 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Collective Dynamics of Multi-Agent Systems using Event-based Vision
Nov 11, 2024This paper proposes a novel problem: vision-based perception to learn and predict the collective dynamics of multi-agent systems, specifically focusing on interaction strength and convergence time. Multi-agent systems are defined as collections of more than ten interacting agents that exhibit complex group behaviors. Unlike prior studies that assume knowledge of agent positions, we focus on deep learning models to directly predict collective dynamics from visual data, captured as frames or events. Due to the lack of relevant datasets, we create a simulated dataset using a state-of-the-art flocking simulator, coupled with a vision-to-event conversion framework. We empirically demonstrate the effectiveness of event-based representation over traditional frame-based methods in predicting these collective behaviors. Based on our analysis, we present event-based vision for Multi-Agent dynamic Prediction (evMAP), a deep learning architecture designed for real-time, accurate understanding of interaction strength and collective behavior emergence in multi-agent systems.
Learning Locally Interacting Discrete Dynamical Systems: Towards Data-Efficient and Scalable Prediction
Apr 09, 2024



Locally interacting dynamical systems, such as epidemic spread, rumor propagation through crowd, and forest fire, exhibit complex global dynamics originated from local, relatively simple, and often stochastic interactions between dynamic elements. Their temporal evolution is often driven by transitions between a finite number of discrete states. Despite significant advancements in predictive modeling through deep learning, such interactions among many elements have rarely explored as a specific domain for predictive modeling. We present Attentive Recurrent Neural Cellular Automata (AR-NCA), to effectively discover unknown local state transition rules by associating the temporal information between neighboring cells in a permutation-invariant manner. AR-NCA exhibits the superior generalizability across various system configurations (i.e., spatial distribution of states), data efficiency and robustness in extremely data-limited scenarios even in the presence of stochastic interactions, and scalability through spatial dimension-independent prediction.
Forecasting local behavior of multi-agent system and its application to forest fire model
Oct 28, 2022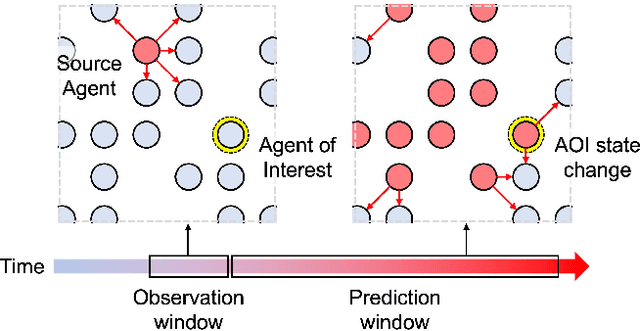
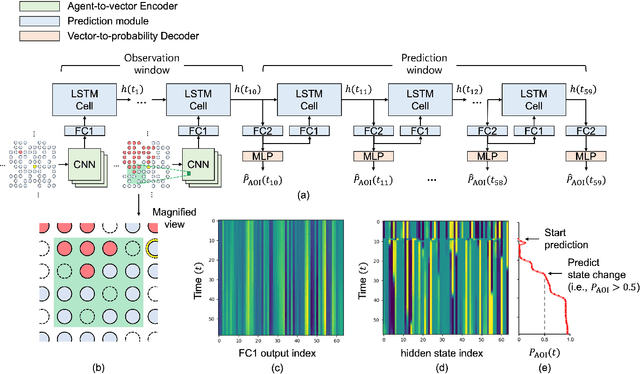
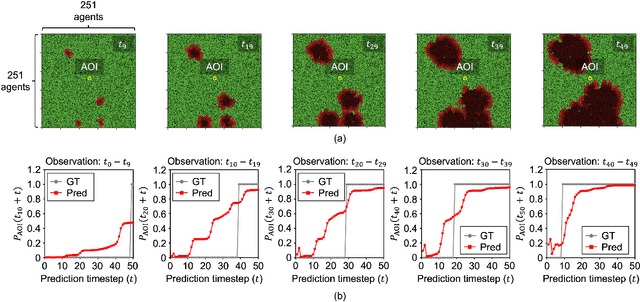
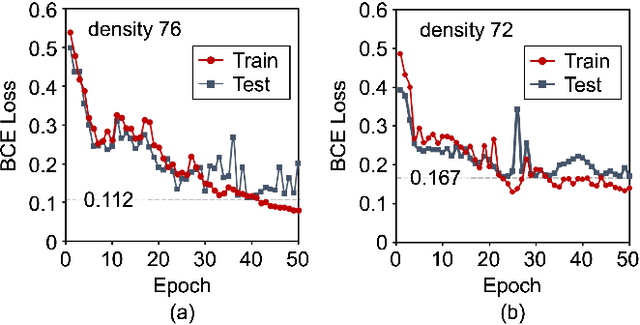
In this paper, we study a CNN-LSTM model to forecast the state of a specific agent in a large multi-agent system. The proposed model consists of a CNN encoder to represent the system into a low-dimensional vector, a LSTM module to learn the agent dynamics in the vector space, and a MLP decoder to predict the future state of an agent. A forest fire model is considered as an example where we need to predict when a specific tree agent will be burning. We observe that the proposed model achieves higher AUC with less computation than a frame-based model and significantly saves computational costs such as the activation than ConvLSTM.
Mixture of Pre-processing Experts Model for Noise Robust Deep Learning on Resource Constrained Platforms
Apr 29, 2019
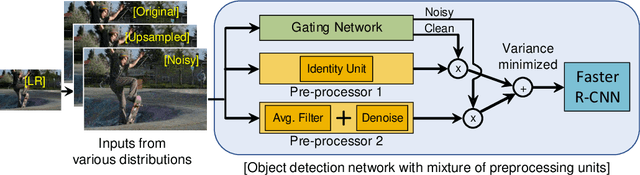


Deep learning on an edge device requires energy efficient operation due to ever diminishing power budget. Intentional low quality data during the data acquisition for longer battery life, and natural noise from the low cost sensor degrade the quality of target output which hinders adoption of deep learning on an edge device. To overcome these problems, we propose simple yet efficient mixture of pre-processing experts (MoPE) model to handle various image distortions including low resolution and noisy images. We also propose to use adversarially trained auto encoder as a pre-processing expert for the noisy images. We evaluate our proposed method for various machine learning tasks including object detection on MS-COCO 2014 dataset, multiple object tracking problem on MOT-Challenge dataset, and human activity classification on UCF 101 dataset. Experimental results show that the proposed method achieves better detection, tracking and activity classification accuracies under noise without sacrificing accuracies for the clean images. The overheads of our proposed MoPE are 0.67% and 0.17% in terms of memory and computation compared to the baseline object detection network.