 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndexing the Unreadable: LLM-Native Recursive Construction and Search of Service Taxonomies
May 28, 2026The era of the Internet of Agents (IoA) is taking shape: LLM agents are expected to fulfill user goals by orchestrating fast-growing populations of Model Context Protocol (MCP) servers, Agent-to-Agent (A2A) endpoints, reusable skills, and other LLM-callable services. Yet LLMs face a structural mismatch with this regime: effective context is a scarce resource that does not scale with the number of services. Concatenating thousands of service descriptions into a prompt overflows the context window, and even when the window is large enough, models systematically under-attend to information in the middle of long inputs, the well-documented Lost-in-the-Middle phenomenon. This is fundamentally a question of context management for service discovery. To address this, we propose an LLM-native progressive-disclosure scheme and its concrete instantiation, A2X (Agent-to-Anything service discovery): an LLM-driven pipeline that automatically organizes the registered services into a hierarchical taxonomy and walks it layer by layer at query time, so that every LLM call sees only a small candidate set highly relevant to the user query. This decouples effective-context scarcity from registry size and significantly reduces token consumption while improving retrieval accuracy. Compared to full-context dumping, A2X achieves a 6.2-point Hit Rate gain at one-ninth the prompt-token cost; compared to the state-of-the-art open-source embedding-based baseline, A2X improves Hit Rate by more than 20 points.
Learning Optimal Multimodal Information Bottleneck Representations
May 26, 2025Leveraging high-quality joint representations from multimodal data can greatly enhance model performance in various machine-learning based applications. Recent multimodal learning methods, based on the multimodal information bottleneck (MIB) principle, aim to generate optimal MIB with maximal task-relevant information and minimal superfluous information via regularization. However, these methods often set ad hoc regularization weights and overlook imbalanced task-relevant information across modalities, limiting their ability to achieve optimal MIB. To address this gap, we propose a novel multimodal learning framework, Optimal Multimodal Information Bottleneck (OMIB), whose optimization objective guarantees the achievability of optimal MIB by setting the regularization weight within a theoretically derived bound. OMIB further addresses imbalanced task-relevant information by dynamically adjusting regularization weights per modality, promoting the inclusion of all task-relevant information. Moreover, we establish a solid information-theoretical foundation for OMIB's optimization and implement it under the variational approximation framework for computational efficiency. Finally, we empirically validate the OMIB's theoretical properties on synthetic data and demonstrate its superiority over the state-of-the-art benchmark methods in various downstream tasks.
LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
Apr 30, 2025General-purpose humanoid robots are expected to interact intuitively with humans, enabling seamless integration into daily life. Natural language provides the most accessible medium for this purpose. However, translating language into humanoid whole-body motion remains a significant challenge, primarily due to the gap between linguistic understanding and physical actions. In this work, we present an end-to-end, language-directed policy for real-world humanoid whole-body control. Our approach combines reinforcement learning with policy distillation, allowing a single neural network to interpret language commands and execute corresponding physical actions directly. To enhance motion diversity and compositionality, we incorporate a Conditional Variational Autoencoder (CVAE) structure. The resulting policy achieves agile and versatile whole-body behaviors conditioned on language inputs, with smooth transitions between various motions, enabling adaptation to linguistic variations and the emergence of novel motions. We validate the efficacy and generalizability of our method through extensive simulations and real-world experiments, demonstrating robust whole-body control. Please see our website at LangWBC.github.io for more information.
DeMod: A Holistic Tool with Explainable Detection and Personalized Modification for Toxicity Censorship
Nov 04, 2024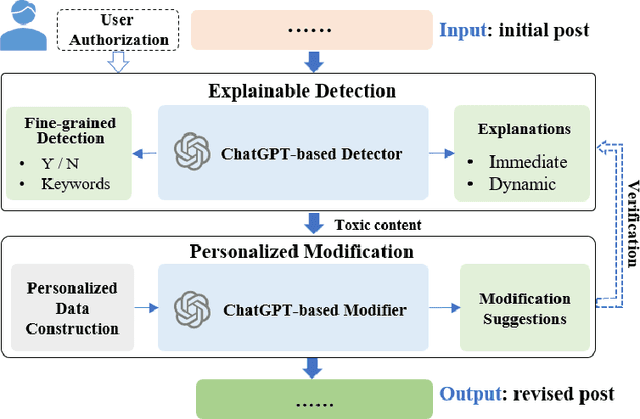
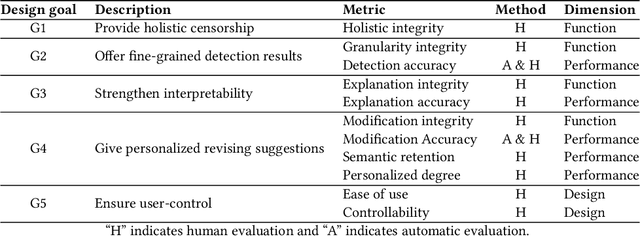
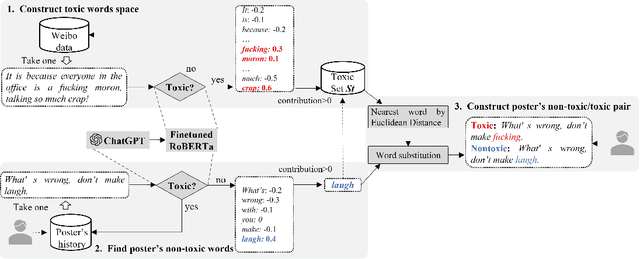
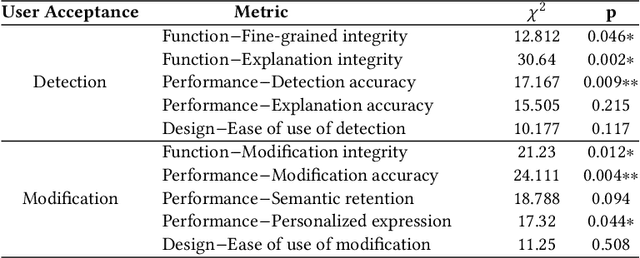
Although there have been automated approaches and tools supporting toxicity censorship for social posts, most of them focus on detection. Toxicity censorship is a complex process, wherein detection is just an initial task and a user can have further needs such as rationale understanding and content modification. For this problem, we conduct a needfinding study to investigate people's diverse needs in toxicity censorship and then build a ChatGPT-based censorship tool named DeMod accordingly. DeMod is equipped with the features of explainable Detection and personalized Modification, providing fine-grained detection results, detailed explanations, and personalized modification suggestions. We also implemented the tool and recruited 35 Weibo users for evaluation. The results suggest DeMod's multiple strengths like the richness of functionality, the accuracy of censorship, and ease of use. Based on the findings, we further propose several insights into the design of content censorship systems.