 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains
Feb 03, 2026Humanoid perceptive locomotion has made significant progress and shows great promise, yet achieving robust multi-directional locomotion on complex terrains remains underexplored. To tackle this challenge, we propose RPL, a two-stage training framework that enables multi-directional locomotion on challenging terrains, and remains robust with payloads. RPL first trains terrain-specific expert policies with privileged height map observations to master decoupled locomotion and manipulation skills across different terrains, and then distills them into a transformer policy that leverages multiple depth cameras to cover a wide range of views. During distillation, we introduce two techniques to robustify multi-directional locomotion, depth feature scaling based on velocity commands and random side masking, which are critical for asymmetric depth observations and unseen widths of terrains. For scalable depth distillation, we develop an efficient multi-depth system that ray-casts against both dynamic robot meshes and static terrain meshes in massively parallel environments, achieving a 5-times speedup over the depth rendering pipelines in existing simulators while modeling realistic sensor latency, noise, and dropout. Extensive real-world experiments demonstrate robust multi-directional locomotion with payloads (2kg) across challenging terrains, including 20° slopes, staircases with different step lengths (22 cm, 25 cm, 30 cm), and 25 cm by 25 cm stepping stones separated by 60 cm gaps.
Flow Policy Gradients for Robot Control
Feb 02, 2026Likelihood-based policy gradient methods are the dominant approach for training robot control policies from rewards. These methods rely on differentiable action likelihoods, which constrain policy outputs to simple distributions like Gaussians. In this work, we show how flow matching policy gradients -- a recent framework that bypasses likelihood computation -- can be made effective for training and fine-tuning more expressive policies in challenging robot control settings. We introduce an improved objective that enables success in legged locomotion, humanoid motion tracking, and manipulation tasks, as well as robust sim-to-real transfer on two humanoid robots. We then present ablations and analysis on training dynamics. Results show how policies can exploit the flow representation for exploration when training from scratch, as well as improved fine-tuning robustness over baselines.
ResMimic: From General Motion Tracking to Humanoid Whole-body Loco-Manipulation via Residual Learning
Oct 06, 2025Humanoid whole-body loco-manipulation promises transformative capabilities for daily service and warehouse tasks. While recent advances in general motion tracking (GMT) have enabled humanoids to reproduce diverse human motions, these policies lack the precision and object awareness required for loco-manipulation. To this end, we introduce ResMimic, a two-stage residual learning framework for precise and expressive humanoid control from human motion data. First, a GMT policy, trained on large-scale human-only motion, serves as a task-agnostic base for generating human-like whole-body movements. An efficient but precise residual policy is then learned to refine the GMT outputs to improve locomotion and incorporate object interaction. To further facilitate efficient training, we design (i) a point-cloud-based object tracking reward for smoother optimization, (ii) a contact reward that encourages accurate humanoid body-object interactions, and (iii) a curriculum-based virtual object controller to stabilize early training. We evaluate ResMimic in both simulation and on a real Unitree G1 humanoid. Results show substantial gains in task success, training efficiency, and robustness over strong baselines. Videos are available at https://resmimic.github.io/ .
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Sep 30, 2025A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement learning (RL) policies. However, existing retargeting pipelines often struggle with the significant embodiment gap between humans and robots, producing physically implausible artifacts like foot-skating and penetration. More importantly, common retargeting methods neglect the rich human-object and human-environment interactions essential for expressive locomotion and loco-manipulation. To address this, we introduce OmniRetarget, an interaction-preserving data generation engine based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects. By minimizing the Laplacian deformation between the human and robot meshes while enforcing kinematic constraints, OmniRetarget generates kinematically feasible trajectories. Moreover, preserving task-relevant interactions enables efficient data augmentation, from a single demonstration to different robot embodiments, terrains, and object configurations. We comprehensively evaluate OmniRetarget by retargeting motions from OMOMO, LAFAN1, and our in-house MoCap datasets, generating over 8-hour trajectories that achieve better kinematic constraint satisfaction and contact preservation than widely used baselines. Such high-quality data enables proprioceptive RL policies to successfully execute long-horizon (up to 30 seconds) parkour and loco-manipulation skills on a Unitree G1 humanoid, trained with only 5 reward terms and simple domain randomization shared by all tasks, without any learning curriculum.
Domain Randomization and Generative Models for Robotic Grasping
Apr 03, 2018
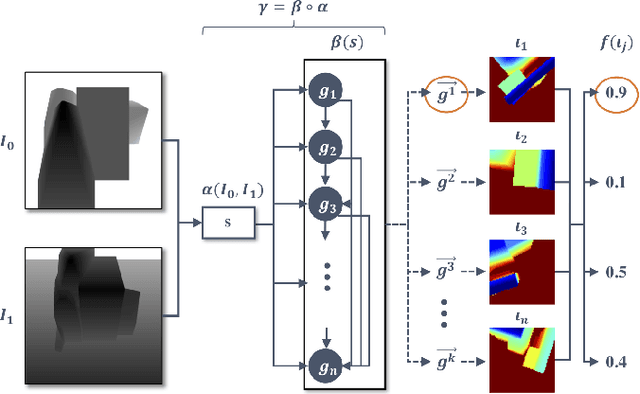
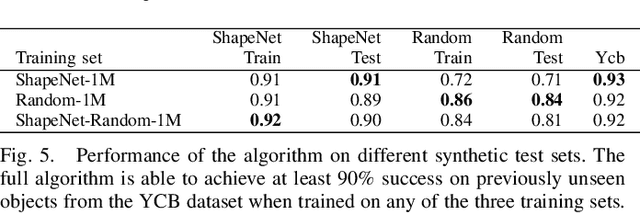
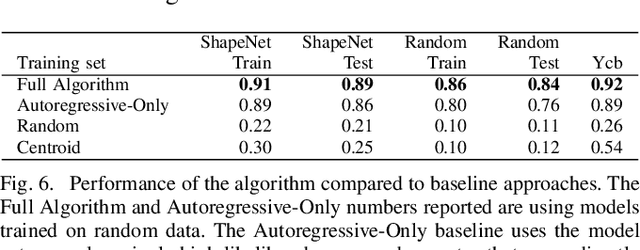
Deep learning-based robotic grasping has made significant progress thanks to algorithmic improvements and increased data availability. However, state-of-the-art models are often trained on as few as hundreds or thousands of unique object instances, and as a result generalization can be a challenge. In this work, we explore a novel data generation pipeline for training a deep neural network to perform grasp planning that applies the idea of domain randomization to object synthesis. We generate millions of unique, unrealistic procedurally generated objects, and train a deep neural network to perform grasp planning on these objects. Since the distribution of successful grasps for a given object can be highly multimodal, we propose an autoregressive grasp planning model that maps sensor inputs of a scene to a probability distribution over possible grasps. This model allows us to sample grasps efficiently at test time (or avoid sampling entirely). We evaluate our model architecture and data generation pipeline in simulation and the real world. We find we can achieve a $>$90% success rate on previously unseen realistic objects at test time in simulation despite having only been trained on random objects. We also demonstrate an 80% success rate on real-world grasp attempts despite having only been trained on random simulated objects.