 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Pixel-Level Annotation with Visual Interpretability
Feb 25, 2025



Medical image annotation is essential for diagnosing diseases, yet manual annotation is time-consuming, costly, and prone to variability among experts. To address these challenges, we propose an automated explainable annotation system that integrates ensemble learning, visual explainability, and uncertainty quantification. Our approach combines three pre-trained deep learning models - ResNet50, EfficientNet, and DenseNet - enhanced with XGrad-CAM for visual explanations and Monte Carlo Dropout for uncertainty quantification. This ensemble mimics the consensus of multiple radiologists by intersecting saliency maps from models that agree on the diagnosis while uncertain predictions are flagged for human review. We evaluated our system using the TBX11K medical imaging dataset and a Fire segmentation dataset, demonstrating its robustness across different domains. Experimental results show that our method outperforms baseline models, achieving 93.04% accuracy on TBX11K and 96.4% accuracy on the Fire dataset. Moreover, our model produces precise pixel-level annotations despite being trained with only image-level labels, achieving Intersection over Union IoU scores of 36.07% and 64.7%, respectively. By enhancing the accuracy and interpretability of image annotations, our approach offers a reliable and transparent solution for medical diagnostics and other image analysis tasks.
TagGAN: A Generative Model for Data Tagging
Feb 25, 2025
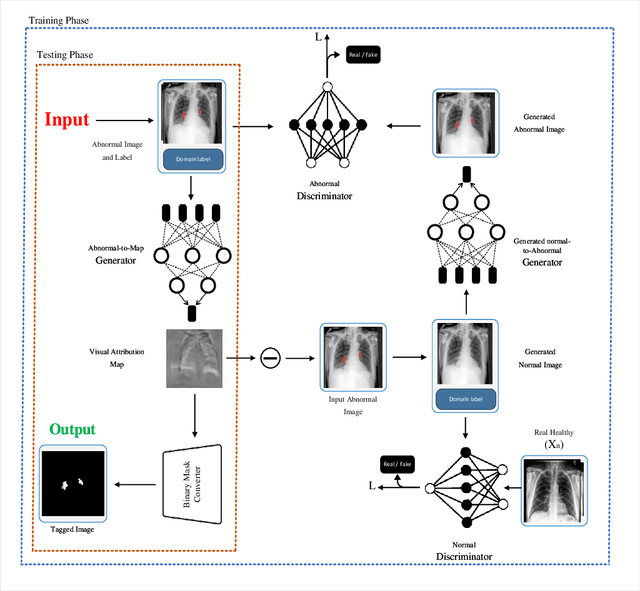
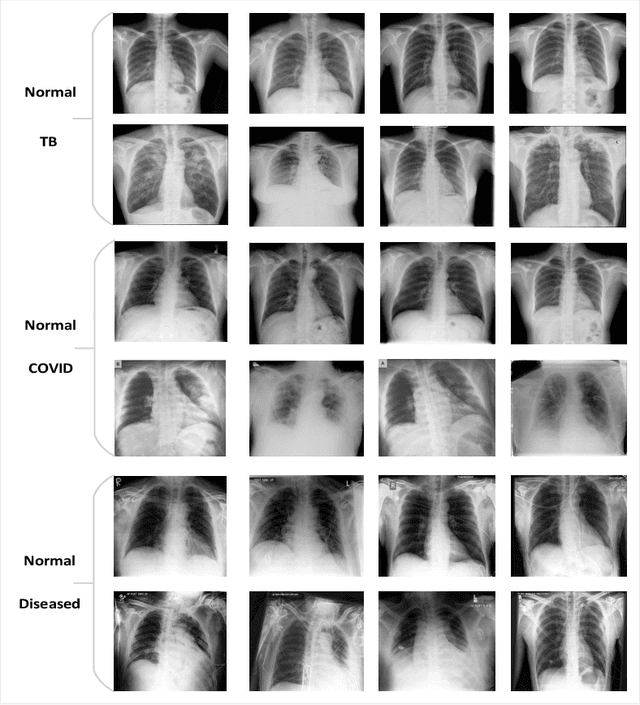

Precise identification and localization of disease-specific features at the pixel-level are particularly important for early diagnosis, disease progression monitoring, and effective treatment in medical image analysis. However, conventional diagnostic AI systems lack decision transparency and cannot operate well in environments where there is a lack of pixel-level annotations. In this study, we propose a novel Generative Adversarial Networks (GANs)-based framework, TagGAN, which is tailored for weakly-supervised fine-grained disease map generation from purely image-level labeled data. TagGAN generates a pixel-level disease map during domain translation from an abnormal image to a normal representation. Later, this map is subtracted from the input abnormal image to convert it into its normal counterpart while preserving all the critical anatomical details. Our method is first to generate fine-grained disease maps to visualize disease lesions in a weekly supervised setting without requiring pixel-level annotations. This development enhances the interpretability of diagnostic AI by providing precise visualizations of disease-specific regions. It also introduces automated binary mask generation to assist radiologists. Empirical evaluations carried out on the benchmark datasets, CheXpert, TBX11K, and COVID-19, demonstrate the capability of TagGAN to outperform current top models in accurately identifying disease-specific pixels. This outcome highlights the capability of the proposed model to tag medical images, significantly reducing the workload for radiologists by eliminating the need for binary masks during training.
Hybrid Interpretable Deep Learning Framework for Skin Cancer Diagnosis: Integrating Radial Basis Function Networks with Explainable AI
Jan 24, 2025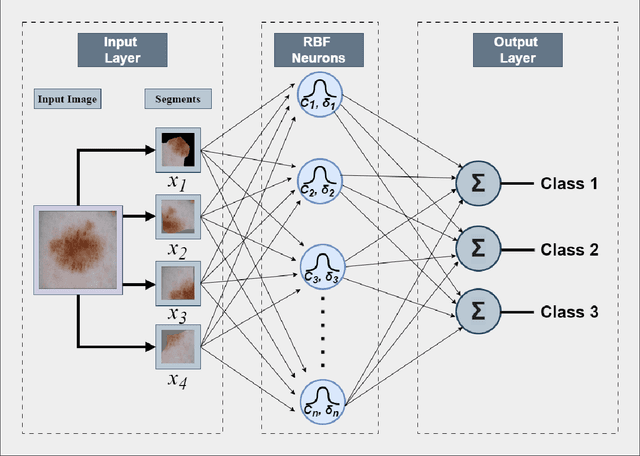


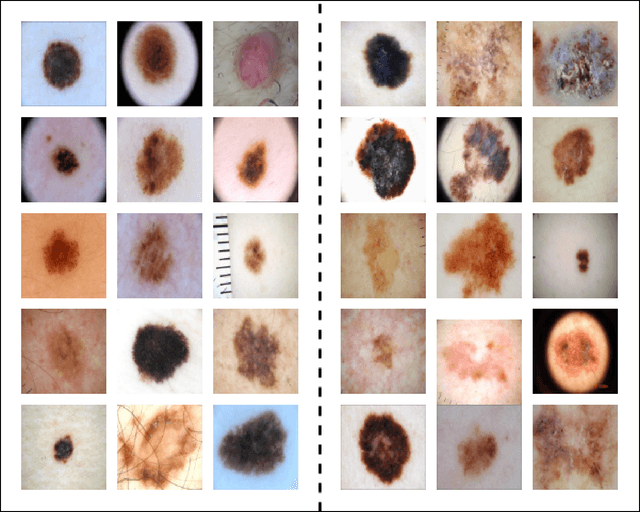
Skin cancer is one of the most prevalent and potentially life-threatening diseases worldwide, necessitating early and accurate diagnosis to improve patient outcomes. Conventional diagnostic methods, reliant on clinical expertise and histopathological analysis, are often time-intensive, subjective, and prone to variability. To address these limitations, we propose a novel hybrid deep learning framework that integrates convolutional neural networks (CNNs) with Radial Basis Function (RBF) Networks to achieve high classification accuracy and enhanced interpretability. The motivation for incorporating RBF Networks lies in their intrinsic interpretability and localized response to input features, which make them well-suited for tasks requiring transparency and fine-grained decision-making. Unlike traditional deep learning models that rely on global feature representations, RBF Networks allow for mapping segments of images to chosen prototypes, exploiting salient features within a single image. This enables clinicians to trace predictions to specific, interpretable patterns. The framework incorporates segmentation-based feature extraction, active learning for prototype selection, and K-Medoids clustering to focus on these salient features. Evaluations on the ISIC 2016 and ISIC 2017 datasets demonstrate the model's effectiveness, achieving classification accuracies of 83.02\% and 72.15\% using ResNet50, respectively, and outperforming VGG16-based configurations. By generating interpretable explanations for predictions, the framework aligns with clinical workflows, bridging the gap between predictive performance and trustworthiness. This study highlights the potential of hybrid models to deliver actionable insights, advancing the development of reliable AI-assisted diagnostic tools for high-stakes medical applications.
Leveraging counterfactual concepts for debugging and improving CNN model performance
Jan 19, 2025



Counterfactual explanation methods have recently received significant attention for explaining CNN-based image classifiers due to their ability to provide easily understandable explanations that align more closely with human reasoning. However, limited attention has been given to utilizing explainability methods to improve model performance. In this paper, we propose to leverage counterfactual concepts aiming to enhance the performance of CNN models in image classification tasks. Our proposed approach utilizes counterfactual reasoning to identify crucial filters used in the decision-making process. Following this, we perform model retraining through the design of a novel methodology and loss functions that encourage the activation of class-relevant important filters and discourage the activation of irrelevant filters for each class. This process effectively minimizes the deviation of activation patterns of local predictions and the global activation patterns of their respective inferred classes. By incorporating counterfactual explanations, we validate unseen model predictions and identify misclassifications. The proposed methodology provides insights into potential weaknesses and biases in the model's learning process, enabling targeted improvements and enhanced performance. Experimental results on publicly available datasets have demonstrated an improvement of 1-2\%, validating the effectiveness of the approach.
Towards Counterfactual and Contrastive Explainability and Transparency of DCNN Image Classifiers
Jan 12, 2025Explainability of deep convolutional neural networks (DCNNs) is an important research topic that tries to uncover the reasons behind a DCNN model's decisions and improve their understanding and reliability in high-risk environments. In this regard, we propose a novel method for generating interpretable counterfactual and contrastive explanations for DCNN models. The proposed method is model intrusive that probes the internal workings of a DCNN instead of altering the input image to generate explanations. Given an input image, we provide contrastive explanations by identifying the most important filters in the DCNN representing features and concepts that separate the model's decision between classifying the image to the original inferred class or some other specified alter class. On the other hand, we provide counterfactual explanations by specifying the minimal changes necessary in such filters so that a contrastive output is obtained. Using these identified filters and concepts, our method can provide contrastive and counterfactual reasons behind a model's decisions and makes the model more transparent. One of the interesting applications of this method is misclassification analysis, where we compare the identified concepts from a particular input image and compare them with class-specific concepts to establish the validity of the model's decisions. The proposed method is compared with state-of-the-art and evaluated on the Caltech-UCSD Birds (CUB) 2011 dataset to show the usefulness of the explanations provided.
Faithful Counterfactual Visual Explanations (FCVE)
Jan 12, 2025



Deep learning models in computer vision have made remarkable progress, but their lack of transparency and interpretability remains a challenge. The development of explainable AI can enhance the understanding and performance of these models. However, existing techniques often struggle to provide convincing explanations that non-experts easily understand, and they cannot accurately identify models' intrinsic decision-making processes. To address these challenges, we propose to develop a counterfactual explanation (CE) model that balances plausibility and faithfulness. This model generates easy-to-understand visual explanations by making minimum changes necessary in images without altering the pixel data. Instead, the proposed method identifies internal concepts and filters learned by models and leverages them to produce plausible counterfactual explanations. The provided explanations reflect the internal decision-making process of the model, thus ensuring faithfulness to the model.
VALD-MD: Visual Attribution via Latent Diffusion for Medical Diagnostics
Jan 02, 2024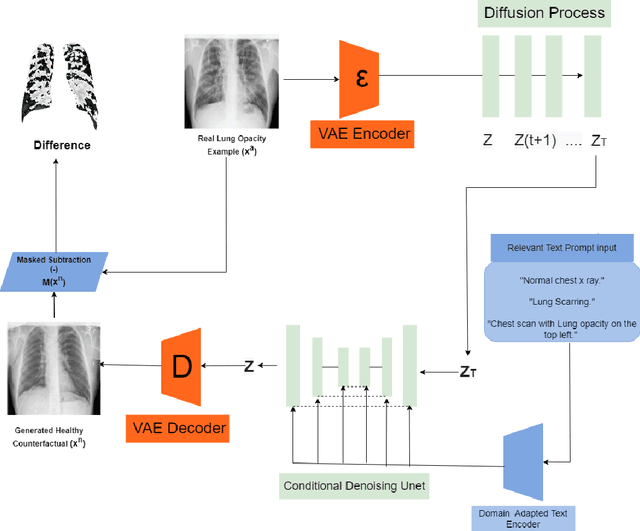

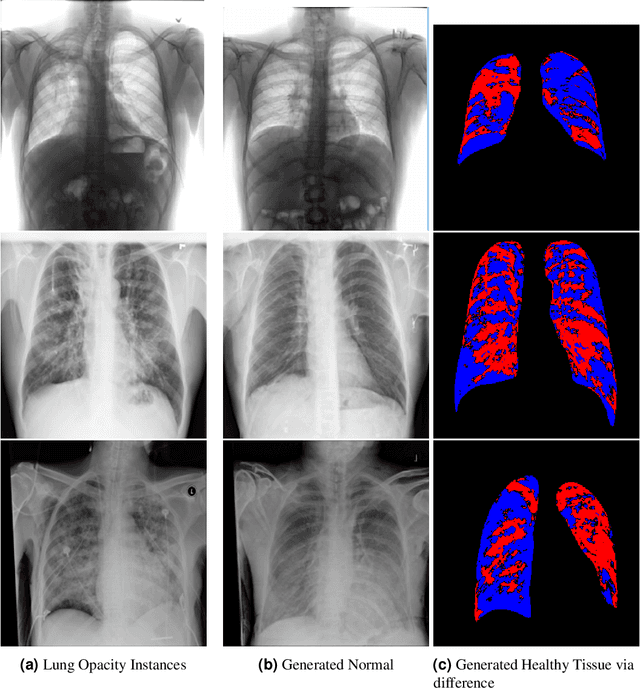

Visual attribution in medical imaging seeks to make evident the diagnostically-relevant components of a medical image, in contrast to the more common detection of diseased tissue deployed in standard machine vision pipelines (which are less straightforwardly interpretable/explainable to clinicians). We here present a novel generative visual attribution technique, one that leverages latent diffusion models in combination with domain-specific large language models, in order to generate normal counterparts of abnormal images. The discrepancy between the two hence gives rise to a mapping indicating the diagnostically-relevant image components. To achieve this, we deploy image priors in conjunction with appropriate conditioning mechanisms in order to control the image generative process, including natural language text prompts acquired from medical science and applied radiology. We perform experiments and quantitatively evaluate our results on the COVID-19 Radiography Database containing labelled chest X-rays with differing pathologies via the Frechet Inception Distance (FID), Structural Similarity (SSIM) and Multi Scale Structural Similarity Metric (MS-SSIM) metrics obtained between real and generated images. The resulting system also exhibits a range of latent capabilities including zero-shot localized disease induction, which are evaluated with real examples from the cheXpert dataset.
Counterfactual Explanation and Instance-Generation using Cycle-Consistent Generative Adversarial Networks
Jan 21, 2023



The image-based diagnosis is now a vital aspect of modern automation assisted diagnosis. To enable models to produce pixel-level diagnosis, pixel-level ground-truth labels are essentially required. However, since it is often not straight forward to obtain the labels in many application domains such as in medical image, classification-based approaches have become the de facto standard to perform the diagnosis. Though they can identify class-salient regions, they may not be useful for diagnosis where capturing all of the evidences is important requirement. Alternatively, a counterfactual explanation (CX) aims at providing explanations using a casual reasoning process of form "If X has not happend, Y would not heppend". Existing CX approaches, however, use classifier to explain features that can change its predictions. Thus, they can only explain class-salient features, rather than entire object of interest. This hence motivates us to propose a novel CX strategy that is not reliant on image classification. This work is inspired from the recent developments in generative adversarial networks (GANs) based image-to-image domain translation, and leverages to translate an abnormal image to counterpart normal image (i.e. counterfactual instance CI) to find discrepancy maps between the two. Since it is generally not possible to obtain abnormal and normal image pairs, we leverage Cycle-Consistency principle (a.k.a CycleGAN) to perform the translation in unsupervised way. We formulate CX in terms of a discrepancy map that, when added from the abnormal image, will make it indistinguishable from the CI. We evaluate our method on three datasets including a synthetic, tuberculosis and BraTS dataset. All these experiments confirm the supremacy of propose method in generating accurate CX and CI.
Text-to-Image Generation with Attention Based Recurrent Neural Networks
Jan 18, 2020
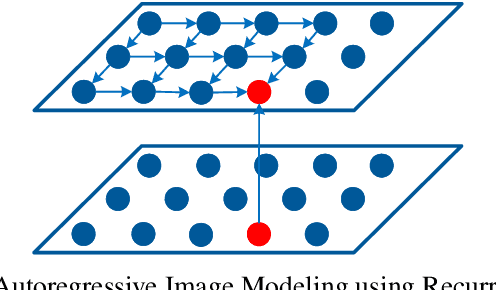
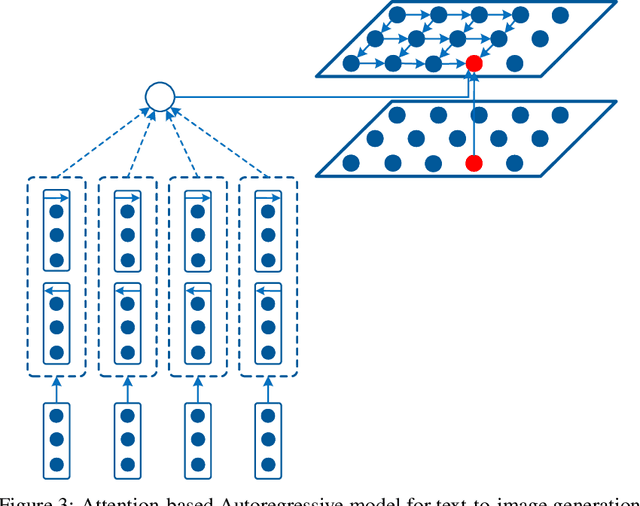

Conditional image modeling based on textual descriptions is a relatively new domain in unsupervised learning. Previous approaches use a latent variable model and generative adversarial networks. While the formers are approximated by using variational auto-encoders and rely on the intractable inference that can hamper their performance, the latter is unstable to train due to Nash equilibrium based objective function. We develop a tractable and stable caption-based image generation model. The model uses an attention-based encoder to learn word-to-pixel dependencies. A conditional autoregressive based decoder is used for learning pixel-to-pixel dependencies and generating images. Experimentations are performed on Microsoft COCO, and MNIST-with-captions datasets and performance is evaluated by using the Structural Similarity Index. Results show that the proposed model performs better than contemporary approaches and generate better quality images. Keywords: Generative image modeling, autoregressive image modeling, caption-based image generation, neural attention, recurrent neural networks.