 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVIDRead: A Large-scale Question Answering Dataset on COVID-19
Paper and Code


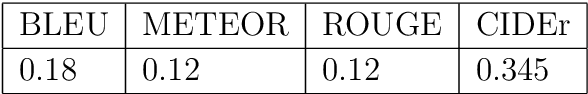

During this pandemic situation, extracting any relevant information related to COVID-19 will be immensely beneficial to the community at large. In this paper, we present a very important resource, COVIDRead, a Stanford Question Answering Dataset (SQuAD) like dataset over more than 100k question-answer pairs. The dataset consists of Context-Answer-Question triples. Primarily the questions from the context are constructed in an automated way. After that, the system-generated questions are manually checked by hu-mans annotators. This is a precious resource that could serve many purposes, ranging from common people queries regarding this very uncommon disease to managing articles by editors/associate editors of a journal. We establish several end-to-end neural network based baseline models that attain the lowest F1 of 32.03% and the highest F1 of 37.19%. To the best of our knowledge, we are the first to provide this kind of QA dataset in such a large volume on COVID-19. This dataset creates a new avenue of carrying out research on COVID-19 by providing a benchmark dataset and a baseline model.