 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Catastrophic Forgetting in Multimodal Large Language Models
Paper and Code

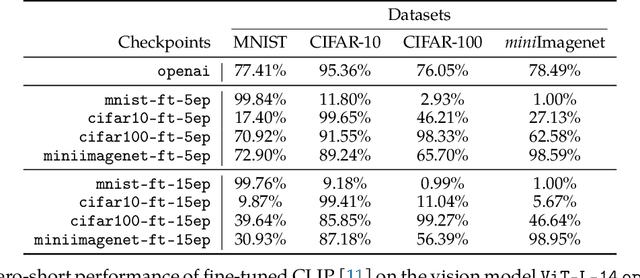
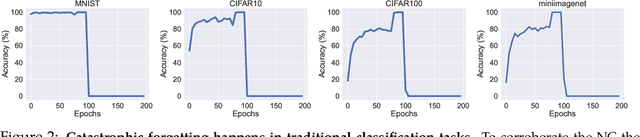
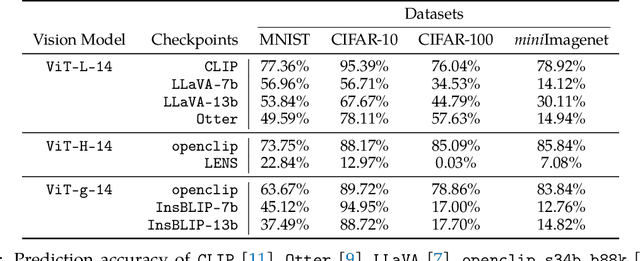
Following the success of GPT4, there has been a surge in interest in multimodal large language model (MLLM) research. This line of research focuses on developing general-purpose LLMs through fine-tuning pre-trained LLMs and vision models. However, catastrophic forgetting, a notorious phenomenon where the fine-tuned model fails to retain similar performance compared to the pre-trained model, still remains an inherent problem in multimodal LLMs (MLLM). In this paper, we introduce EMT: Evaluating MulTimodality for evaluating the catastrophic forgetting in MLLMs, by treating each MLLM as an image classifier. We first apply EMT to evaluate several open-source fine-tuned MLLMs and we discover that almost all evaluated MLLMs fail to retain the same performance levels as their vision encoders on standard image classification tasks. Moreover, we continue fine-tuning LLaVA, an MLLM and utilize EMT to assess performance throughout the fine-tuning. Interestingly, our results suggest that early-stage fine-tuning on an image dataset improves performance across other image datasets, by enhancing the alignment of text and visual features. However, as fine-tuning proceeds, the MLLMs begin to hallucinate, resulting in a significant loss of generalizability, even when the image encoder remains frozen. Our results suggest that MLLMs have yet to demonstrate performance on par with their vision models on standard image classification tasks and the current MLLM fine-tuning procedure still has room for improvement.