 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Tutor Better Supported Lower Performers in a Math Task
Apr 13, 2023



Resource limitations make it hard to provide all students with one of the most effective educational interventions: personalized instruction. Reinforcement learning could be a key tool to reduce the development cost and improve the effectiveness of intelligent tutoring software that aims to provide the right support, at the right time, to a student. Here we illustrate that deep reinforcement learning can be used to provide adaptive pedagogical support to students learning about the concept of volume in a narrative storyline software. Using explainable artificial intelligence tools, we extracted interpretable insights about the pedagogical policy learned and demonstrated that the resulting policy had similar performance in a different student population. Most importantly, in both studies, the reinforcement-learning narrative system had the largest benefit for those students with the lowest initial pretest scores, suggesting the opportunity for AI to adapt and provide support for those most in need.
Data-Efficient Pipeline for Offline Reinforcement Learning with Limited Data
Oct 16, 2022
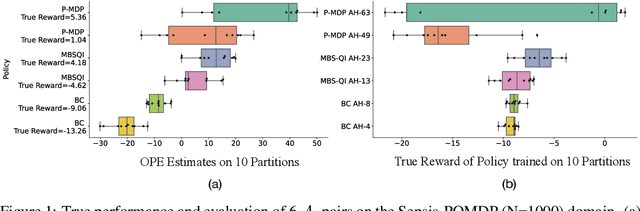

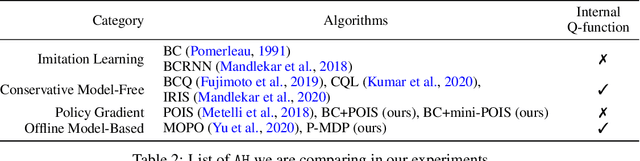
Offline reinforcement learning (RL) can be used to improve future performance by leveraging historical data. There exist many different algorithms for offline RL, and it is well recognized that these algorithms, and their hyperparameter settings, can lead to decision policies with substantially differing performance. This prompts the need for pipelines that allow practitioners to systematically perform algorithm-hyperparameter selection for their setting. Critically, in most real-world settings, this pipeline must only involve the use of historical data. Inspired by statistical model selection methods for supervised learning, we introduce a task- and method-agnostic pipeline for automatically training, comparing, selecting, and deploying the best policy when the provided dataset is limited in size. In particular, our work highlights the importance of performing multiple data splits to produce more reliable algorithm-hyperparameter selection. While this is a common approach in supervised learning, to our knowledge, this has not been discussed in detail in the offline RL setting. We show it can have substantial impacts when the dataset is small. Compared to alternate approaches, our proposed pipeline outputs higher-performing deployed policies from a broad range of offline policy learning algorithms and across various simulation domains in healthcare, education, and robotics. This work contributes toward the development of a general-purpose meta-algorithm for automatic algorithm-hyperparameter selection for offline RL.