 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPERA: Automatic Offline Policy Evaluation with Re-weighted Aggregates of Multiple Estimators
May 27, 2024



Offline policy evaluation (OPE) allows us to evaluate and estimate a new sequential decision-making policy's performance by leveraging historical interaction data collected from other policies. Evaluating a new policy online without a confident estimate of its performance can lead to costly, unsafe, or hazardous outcomes, especially in education and healthcare. Several OPE estimators have been proposed in the last decade, many of which have hyperparameters and require training. Unfortunately, choosing the best OPE algorithm for each task and domain is still unclear. In this paper, we propose a new algorithm that adaptively blends a set of OPE estimators given a dataset without relying on an explicit selection using a statistical procedure. We prove that our estimator is consistent and satisfies several desirable properties for policy evaluation. Additionally, we demonstrate that when compared to alternative approaches, our estimator can be used to select higher-performing policies in healthcare and robotics. Our work contributes to improving ease of use for a general-purpose, estimator-agnostic, off-policy evaluation framework for offline RL.
SOPE: Spectrum of Off-Policy Estimators
Dec 02, 2021

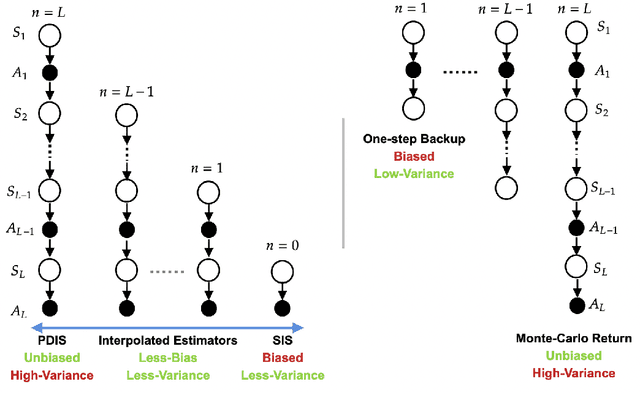
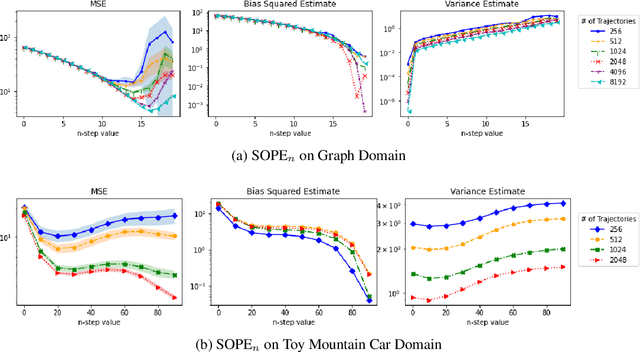
Many sequential decision making problems are high-stakes and require off-policy evaluation (OPE) of a new policy using historical data collected using some other policy. One of the most common OPE techniques that provides unbiased estimates is trajectory based importance sampling (IS). However, due to the high variance of trajectory IS estimates, importance sampling methods based on state-action visitation distributions (SIS) have recently been adopted. Unfortunately, while SIS often provides lower variance estimates for long horizons, estimating the state-action distribution ratios can be challenging and lead to biased estimates. In this paper, we present a new perspective on this bias-variance trade-off and show the existence of a spectrum of estimators whose endpoints are SIS and IS. Additionally, we also establish a spectrum for doubly-robust and weighted version of these estimators. We provide empirical evidence that estimators in this spectrum can be used to trade-off between the bias and variance of IS and SIS and can achieve lower mean-squared error than both IS and SIS.