 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization in Graph Neural Networks
Aug 26, 2025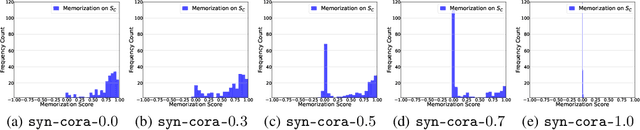

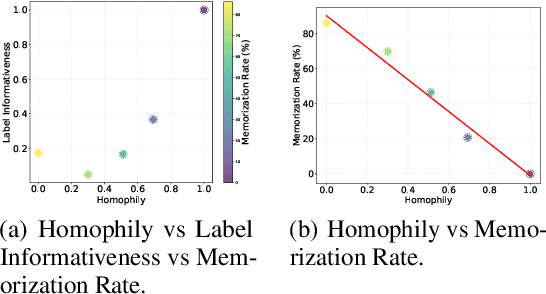
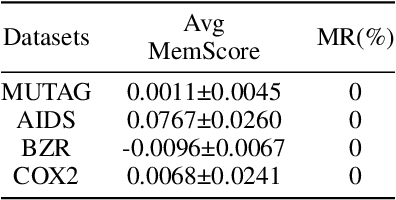
Deep neural networks (DNNs) have been shown to memorize their training data, yet similar analyses for graph neural networks (GNNs) remain largely under-explored. We introduce NCMemo (Node Classification Memorization), the first framework to quantify label memorization in semi-supervised node classification. We first establish an inverse relationship between memorization and graph homophily, i.e., the property that connected nodes share similar labels/features. We find that lower homophily significantly increases memorization, indicating that GNNs rely on memorization to learn less homophilic graphs. Secondly, we analyze GNN training dynamics. We find that the increased memorization in low homophily graphs is tightly coupled to the GNNs' implicit bias on using graph structure during learning. In low homophily regimes, this structure is less informative, hence inducing memorization of the node labels to minimize training loss. Finally, we show that nodes with higher label inconsistency in their feature-space neighborhood are significantly more prone to memorization. Building on our insights into the link between graph homophily and memorization, we investigate graph rewiring as a means to mitigate memorization. Our results demonstrate that this approach effectively reduces memorization without compromising model performance. Moreover, we show that it lowers the privacy risk for previously memorized data points in practice. Thus, our work not only advances understanding of GNN learning but also supports more privacy-preserving GNN deployment.
GNNs Getting ComFy: Community and Feature Similarity Guided Rewiring
Feb 07, 2025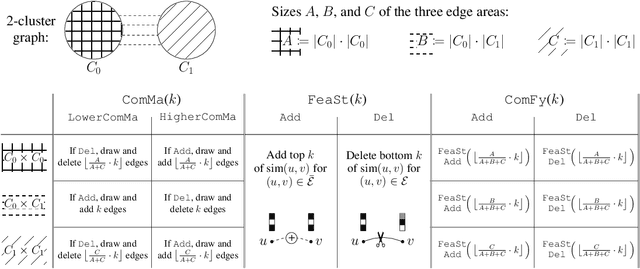
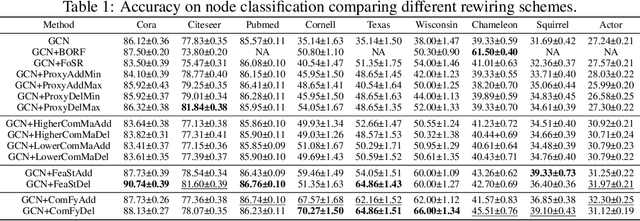
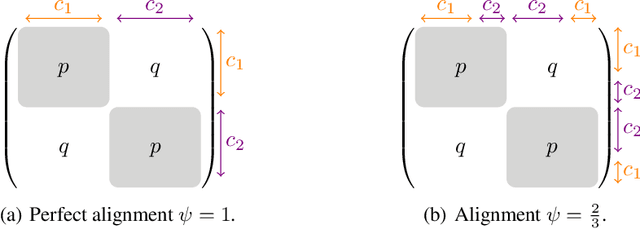
Maximizing the spectral gap through graph rewiring has been proposed to enhance the performance of message-passing graph neural networks (GNNs) by addressing over-squashing. However, as we show, minimizing the spectral gap can also improve generalization. To explain this, we analyze how rewiring can benefit GNNs within the context of stochastic block models. Since spectral gap optimization primarily influences community strength, it improves performance when the community structure aligns with node labels. Building on this insight, we propose three distinct rewiring strategies that explicitly target community structure, node labels, and their alignment: (a) community structure-based rewiring (ComMa), a more computationally efficient alternative to spectral gap optimization that achieves similar goals; (b) feature similarity-based rewiring (FeaSt), which focuses on maximizing global homophily; and (c) a hybrid approach (ComFy), which enhances local feature similarity while preserving community structure to optimize label-community alignment. Extensive experiments confirm the effectiveness of these strategies and support our theoretical insights.
Spectral Graph Pruning Against Over-Squashing and Over-Smoothing
Apr 06, 2024



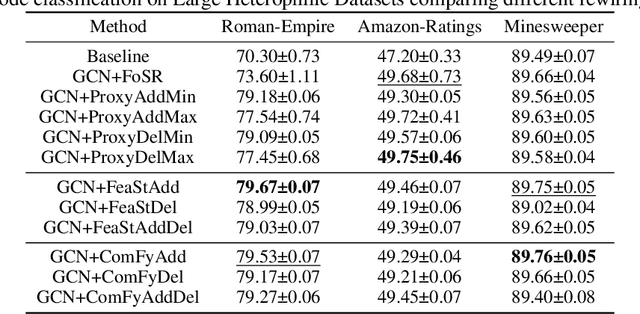
Message Passing Graph Neural Networks are known to suffer from two problems that are sometimes believed to be diametrically opposed: over-squashing and over-smoothing. The former results from topological bottlenecks that hamper the information flow from distant nodes and are mitigated by spectral gap maximization, primarily, by means of edge additions. However, such additions often promote over-smoothing that renders nodes of different classes less distinguishable. Inspired by the Braess phenomenon, we argue that deleting edges can address over-squashing and over-smoothing simultaneously. This insight explains how edge deletions can improve generalization, thus connecting spectral gap optimization to a seemingly disconnected objective of reducing computational resources by pruning graphs for lottery tickets. To this end, we propose a more effective spectral gap optimization framework to add or delete edges and demonstrate its effectiveness on large heterophilic datasets.
Augmented Data as an Auxiliary Plug-in Towards Categorization of Crowdsourced Heritage Data
Jul 08, 2021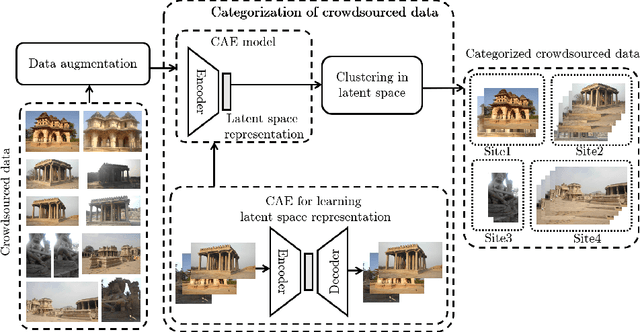
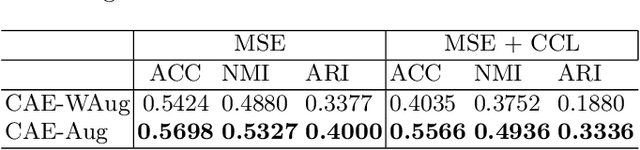
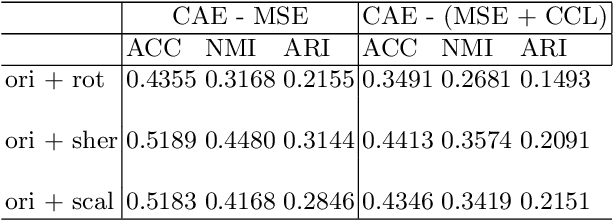
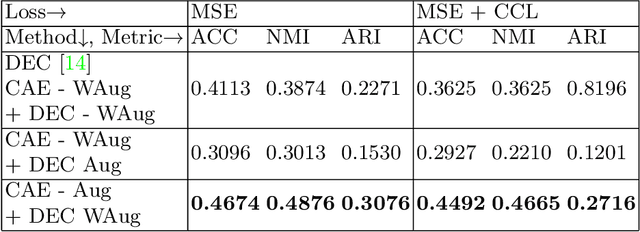
In this paper, we propose a strategy to mitigate the problem of inefficient clustering performance by introducing data augmentation as an auxiliary plug-in. Classical clustering techniques such as K-means, Gaussian mixture model and spectral clustering are central to many data-driven applications. However, recently unsupervised simultaneous feature learning and clustering using neural networks also known as Deep Embedded Clustering (DEC) has gained prominence. Pioneering works on deep feature clustering focus on defining relevant clustering loss function and choosing the right neural network for extracting features. A central problem in all these cases is data sparsity accompanied by high intra-class and low inter-class variance, which subsequently leads to poor clustering performance and erroneous candidate assignments. Towards this, we employ data augmentation techniques to improve the density of the clusters, thus improving the overall performance. We train a variant of Convolutional Autoencoder (CAE) with augmented data to construct the initial feature space as a novel model for deep clustering. We demonstrate the results of proposed strategy on crowdsourced Indian Heritage dataset. Extensive experiments show consistent improvements over existing works.
Deep Visual Attention-Based Transfer Clustering
Jul 06, 2021
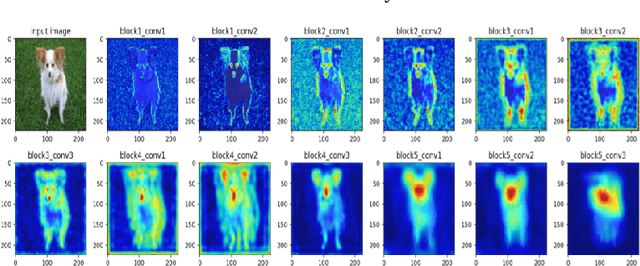
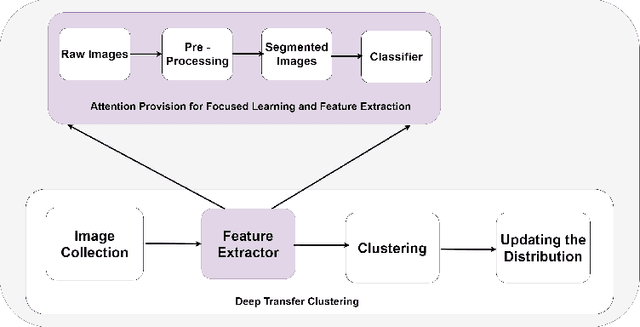
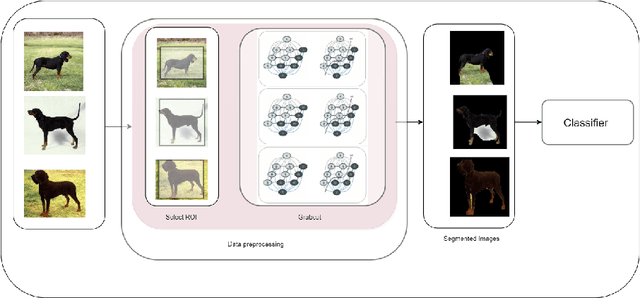
In this paper, we propose a methodology to improvise the technique of deep transfer clustering (DTC) when applied to the less variant data distribution. Clustering can be considered as the most important unsupervised learning problem. A simple definition of clustering can be stated as "the process of organizing objects into groups, whose members are similar in some way". Image clustering is a crucial but challenging task in the domain machine learning and computer vision. We have discussed the clustering of the data collection where the data is less variant. We have discussed the improvement by using attention-based classifiers rather than regular classifiers as the initial feature extractors in the deep transfer clustering. We have enforced the model to learn only the required region of interest in the images to get the differentiable and robust features that do not take into account the background. This paper is the improvement of the existing deep transfer clustering for less variant data distribution.