 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering of Big Data with Mixed Features
Nov 11, 2020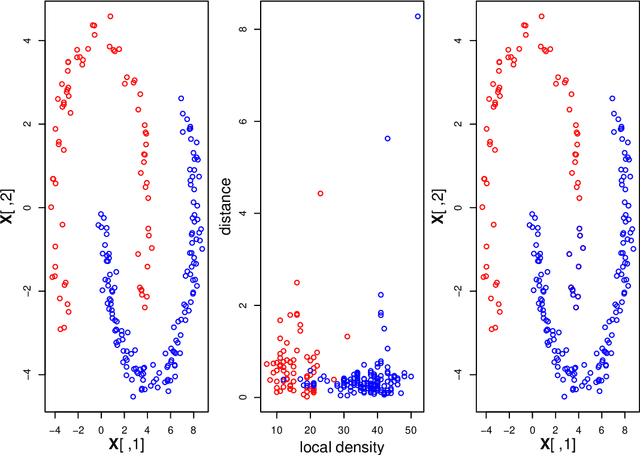
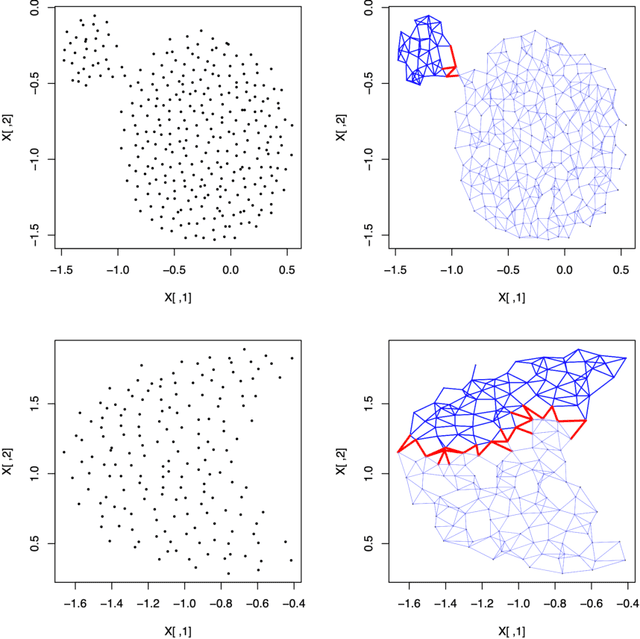

Clustering large, mixed data is a central problem in data mining. Many approaches adopt the idea of k-means, and hence are sensitive to initialisation, detect only spherical clusters, and require a priori the unknown number of clusters. We here develop a new clustering algorithm for large data of mixed type, aiming at improving the applicability and efficiency of the peak-finding technique. The improvements are threefold: (1) the new algorithm is applicable to mixed data; (2) the algorithm is capable of detecting outliers and clusters of relatively lower density values; (3) the algorithm is competent at deciding the correct number of clusters. The computational complexity of the algorithm is greatly reduced by applying a fast k-nearest neighbors method and by scaling down to component sets. We present experimental results to verify that our algorithm works well in practice. Keywords: Clustering; Big Data; Mixed Attribute; Density Peaks; Nearest-Neighbor Graph; Conductance.
Domain Randomization and Generative Models for Robotic Grasping
Apr 03, 2018
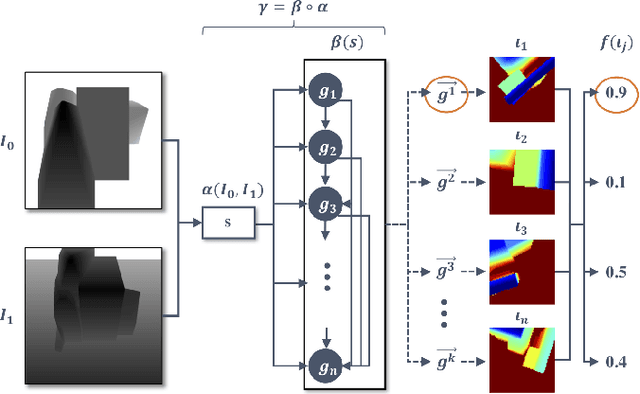
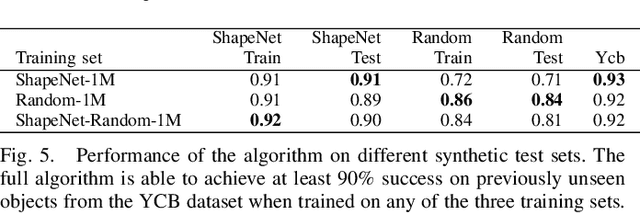
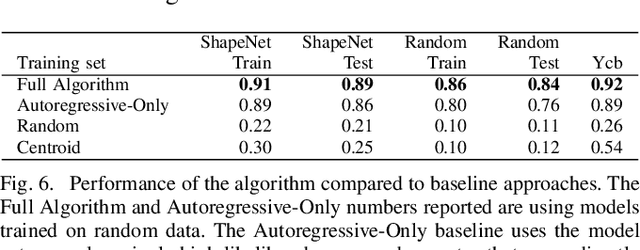
Deep learning-based robotic grasping has made significant progress thanks to algorithmic improvements and increased data availability. However, state-of-the-art models are often trained on as few as hundreds or thousands of unique object instances, and as a result generalization can be a challenge. In this work, we explore a novel data generation pipeline for training a deep neural network to perform grasp planning that applies the idea of domain randomization to object synthesis. We generate millions of unique, unrealistic procedurally generated objects, and train a deep neural network to perform grasp planning on these objects. Since the distribution of successful grasps for a given object can be highly multimodal, we propose an autoregressive grasp planning model that maps sensor inputs of a scene to a probability distribution over possible grasps. This model allows us to sample grasps efficiently at test time (or avoid sampling entirely). We evaluate our model architecture and data generation pipeline in simulation and the real world. We find we can achieve a $>$90% success rate on previously unseen realistic objects at test time in simulation despite having only been trained on random objects. We also demonstrate an 80% success rate on real-world grasp attempts despite having only been trained on random simulated objects.
Transfer from Simulation to Real World through Learning Deep Inverse Dynamics Model
Oct 11, 2016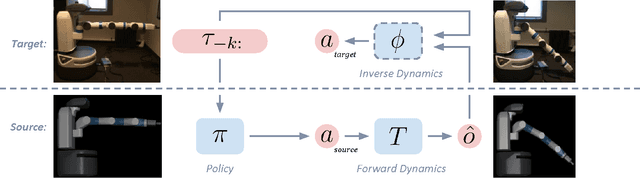

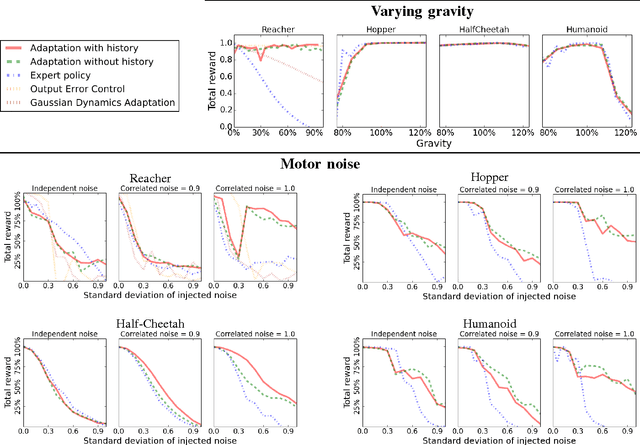
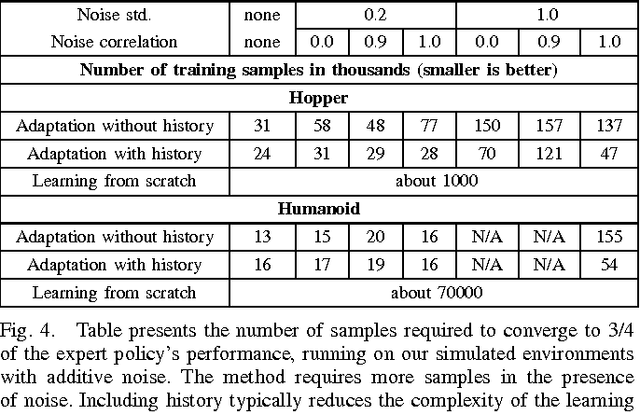
Developing control policies in simulation is often more practical and safer than directly running experiments in the real world. This applies to policies obtained from planning and optimization, and even more so to policies obtained from reinforcement learning, which is often very data demanding. However, a policy that succeeds in simulation often doesn't work when deployed on a real robot. Nevertheless, often the overall gist of what the policy does in simulation remains valid in the real world. In this paper we investigate such settings, where the sequence of states traversed in simulation remains reasonable for the real world, even if the details of the controls are not, as could be the case when the key differences lie in detailed friction, contact, mass and geometry properties. During execution, at each time step our approach computes what the simulation-based control policy would do, but then, rather than executing these controls on the real robot, our approach computes what the simulation expects the resulting next state(s) will be, and then relies on a learned deep inverse dynamics model to decide which real-world action is most suitable to achieve those next states. Deep models are only as good as their training data, and we also propose an approach for data collection to (incrementally) learn the deep inverse dynamics model. Our experiments shows our approach compares favorably with various baselines that have been developed for dealing with simulation to real world model discrepancy, including output error control and Gaussian dynamics adaptation.