 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Diverse Generative Robot Designs using Evolution and Intrinsic Motivation
Dec 03, 2024Methods for generative design of robot physical configurations can automatically find optimal and innovative solutions for challenging tasks in complex environments. The vast search-space includes the physical design-space and the controller parameter-space, making it a challenging problem in machine learning and optimisation in general. Evolutionary algorithms (EAs) have shown promising results in generating robot designs via gradient-free optimisation. Morpho-evolution with learning (MEL) uses EAs to concurrently generate robot designs and learn the optimal parameters of the controllers. Two main issues prevent MEL from scaling to higher complexity tasks: computational cost and premature convergence to sub-optimal designs. To address these issues, we propose combining morpho-evolution with intrinsic motivations. Intrinsically motivated behaviour arises from embodiment and simple learning rules without external guidance. We use a homeokinetic controller that generates exploratory behaviour in a few seconds with reduced knowledge of the robot's design. Homeokinesis replaces costly learning phases, reducing computational time and favouring diversity, preventing premature convergence. We compare our approach with current MEL methods in several downstream tasks. The generated designs score higher in all the tasks, are more diverse, and are quickly generated compared to morpho-evolution with static parameters.
Generalized Early Stopping in Evolutionary Direct Policy Search
Aug 07, 2023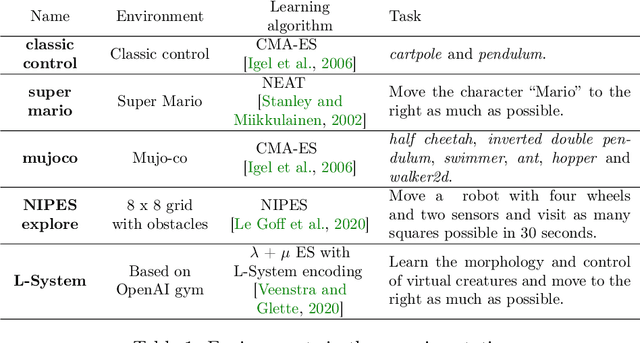
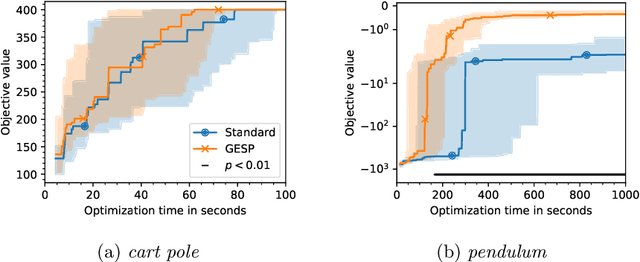
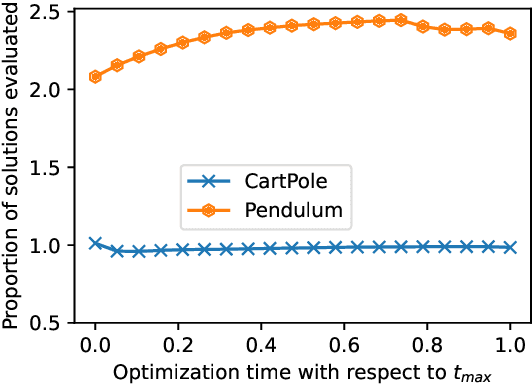
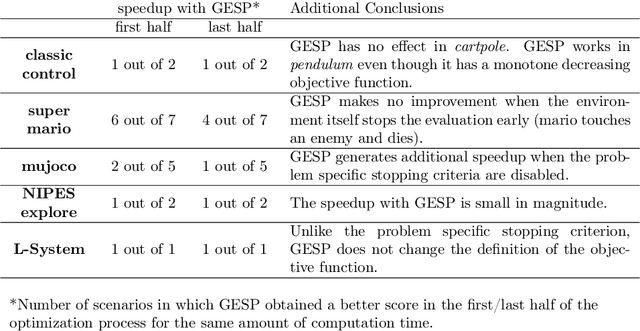
Lengthy evaluation times are common in many optimization problems such as direct policy search tasks, especially when they involve conducting evaluations in the physical world, e.g. in robotics applications. Often, when evaluating a solution over a fixed time period, it becomes clear that the objective value will not increase with additional computation time (for example, when a two-wheeled robot continuously spins on the spot). In such cases, it makes sense to stop the evaluation early to save computation time. However, most approaches to stop the evaluation are problem-specific and need to be specifically designed for the task at hand. Therefore, we propose an early stopping method for direct policy search. The proposed method only looks at the objective value at each time step and requires no problem-specific knowledge. We test the introduced stopping criterion in five direct policy search environments drawn from games, robotics, and classic control domains, and show that it can save up to 75% of the computation time. We also compare it with problem-specific stopping criteria and demonstrate that it performs comparably while being more generally applicable.
Building an Affordances Map with Interactive Perception
Mar 11, 2019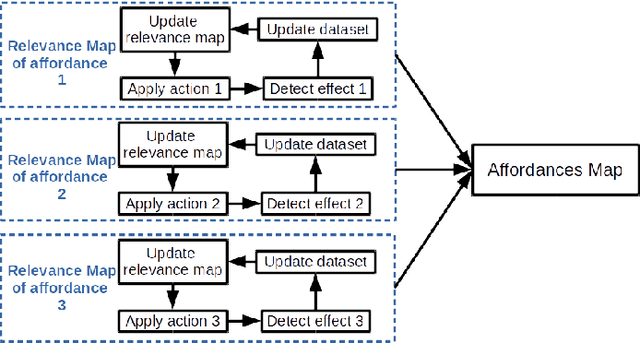
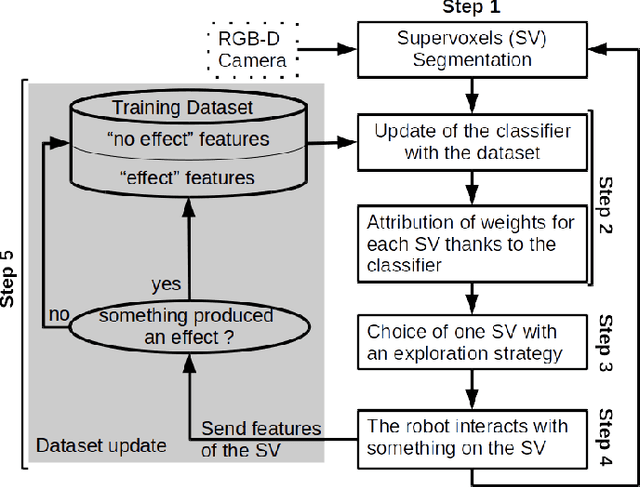

Robots need to understand their environment to perform their task. If it is possible to pre-program a visual scene analysis process in closed environments, robots operating in an open environment would benefit from the ability to learn it through their interaction with their environment. This ability furthermore opens the way to the acquisition of affordances maps in which the action capabilities of the robot structure its visual scene understanding. We propose an approach to build such affordances maps by relying on an interactive perception approach and an online classification. In the proposed formalization of affordances, actions and effects are related to visual features, not objects, and they can be combined. We have tested the approach on three action primitives and on a real PR2 robot.