 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADNet: A Deep Neural Network Model for Robust Perception in Moving Autonomous Systems
Apr 30, 2022

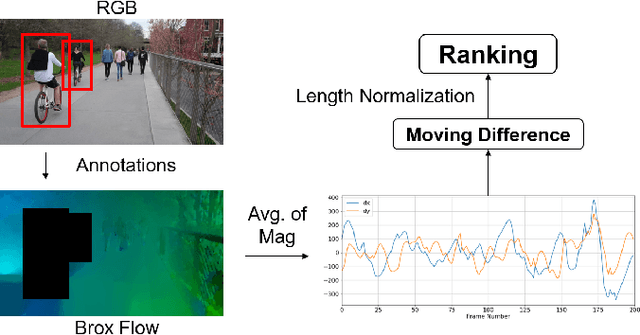
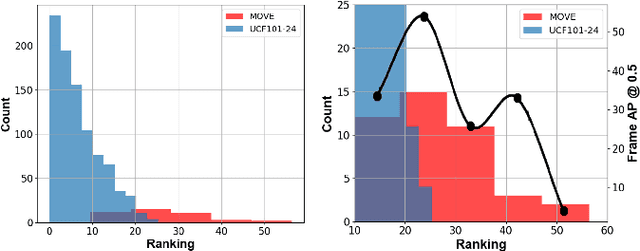
Interactive autonomous applications require robustness of the perception engine to artifacts in unconstrained videos. In this paper, we examine the effect of camera motion on the task of action detection. We develop a novel ranking method to rank videos based on the degree of global camera motion. For the high ranking camera videos we show that the accuracy of action detection is decreased. We propose an action detection pipeline that is robust to the camera motion effect and verify it empirically. Specifically, we do actor feature alignment across frames and couple global scene features with local actor-specific features. We do feature alignment using a novel formulation of the Spatio-temporal Sampling Network (STSN) but with multi-scale offset prediction and refinement using a pyramid structure. We also propose a novel input dependent weighted averaging strategy for fusing local and global features. We show the applicability of our network on our dataset of moving camera videos with high camera motion (MOVE dataset) with a 4.1% increase in frame mAP and 17% increase in video mAP.
MagNet: Discovering Multi-agent Interaction Dynamics using Neural Network
Mar 03, 2020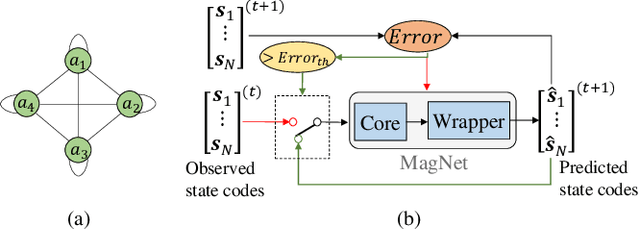
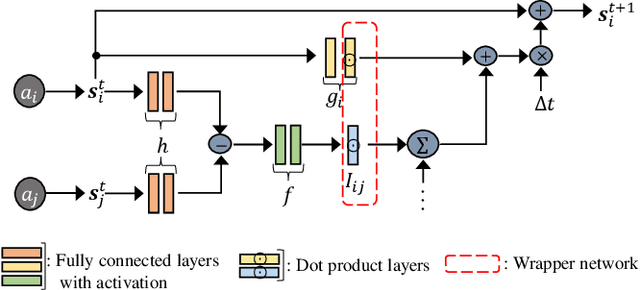
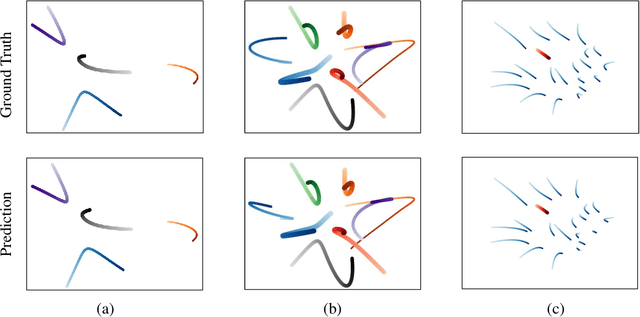
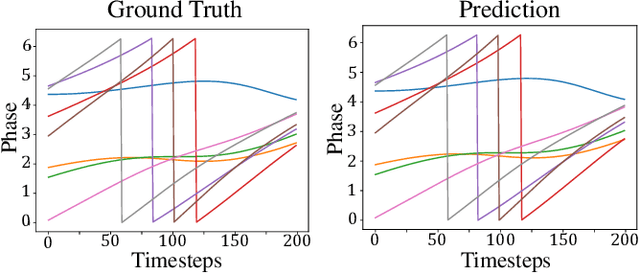
We present the MagNet, a neural network-based multi-agent interaction model to discover the governing dynamics and predict evolution of a complex multi-agent system from observations. We formulate a multi-agent system as a coupled non-linear network with a generic ordinary differential equation (ODE) based state evolution, and develop a neural network-based realization of its time-discretized model. MagNet is trained to discover the core dynamics of a multi-agent system from observations, and tuned on-line to learn agent-specific parameters of the dynamics to ensure accurate prediction even when physical or relational attributes of agents, or number of agents change. We evaluate MagNet on a point-mass system in two-dimensional space, Kuramoto phase synchronization dynamics and predator-swarm interaction dynamics demonstrating orders of magnitude improvement in prediction accuracy over traditional deep learning models.
Mixture of Pre-processing Experts Model for Noise Robust Deep Learning on Resource Constrained Platforms
Apr 29, 2019
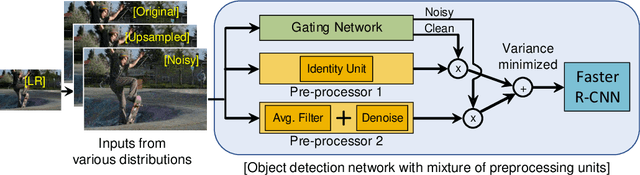


Deep learning on an edge device requires energy efficient operation due to ever diminishing power budget. Intentional low quality data during the data acquisition for longer battery life, and natural noise from the low cost sensor degrade the quality of target output which hinders adoption of deep learning on an edge device. To overcome these problems, we propose simple yet efficient mixture of pre-processing experts (MoPE) model to handle various image distortions including low resolution and noisy images. We also propose to use adversarially trained auto encoder as a pre-processing expert for the noisy images. We evaluate our proposed method for various machine learning tasks including object detection on MS-COCO 2014 dataset, multiple object tracking problem on MOT-Challenge dataset, and human activity classification on UCF 101 dataset. Experimental results show that the proposed method achieves better detection, tracking and activity classification accuracies under noise without sacrificing accuracies for the clean images. The overheads of our proposed MoPE are 0.67% and 0.17% in terms of memory and computation compared to the baseline object detection network.