (ABD-Net), for point cloud decomposition into basic geometric shapes namely, plane, sphere, cone and cylinder. We show improved performance of 3D object classification using attention features based on primitive shapes in point clouds. Point clouds, being the simple and compact representation of 3D objects have gained increasing popularity. They demand robust methods for feature extraction due to unorderness in point sets. In ABD-Net the proposed Local Proximity Encapsulator captures the local geometric variations along with spatial encoding around each point from the input point sets. The encapsulated local features are further passed to proposed Attention Feature Encoder to learn basic shapes in point cloud. Attention Feature Encoder models geometric relationship between the neighborhoods of all the points resulting in capturing global point cloud information. We demonstrate the results of our proposed ABD-Net on ANSI mechanical component and ModelNet40 datasets. We also demonstrate the effectiveness of ABD-Net over the acquired attention features by improving the performance of 3D object classification on ModelNet40 benchmark dataset and compare them with state-of-the-art techniques.
Augmented Data as an Auxiliary Plug-in Towards Categorization of Crowdsourced Heritage Data
Jul 08, 2021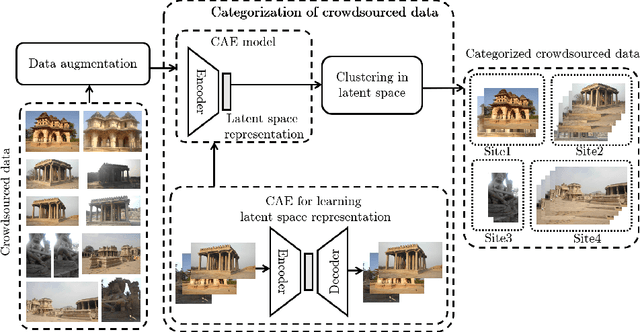
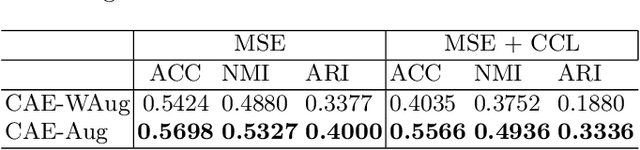
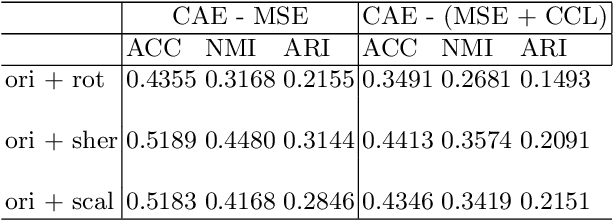
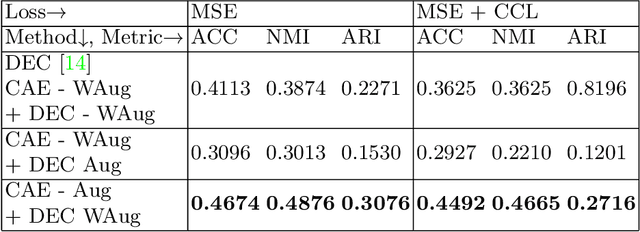
In this paper, we propose a strategy to mitigate the problem of inefficient clustering performance by introducing data augmentation as an auxiliary plug-in. Classical clustering techniques such as K-means, Gaussian mixture model and spectral clustering are central to many data-driven applications. However, recently unsupervised simultaneous feature learning and clustering using neural networks also known as Deep Embedded Clustering (DEC) has gained prominence. Pioneering works on deep feature clustering focus on defining relevant clustering loss function and choosing the right neural network for extracting features. A central problem in all these cases is data sparsity accompanied by high intra-class and low inter-class variance, which subsequently leads to poor clustering performance and erroneous candidate assignments. Towards this, we employ data augmentation techniques to improve the density of the clusters, thus improving the overall performance. We train a variant of Convolutional Autoencoder (CAE) with augmented data to construct the initial feature space as a novel model for deep clustering. We demonstrate the results of proposed strategy on crowdsourced Indian Heritage dataset. Extensive experiments show consistent improvements over existing works.
Deep Visual Attention-Based Transfer Clustering
Jul 06, 2021
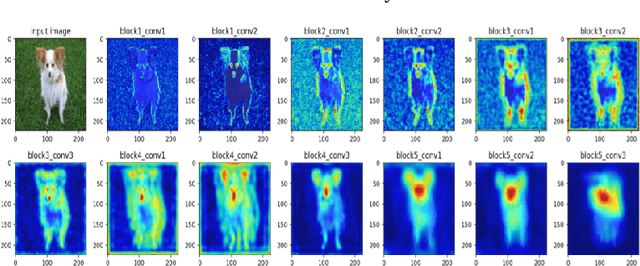
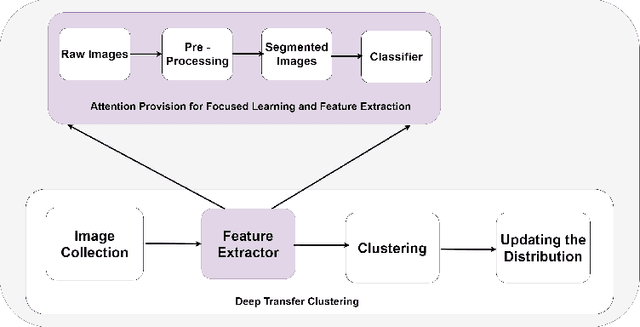
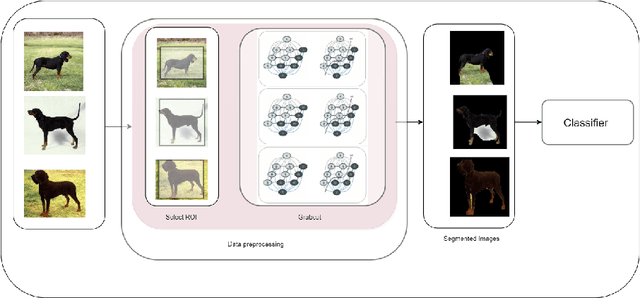
In this paper, we propose a methodology to improvise the technique of deep transfer clustering (DTC) when applied to the less variant data distribution. Clustering can be considered as the most important unsupervised learning problem. A simple definition of clustering can be stated as "the process of organizing objects into groups, whose members are similar in some way". Image clustering is a crucial but challenging task in the domain machine learning and computer vision. We have discussed the clustering of the data collection where the data is less variant. We have discussed the improvement by using attention-based classifiers rather than regular classifiers as the initial feature extractors in the deep transfer clustering. We have enforced the model to learn only the required region of interest in the images to get the differentiable and robust features that do not take into account the background. This paper is the improvement of the existing deep transfer clustering for less variant data distribution.