 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Data as an Auxiliary Plug-in Towards Categorization of Crowdsourced Heritage Data
Paper and Code
Jul 08, 2021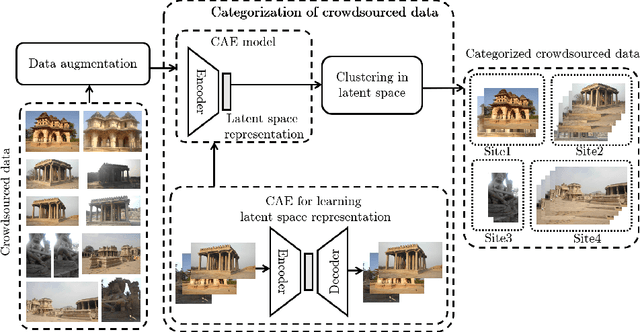
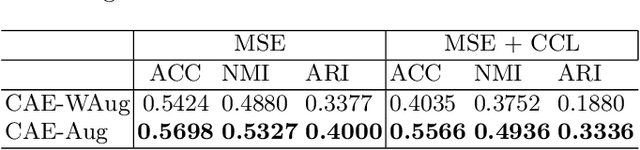
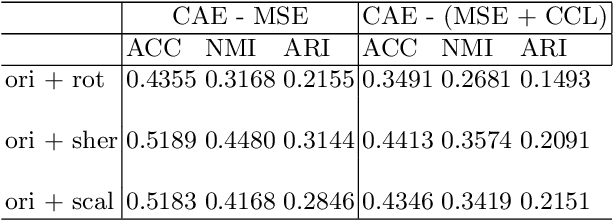
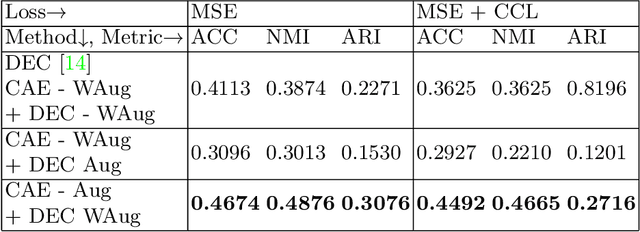
In this paper, we propose a strategy to mitigate the problem of inefficient clustering performance by introducing data augmentation as an auxiliary plug-in. Classical clustering techniques such as K-means, Gaussian mixture model and spectral clustering are central to many data-driven applications. However, recently unsupervised simultaneous feature learning and clustering using neural networks also known as Deep Embedded Clustering (DEC) has gained prominence. Pioneering works on deep feature clustering focus on defining relevant clustering loss function and choosing the right neural network for extracting features. A central problem in all these cases is data sparsity accompanied by high intra-class and low inter-class variance, which subsequently leads to poor clustering performance and erroneous candidate assignments. Towards this, we employ data augmentation techniques to improve the density of the clusters, thus improving the overall performance. We train a variant of Convolutional Autoencoder (CAE) with augmented data to construct the initial feature space as a novel model for deep clustering. We demonstrate the results of proposed strategy on crowdsourced Indian Heritage dataset. Extensive experiments show consistent improvements over existing works.