 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALD-MD: Visual Attribution via Latent Diffusion for Medical Diagnostics
Jan 02, 2024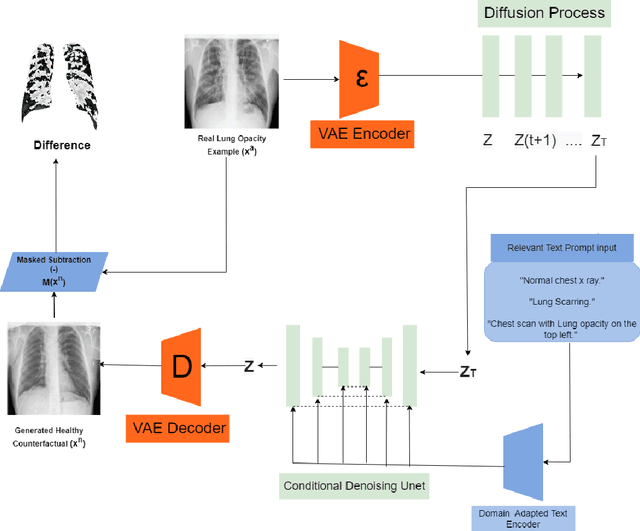

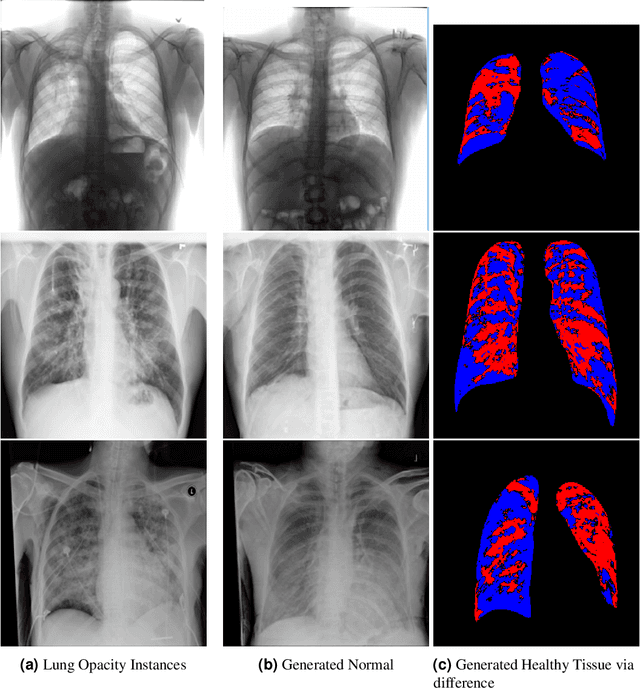

Visual attribution in medical imaging seeks to make evident the diagnostically-relevant components of a medical image, in contrast to the more common detection of diseased tissue deployed in standard machine vision pipelines (which are less straightforwardly interpretable/explainable to clinicians). We here present a novel generative visual attribution technique, one that leverages latent diffusion models in combination with domain-specific large language models, in order to generate normal counterparts of abnormal images. The discrepancy between the two hence gives rise to a mapping indicating the diagnostically-relevant image components. To achieve this, we deploy image priors in conjunction with appropriate conditioning mechanisms in order to control the image generative process, including natural language text prompts acquired from medical science and applied radiology. We perform experiments and quantitatively evaluate our results on the COVID-19 Radiography Database containing labelled chest X-rays with differing pathologies via the Frechet Inception Distance (FID), Structural Similarity (SSIM) and Multi Scale Structural Similarity Metric (MS-SSIM) metrics obtained between real and generated images. The resulting system also exhibits a range of latent capabilities including zero-shot localized disease induction, which are evaluated with real examples from the cheXpert dataset.