 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Reviews Disagree: Fine-Grained Contradiction Analysis in Scientific Peer Reviews
May 11, 2026Scientific peer reviews frequently contain conflicting expert judgments, and the increasing scale of conference submissions makes it challenging for Area Chairs and editors to reliably identify and interpret such disagreements. Existing approaches typically frame reviewer disagreement as binary contradiction detection over isolated sentence pairs, abstracting away the review-level context and obscuring differences in the severity of evaluative conflict. In this work, we introduce a fine-grained formulation of reviewer contradiction analysis that operates over full peer reviews by explicitly identifying contradiction evidence spans and assigning graded disagreement intensity scores. To support this task, we present RevCI, an expert-annotated benchmark of peer-review pairs with evidence-level contradiction annotations with graded intensity labels. We further propose IMPACT, a structured multi-agent framework that integrates aspect-conditioned evidence extraction, deliberative reasoning, and adjudication to model reviewer contradictions and their intensity. To support efficient deployment, we distill IMPACT into TIDE, a small language model that predicts contradiction evidence and intensity in a single forward pass. Experimental results show that IMPACT substantially outperforms strong single-agent and generic multi-agent baselines in both evidence identification and intensity agreement, while TIDE achieves competitive performance at significantly lower inference cost.
COVIDRead: A Large-scale Question Answering Dataset on COVID-19
Oct 05, 2021

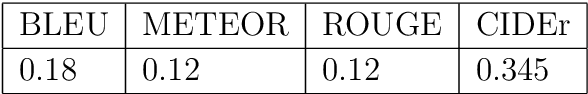

During this pandemic situation, extracting any relevant information related to COVID-19 will be immensely beneficial to the community at large. In this paper, we present a very important resource, COVIDRead, a Stanford Question Answering Dataset (SQuAD) like dataset over more than 100k question-answer pairs. The dataset consists of Context-Answer-Question triples. Primarily the questions from the context are constructed in an automated way. After that, the system-generated questions are manually checked by hu-mans annotators. This is a precious resource that could serve many purposes, ranging from common people queries regarding this very uncommon disease to managing articles by editors/associate editors of a journal. We establish several end-to-end neural network based baseline models that attain the lowest F1 of 32.03% and the highest F1 of 37.19%. To the best of our knowledge, we are the first to provide this kind of QA dataset in such a large volume on COVID-19. This dataset creates a new avenue of carrying out research on COVID-19 by providing a benchmark dataset and a baseline model.
IITP at AILA 2019: System Report for Artificial Intelligence for Legal Assistance Shared Task
May 24, 2021
In this article, we present a description of our systems as a part of our participation in the shared task namely Artificial Intelligence for Legal Assistance (AILA 2019). This is an integral event of Forum for Information Retrieval Evaluation-2019. The outcomes of this track would be helpful for the automation of the working process of the Indian Judiciary System. The manual working procedures and documentation at any level (from lower to higher court) of the judiciary system are very complex in nature. The systems produced as a part of this track would assist the law practitioners. It would be helpful for common men too. This kind of track also opens the path of research of Natural Language Processing (NLP) in the judicial domain. This track defined two problems such as Task 1: Identifying relevant prior cases for a given situation and Task 2: Identifying the most relevant statutes for a given situation. We tackled both of them. Our proposed approaches are based on BM25 and Doc2Vec. As per the results declared by the task organizers, we are in 3rd and a modest position in Task 1 and Task 2 respectively.
IITP in COLIEE@ICAIL 2019: Legal Information Retrieval using BM25 and BERT
Apr 29, 2021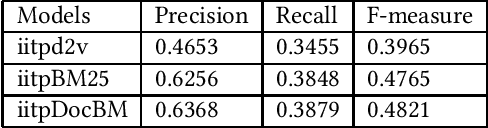
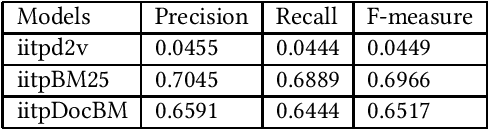
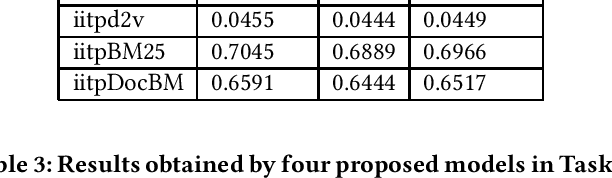
Natural Language Processing (NLP) and Information Retrieval (IR) in the judicial domain is an essential task. With the advent of availability domain-specific data in electronic form and aid of different Artificial intelligence (AI) technologies, automated language processing becomes more comfortable, and hence it becomes feasible for researchers and developers to provide various automated tools to the legal community to reduce human burden. The Competition on Legal Information Extraction/Entailment (COLIEE-2019) run in association with the International Conference on Artificial Intelligence and Law (ICAIL)-2019 has come up with few challenging tasks. The shared defined four sub-tasks (i.e. Task1, Task2, Task3 and Task4), which will be able to provide few automated systems to the judicial system. The paper presents our working note on the experiments carried out as a part of our participation in all the sub-tasks defined in this shared task. We make use of different Information Retrieval(IR) and deep learning based approaches to tackle these problems. We obtain encouraging results in all these four sub-tasks.
A Deep Learning Approach for Automatic Detection of Fake News
May 11, 2020
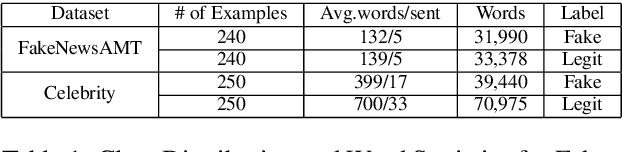
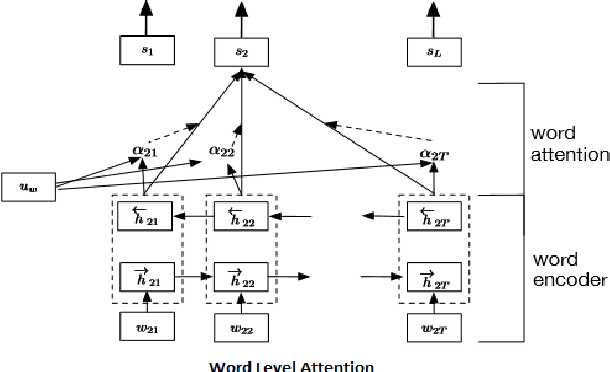
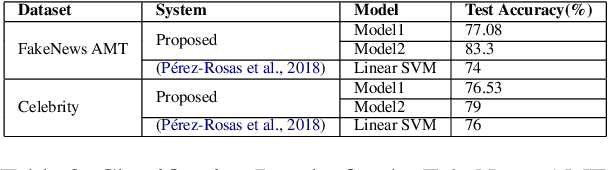
Fake news detection is a very prominent and essential task in the field of journalism. This challenging problem is seen so far in the field of politics, but it could be even more challenging when it is to be determined in the multi-domain platform. In this paper, we propose two effective models based on deep learning for solving fake news detection problem in online news contents of multiple domains. We evaluate our techniques on the two recently released datasets, namely FakeNews AMT and Celebrity for fake news detection. The proposed systems yield encouraging performance, outperforming the current handcrafted feature engineering based state-of-the-art system with a significant margin of 3.08% and 9.3% by the two models, respectively. In order to exploit the datasets, available for the related tasks, we perform cross-domain analysis (i.e. model trained on FakeNews AMT and tested on Celebrity and vice versa) to explore the applicability of our systems across the domains.
IITP at MEDIQA 2019: Systems Report for Natural Language Inference, Question Entailment and Question Answering
Jun 14, 2019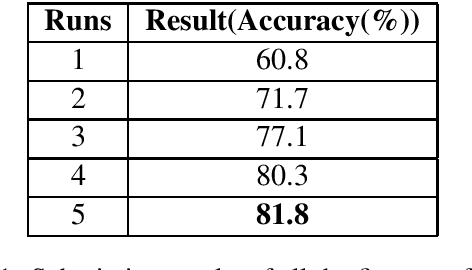
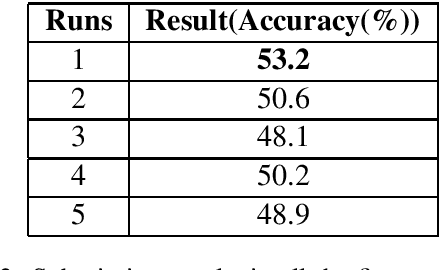
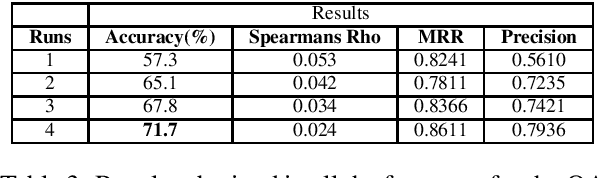
This paper presents the experiments accomplished as a part of our participation in the MEDIQA challenge, an (Abacha et al., 2019) shared task. We participated in all the three tasks defined in this particular shared task. The tasks are viz. i. Natural Language Inference (NLI) ii. Recognizing Question Entailment(RQE) and their application in medical Question Answering (QA). We submitted runs using multiple deep learning based systems (runs) for each of these three tasks. We submitted five system results in each of the NLI and RQE tasks, and four system results for the QA task. The systems yield encouraging results in all three tasks. The highest performance obtained in NLI, RQE and QA tasks are 81.8%, 53.2%, and 71.7%, respectively.