 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Interpretable Deep Learning Framework for Skin Cancer Diagnosis: Integrating Radial Basis Function Networks with Explainable AI
Jan 24, 2025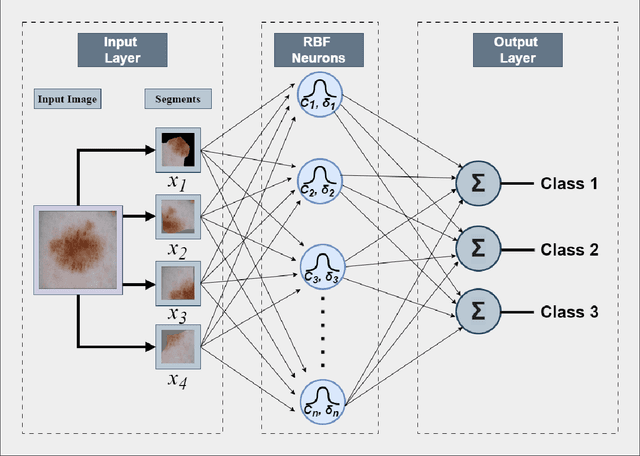


Skin cancer is one of the most prevalent and potentially life-threatening diseases worldwide, necessitating early and accurate diagnosis to improve patient outcomes. Conventional diagnostic methods, reliant on clinical expertise and histopathological analysis, are often time-intensive, subjective, and prone to variability. To address these limitations, we propose a novel hybrid deep learning framework that integrates convolutional neural networks (CNNs) with Radial Basis Function (RBF) Networks to achieve high classification accuracy and enhanced interpretability. The motivation for incorporating RBF Networks lies in their intrinsic interpretability and localized response to input features, which make them well-suited for tasks requiring transparency and fine-grained decision-making. Unlike traditional deep learning models that rely on global feature representations, RBF Networks allow for mapping segments of images to chosen prototypes, exploiting salient features within a single image. This enables clinicians to trace predictions to specific, interpretable patterns. The framework incorporates segmentation-based feature extraction, active learning for prototype selection, and K-Medoids clustering to focus on these salient features. Evaluations on the ISIC 2016 and ISIC 2017 datasets demonstrate the model's effectiveness, achieving classification accuracies of 83.02\% and 72.15\% using ResNet50, respectively, and outperforming VGG16-based configurations. By generating interpretable explanations for predictions, the framework aligns with clinical workflows, bridging the gap between predictive performance and trustworthiness. This study highlights the potential of hybrid models to deliver actionable insights, advancing the development of reliable AI-assisted diagnostic tools for high-stakes medical applications.
Text-to-Image Generation with Attention Based Recurrent Neural Networks
Jan 18, 2020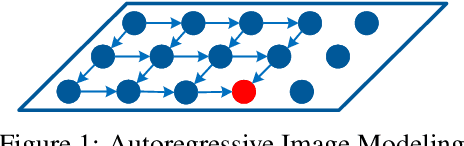
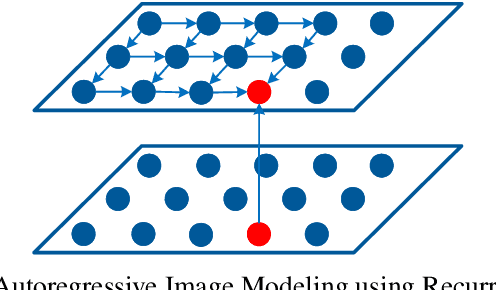
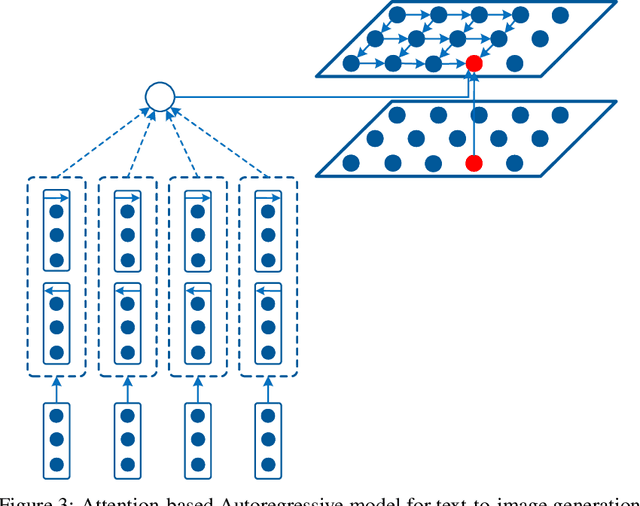

Conditional image modeling based on textual descriptions is a relatively new domain in unsupervised learning. Previous approaches use a latent variable model and generative adversarial networks. While the formers are approximated by using variational auto-encoders and rely on the intractable inference that can hamper their performance, the latter is unstable to train due to Nash equilibrium based objective function. We develop a tractable and stable caption-based image generation model. The model uses an attention-based encoder to learn word-to-pixel dependencies. A conditional autoregressive based decoder is used for learning pixel-to-pixel dependencies and generating images. Experimentations are performed on Microsoft COCO, and MNIST-with-captions datasets and performance is evaluated by using the Structural Similarity Index. Results show that the proposed model performs better than contemporary approaches and generate better quality images. Keywords: Generative image modeling, autoregressive image modeling, caption-based image generation, neural attention, recurrent neural networks.