 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Counterfactual Visual Explanations (FCVE)
Jan 12, 2025



Deep learning models in computer vision have made remarkable progress, but their lack of transparency and interpretability remains a challenge. The development of explainable AI can enhance the understanding and performance of these models. However, existing techniques often struggle to provide convincing explanations that non-experts easily understand, and they cannot accurately identify models' intrinsic decision-making processes. To address these challenges, we propose to develop a counterfactual explanation (CE) model that balances plausibility and faithfulness. This model generates easy-to-understand visual explanations by making minimum changes necessary in images without altering the pixel data. Instead, the proposed method identifies internal concepts and filters learned by models and leverages them to produce plausible counterfactual explanations. The provided explanations reflect the internal decision-making process of the model, thus ensuring faithfulness to the model.
VALD-MD: Visual Attribution via Latent Diffusion for Medical Diagnostics
Jan 02, 2024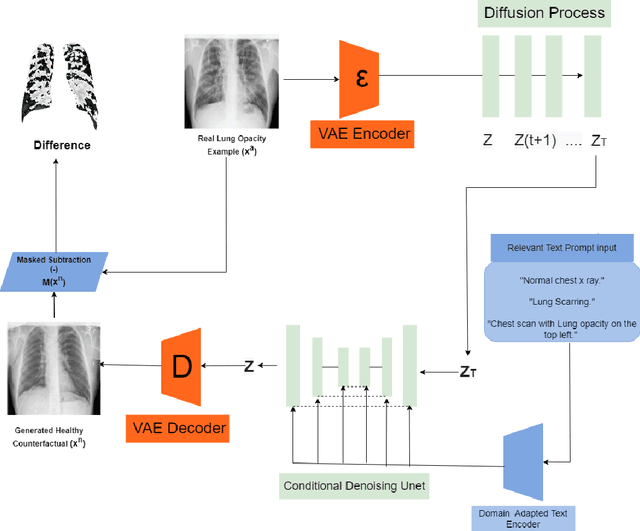

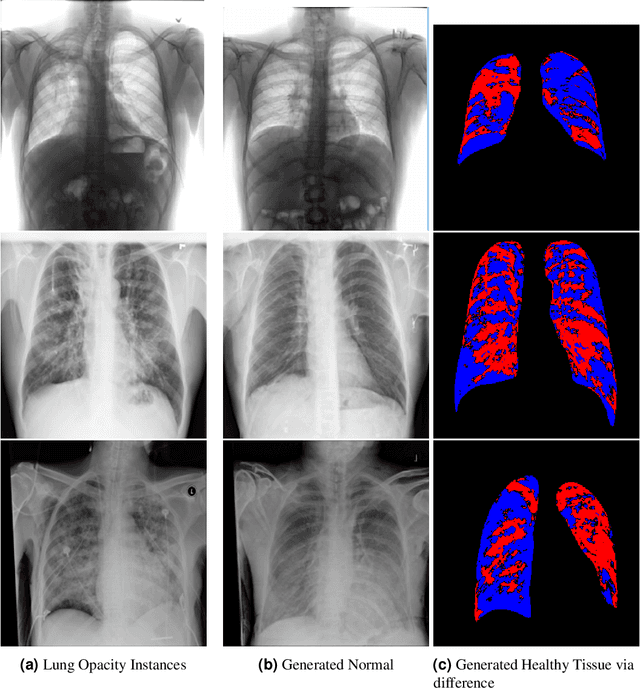

Visual attribution in medical imaging seeks to make evident the diagnostically-relevant components of a medical image, in contrast to the more common detection of diseased tissue deployed in standard machine vision pipelines (which are less straightforwardly interpretable/explainable to clinicians). We here present a novel generative visual attribution technique, one that leverages latent diffusion models in combination with domain-specific large language models, in order to generate normal counterparts of abnormal images. The discrepancy between the two hence gives rise to a mapping indicating the diagnostically-relevant image components. To achieve this, we deploy image priors in conjunction with appropriate conditioning mechanisms in order to control the image generative process, including natural language text prompts acquired from medical science and applied radiology. We perform experiments and quantitatively evaluate our results on the COVID-19 Radiography Database containing labelled chest X-rays with differing pathologies via the Frechet Inception Distance (FID), Structural Similarity (SSIM) and Multi Scale Structural Similarity Metric (MS-SSIM) metrics obtained between real and generated images. The resulting system also exhibits a range of latent capabilities including zero-shot localized disease induction, which are evaluated with real examples from the cheXpert dataset.
The Quantum Path Kernel: a Generalized Quantum Neural Tangent Kernel for Deep Quantum Machine Learning
Dec 22, 2022



Building a quantum analog of classical deep neural networks represents a fundamental challenge in quantum computing. A key issue is how to address the inherent non-linearity of classical deep learning, a problem in the quantum domain due to the fact that the composition of an arbitrary number of quantum gates, consisting of a series of sequential unitary transformations, is intrinsically linear. This problem has been variously approached in the literature, principally via the introduction of measurements between layers of unitary transformations. In this paper, we introduce the Quantum Path Kernel, a formulation of quantum machine learning capable of replicating those aspects of deep machine learning typically associated with superior generalization performance in the classical domain, specifically, hierarchical feature learning. Our approach generalizes the notion of Quantum Neural Tangent Kernel, which has been used to study the dynamics of classical and quantum machine learning models. The Quantum Path Kernel exploits the parameter trajectory, i.e. the curve delineated by model parameters as they evolve during training, enabling the representation of differential layer-wise convergence behaviors, or the formation of hierarchical parametric dependencies, in terms of their manifestation in the gradient space of the predictor function. We evaluate our approach with respect to variants of the classification of Gaussian XOR mixtures - an artificial but emblematic problem that intrinsically requires multilevel learning in order to achieve optimal class separation.
Generative Adversarial Networks (GANs) in Networking: A Comprehensive Survey & Evaluation
May 10, 2021
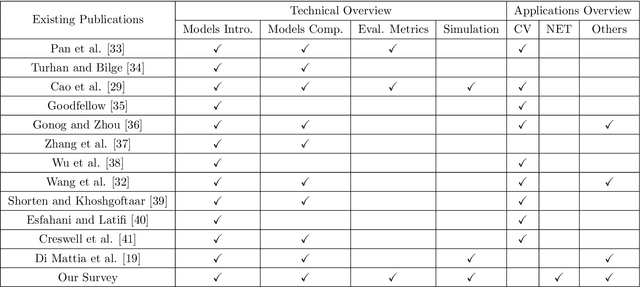
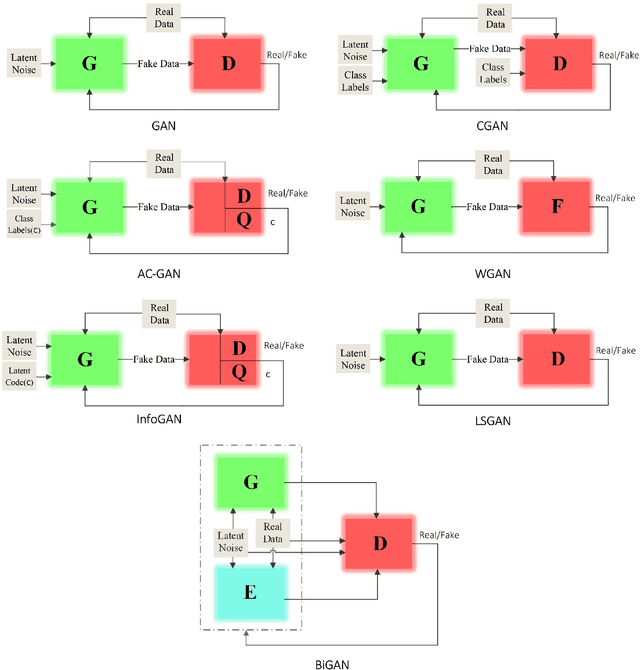
Despite the recency of their conception, Generative Adversarial Networks (GANs) constitute an extensively researched machine learning sub-field for the creation of synthetic data through deep generative modeling. GANs have consequently been applied in a number of domains, most notably computer vision, in which they are typically used to generate or transform synthetic images. Given their relative ease of use, it is therefore natural that researchers in the field of networking (which has seen extensive application of deep learning methods) should take an interest in GAN-based approaches. The need for a comprehensive survey of such activity is therefore urgent. In this paper, we demonstrate how this branch of machine learning can benefit multiple aspects of computer and communication networks, including mobile networks, network analysis, internet of things, physical layer, and cybersecurity. In doing so, we shall provide a novel evaluation framework for comparing the performance of different models in non-image applications, applying this to a number of reference network datasets.
Using Synthetic Data to Enhance the Accuracy of Fingerprint-Based Localization: A Deep Learning Approach
May 06, 2021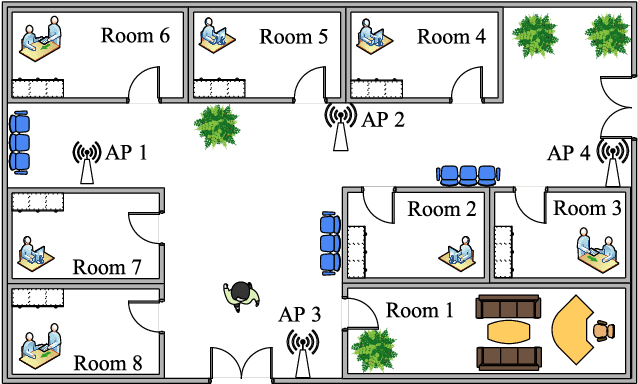
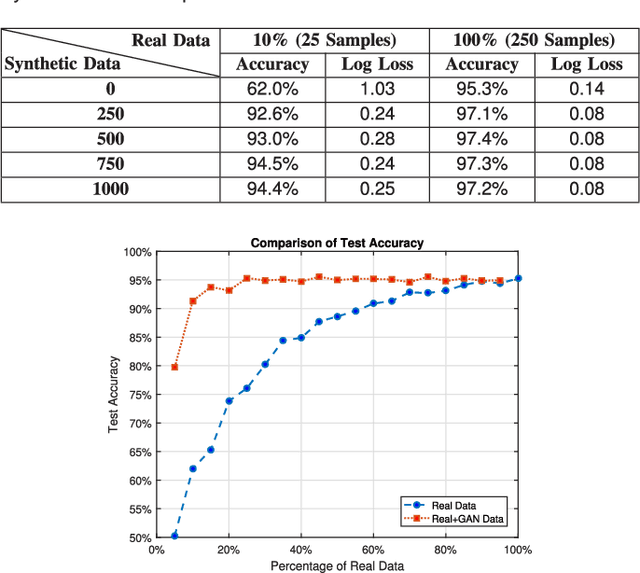
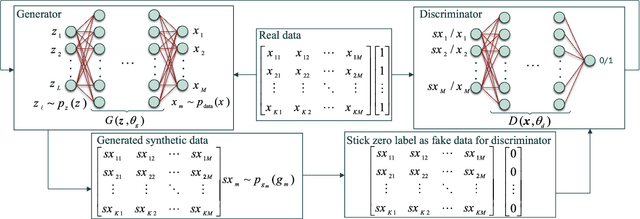
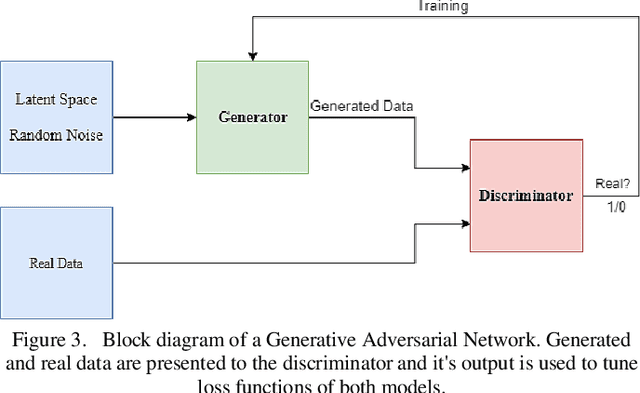
Human-centered data collection is typically costly and implicates issues of privacy. Various solutions have been proposed in the literature to reduce this cost, such as crowdsourced data collection, or the use of semi-supervised algorithms. However, semi-supervised algorithms require a source of unlabeled data, and crowd-sourcing methods require numbers of active participants. An alternative passive data collection modality is fingerprint-based localization. Such methods use received signal strength (RSS) or channel state information (CSI) in wireless sensor networks to localize users in indoor/outdoor environments. In this paper, we introduce a novel approach to reduce training data collection costs in fingerprint-based localization by using synthetic data. Generative adversarial networks (GANs) are used to learn the distribution of a limited sample of collected data and, following this, to produce synthetic data that can be used to augment the real collected data in order to increase overall positioning accuracy. Experimental results on a benchmark dataset show that by applying the proposed method and using a combination of 10% collected data and 90% synthetic data, we can obtain essentially similar positioning accuracy to that which would be obtained by using the full set of collected data. This means that by employing GAN-generated synthetic data, we can use 90% less real data, thereby reduce data-collection costs while achieving acceptable accuracy.
Using GAN to Enhance the Accuracy of Indoor Human Activity Recognition
Apr 23, 2020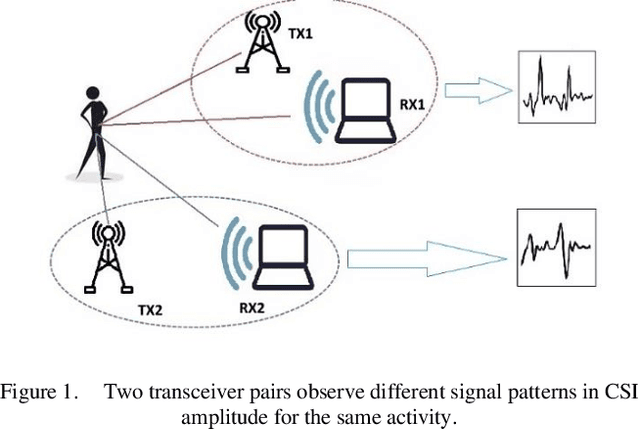
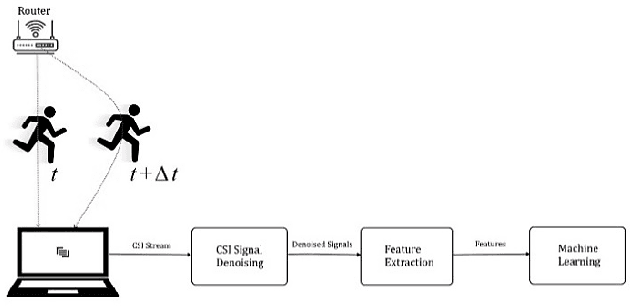

Indoor human activity recognition (HAR) explores the correlation between human body movements and the reflected WiFi signals to classify different activities. By analyzing WiFi signal patterns, especially the dynamics of channel state information (CSI), different activities can be distinguished. Gathering CSI data is expensive both from the timing and equipment perspective. In this paper, we use synthetic data to reduce the need for real measured CSI. We present a semi-supervised learning method for CSI-based activity recognition systems in which long short-term memory (LSTM) is employed to learn features and recognize seven different actions. We apply principal component analysis (PCA) on CSI amplitude data, while short-time Fourier transform (STFT) extracts the features in the frequency domain. At first, we train the LSTM network with entirely raw CSI data, which takes much more processing time. To this end, we aim to generate data by using 50% of raw data in conjunction with a generative adversarial network (GAN). Our experimental results confirm that this model can increase classification accuracy by 3.4% and reduce the Log loss by almost 16% in the considered scenario.
Automatic Delineation of Kidney Region in DCE-MRI
May 26, 2019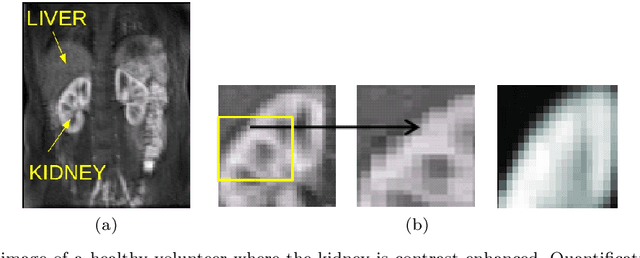
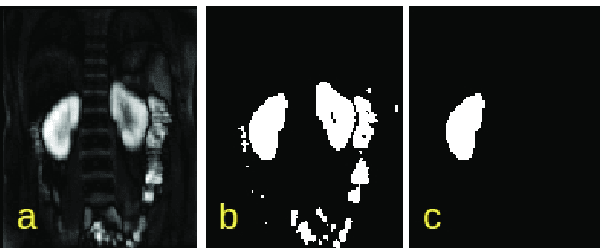
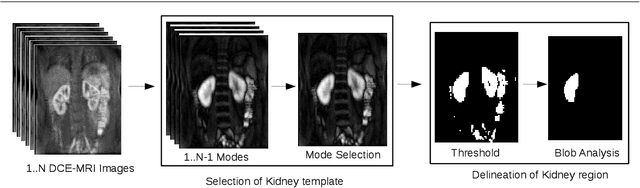
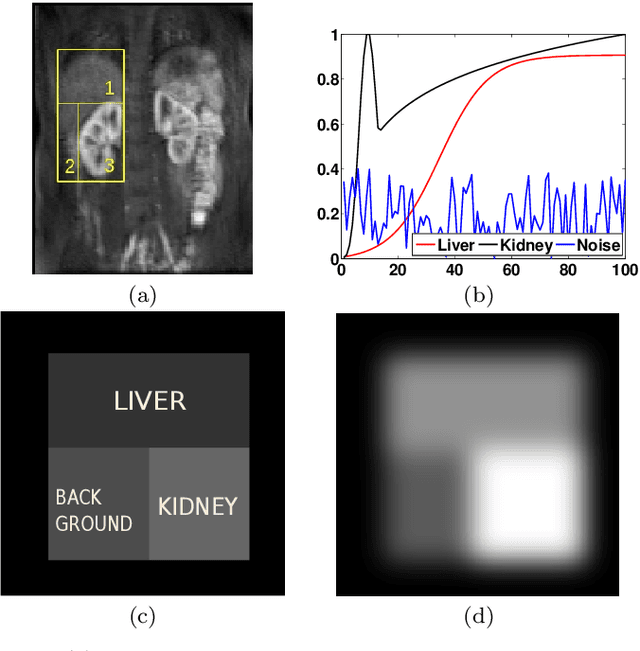
Delineation of the kidney region in dynamic contrast-enhanced magnetic resonance Imaging (DCE-MRI) is required during post-acquisition analysis in order to quantify various aspects of renal function, such as filtration and perfusion or blood flow. However, this can be obfuscated by the Partial Volume Effect (PVE), caused due to the mixing of any single voxel with two or more signal intensities from adjacent regions such as liver region and other tissues. To avoid this problem, firstly, a kidney region of interest (ROI) needs to be defined for the analysis. A clinician may choose to select a region avoiding edges where PV mixing is likely to be significant. However, this approach is time-consuming and labour intensive. To address this issue, we present Dynamic Mode Decomposition (DMD) coupled with thresholding and blob analysis as a framework for automatic delineation of the kidney region. This method is first validated on synthetically generated data with ground-truth available and then applied to ten healthy volunteers' kidney DCE-MRI datasets. We found that the result obtained from our proposed framework is comparable to that of a human expert. For example, while our result gives an average Root Mean Square Error (RMSE) of 0.0097, the baseline achieves an average RMSE of 0.1196 across the 10 datasets. As a result, we conclude automatic modelling via DMD framework is a promising approach.
Functional Segmentation through Dynamic Mode Decomposition: Automatic Quantification of Kidney Function in DCE-MRI Images
May 24, 2019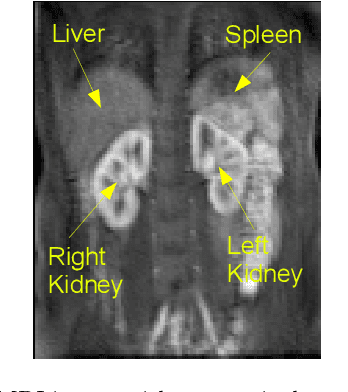
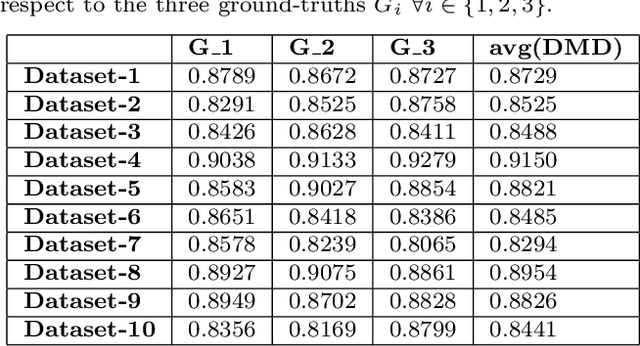
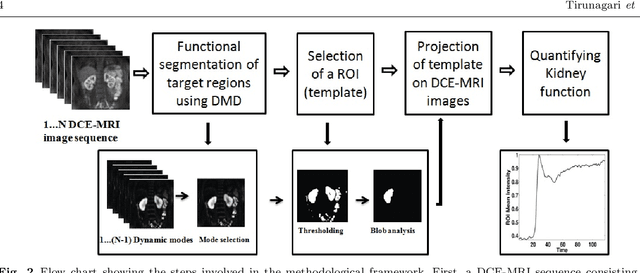
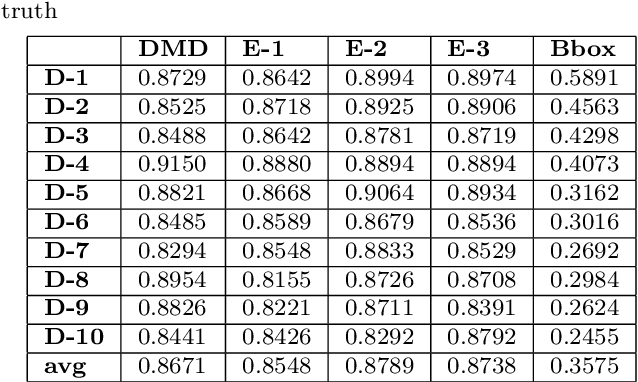
Quantification of kidney function in Dynamic Contrast-Enhanced Magnetic Resonance Imaging (DCE-MRI) requires careful segmentation of the renal region of interest (ROI). Traditionally, human experts are required to manually delineate the kidney ROI across multiple images in the dynamic sequence. This approach is costly, time-consuming and labour intensive, and therefore acts to limit patient throughout and acts as one of the factors limiting the wider adoption of DCR-MRI in clinical practice. Therefore, to address this issue, we present the first use of Dynamic Mode Decomposition (DMD) as a basis for automatic segmentation of a dynamic sequence, in this case, kidney ROIs in DCE-MRI. Using DMD coupled combined with thresholding and connected component analysis is first validated on synthetically generated data with known ground-truth, and then applied to ten healthy volunteers' DCE-MRI datasets. We find that the segmentation result obtained from our proposed DMD framework is comparable to that of expert observers and very significantly better than that of an a-priori bounding box segmentation. Our result gives a mean Jaccard coefficient of 0.87, compared to mean scores of 0.85, 0.88 and 0.87 produced from three independent manual annotations. This represents the first use of DMD as a robust automatic data-driven segmentation approach without requiring any human intervention. This is a viable, efficient alternative approach to current manual methods of isolation of kidney function in DCE-MRI.
Can DMD obtain a Scene Background in Color?
Jul 22, 2016

A background model describes a scene without any foreground objects and has a number of applications, ranging from video surveillance to computational photography. Recent studies have introduced the method of Dynamic Mode Decomposition (DMD) for robustly separating video frames into a background model and foreground components. While the method introduced operates by converting color images to grayscale, we in this study propose a technique to obtain the background model in the color domain. The effectiveness of our technique is demonstrated using a publicly available Scene Background Initialisation (SBI) dataset. Our results both qualitatively and quantitatively show that DMD can successfully obtain a colored background model.
Identifying Similar Patients Using Self-Organising Maps: A Case Study on Type-1 Diabetes Self-care Survey Responses
Mar 21, 2015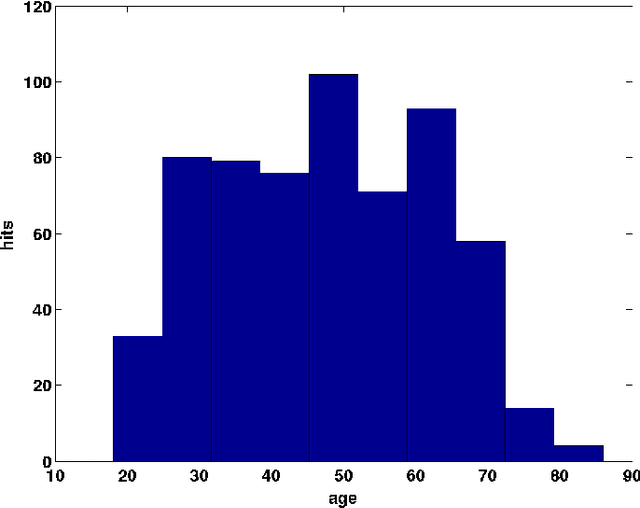
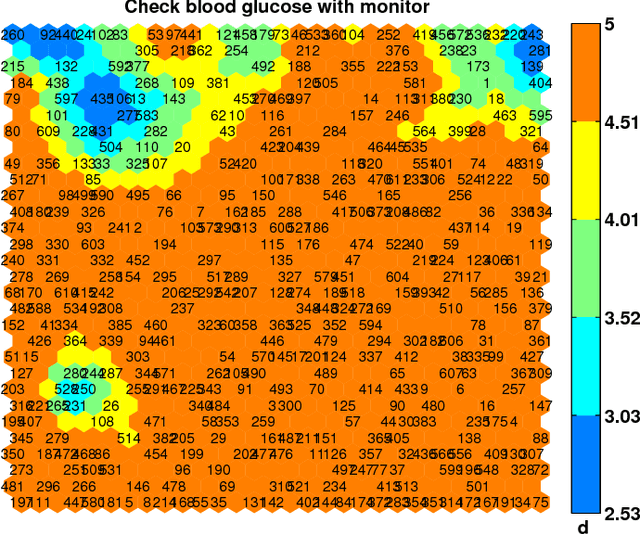
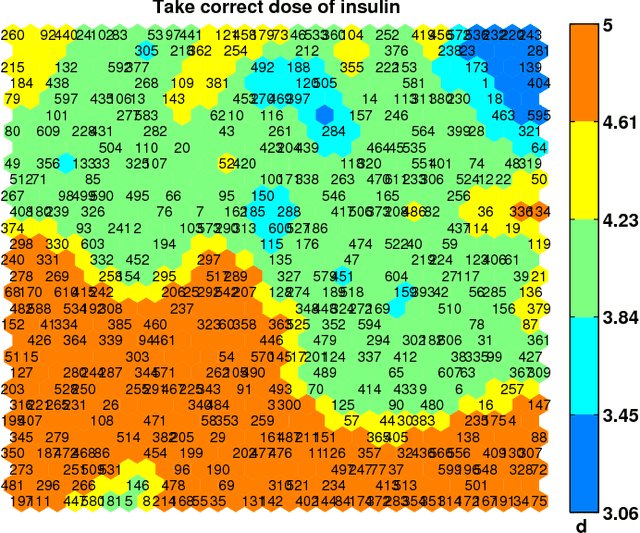
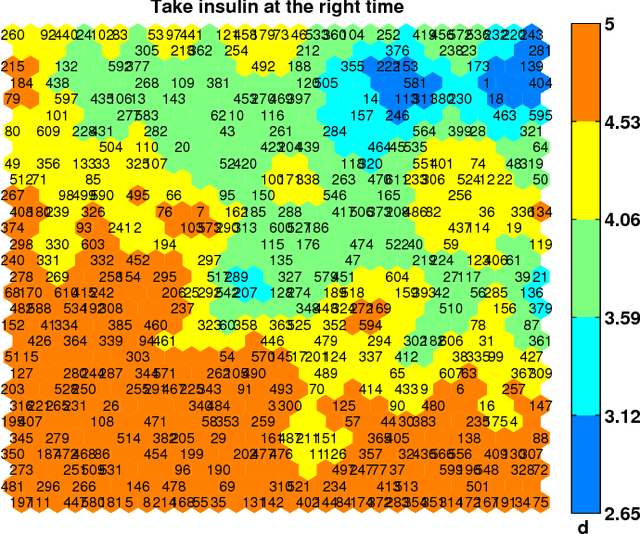
Diabetes is considered a lifestyle disease and a well managed self-care plays an important role in the treatment. Clinicians often conduct surveys to understand the self-care behaviors in their patients. In this context, we propose to use Self-Organising Maps (SOM) to explore the survey data for assessing the self-care behaviors in Type-1 diabetic patients. Specifically, SOM is used to visualize high dimensional similar patient profiles, which is rarely discussed. Experiments demonstrate that our findings through SOM analysis corresponds well to the expectations of the clinicians. In addition, our findings inspire the experts to improve their understanding of the self-care behaviors for their patients. The principle findings in our study show: 1) patients who take correct dose of insulin, inject insulin at the right time, 2) patients who take correct food portions undertake regular physical activity and 3) patients who eat on time take correct food portions.