 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Object Detection with Pseudo Labels from VLMs using Per-Object Co-teaching
Nov 13, 2025



Foundation models, especially vision-language models (VLMs), offer compelling zero-shot object detection for applications like autonomous driving, a domain where manual labelling is prohibitively expensive. However, their detection latency and tendency to hallucinate predictions render them unsuitable for direct deployment. This work introduces a novel pipeline that addresses this challenge by leveraging VLMs to automatically generate pseudo-labels for training efficient, real-time object detectors. Our key innovation is a per-object co-teaching-based training strategy that mitigates the inherent noise in VLM-generated labels. The proposed per-object coteaching approach filters noisy bounding boxes from training instead of filtering the entire image. Specifically, two YOLO models learn collaboratively, filtering out unreliable boxes from each mini-batch based on their peers' per-object loss values. Overall, our pipeline provides an efficient, robust, and scalable approach to train high-performance object detectors for autonomous driving, significantly reducing reliance on costly human annotation. Experimental results on the KITTI dataset demonstrate that our method outperforms a baseline YOLOv5m model, achieving a significant mAP@0.5 boost ($31.12\%$ to $46.61\%$) while maintaining real-time detection latency. Furthermore, we show that supplementing our pseudo-labelled data with a small fraction of ground truth labels ($10\%$) leads to further performance gains, reaching $57.97\%$ mAP@0.5 on the KITTI dataset. We observe similar performance improvements for the ACDC and BDD100k datasets.
Optimal Strategies for Federated Learning Maintaining Client Privacy
Jan 24, 2025



Federated Learning (FL) emerged as a learning method to enable the server to train models over data distributed among various clients. These clients are protective about their data being leaked to the server, any other client, or an external adversary, and hence, locally train the model and share it with the server rather than sharing the data. The introduction of sophisticated inferencing attacks enabled the leakage of information about data through access to model parameters. To tackle this challenge, privacy-preserving federated learning aims to achieve differential privacy through learning algorithms like DP-SGD. However, such methods involve adding noise to the model, data, or gradients, reducing the model's performance. This work provides a theoretical analysis of the tradeoff between model performance and communication complexity of the FL system. We formally prove that training for one local epoch per global round of training gives optimal performance while preserving the same privacy budget. We also investigate the change of utility (tied to privacy) of FL models with a change in the number of clients and observe that when clients are training using DP-SGD and argue that for the same privacy budget, the utility improved with increased clients. We validate our findings through experiments on real-world datasets. The results from this paper aim to improve the performance of privacy-preserving federated learning systems.
Node Classification With Integrated Reject Option
Dec 04, 2024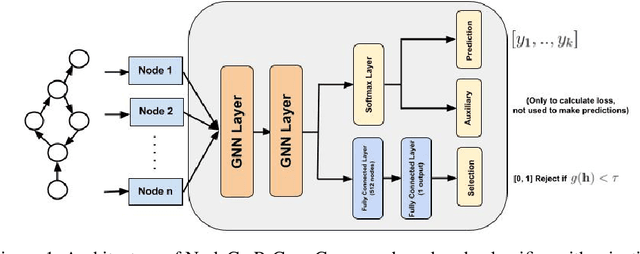
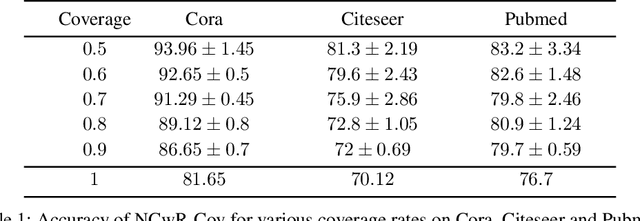
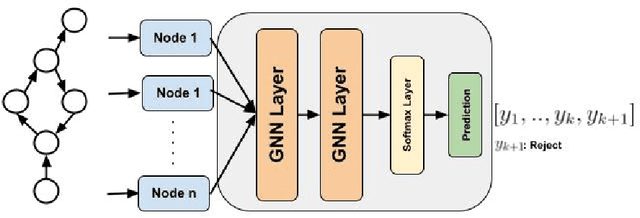
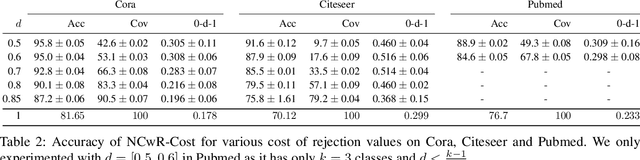
One of the key tasks in graph learning is node classification. While Graph neural networks have been used for various applications, their adaptivity to reject option setting is not previously explored. In this paper, we propose NCwR, a novel approach to node classification in Graph Neural Networks (GNNs) with an integrated reject option, which allows the model to abstain from making predictions when uncertainty is high. We propose both cost-based and coverage-based methods for classification with abstention in node classification setting using GNNs. We perform experiments using our method on three standard citation network datasets Cora, Citeseer and Pubmed and compare with relevant baselines. We also model the Legal judgment prediction problem on ILDC dataset as a node classification problem where nodes represent legal cases and edges represent citations. We further interpret the model by analyzing the cases that the model abstains from predicting by visualizing which part of the input features influenced this decision.