 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Video Generation: Decoupling Scene Construction and Temporal Synthesis in Text-to-Video Diffusion Models
Dec 18, 2025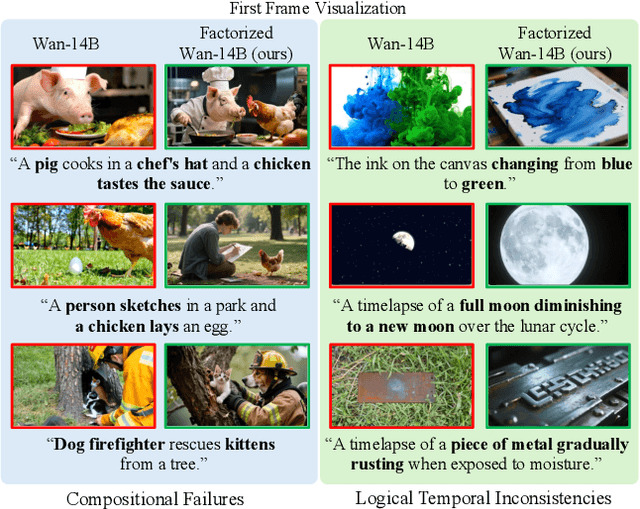

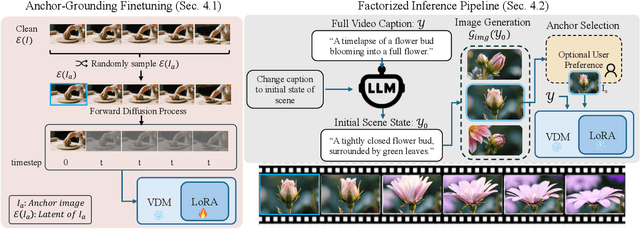
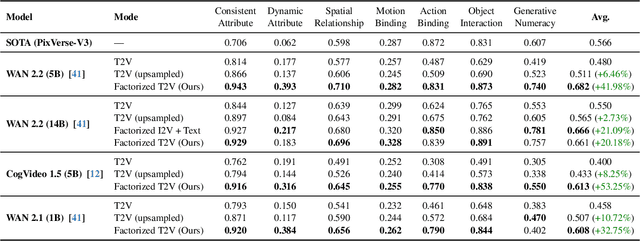
State-of-the-art Text-to-Video (T2V) diffusion models can generate visually impressive results, yet they still frequently fail to compose complex scenes or follow logical temporal instructions. In this paper, we argue that many errors, including apparent motion failures, originate from the model's inability to construct a semantically correct or logically consistent initial frame. We introduce Factorized Video Generation (FVG), a pipeline that decouples these tasks by decomposing the Text-to-Video generation into three specialized stages: (1) Reasoning, where a Large Language Model (LLM) rewrites the video prompt to describe only the initial scene, resolving temporal ambiguities; (2) Composition, where a Text-to-Image (T2I) model synthesizes a high-quality, compositionally-correct anchor frame from this new prompt; and (3) Temporal Synthesis, where a video model, finetuned to understand this anchor, focuses its entire capacity on animating the scene and following the prompt. Our decomposed approach sets a new state-of-the-art on the T2V CompBench benchmark and significantly improves all tested models on VBench2. Furthermore, we show that visual anchoring allows us to cut the number of sampling steps by 70% without any loss in performance, leading to a substantial speed-up in sampling. Factorized Video Generation offers a simple yet practical path toward more efficient, robust, and controllable video synthesis
Estimating Risk and Uncertainty in Deep Reinforcement Learning
Jun 07, 2019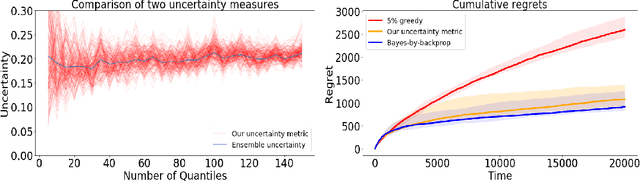
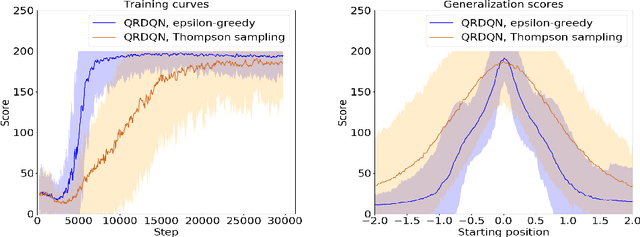
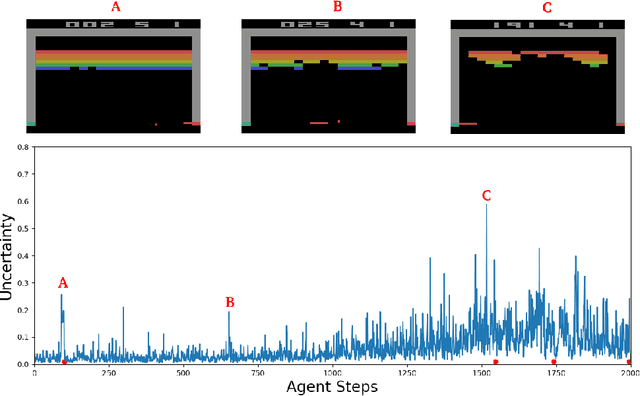
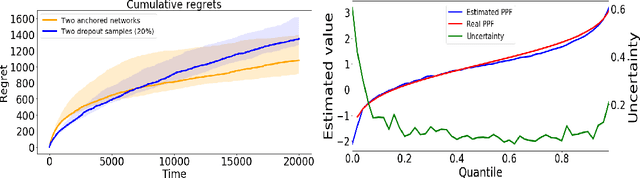
This paper demonstrates a novel method for separately estimating aleatoric risk and epistemic uncertainty in deep reinforcement learning. Aleatoric risk, which arises from inherently stochastic environments or agents, must be accounted for in the design of risk-sensitive algorithms. Epistemic uncertainty, which stems from limited data, is important both for risk-sensitivity and to efficiently explore an environment. We first present a Bayesian framework for learning the return distribution in reinforcement learning, which provides theoretical foundations for quantifying both types of uncertainty. Based on this framework, we show that the disagreement between only two neural networks is sufficient to produce a low-variance estimate of the epistemic uncertainty on the return distribution, thus providing a simple and computationally cheap uncertainty metric. We demonstrate experiments that illustrate our method and some applications.