 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Image Generation with Attention Based Recurrent Neural Networks
Paper and Code
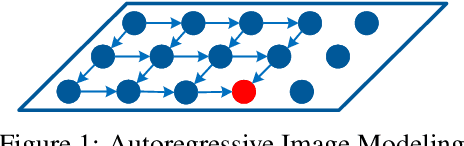
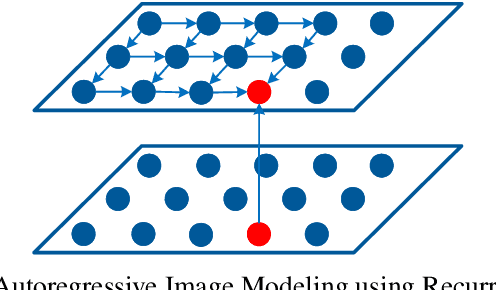
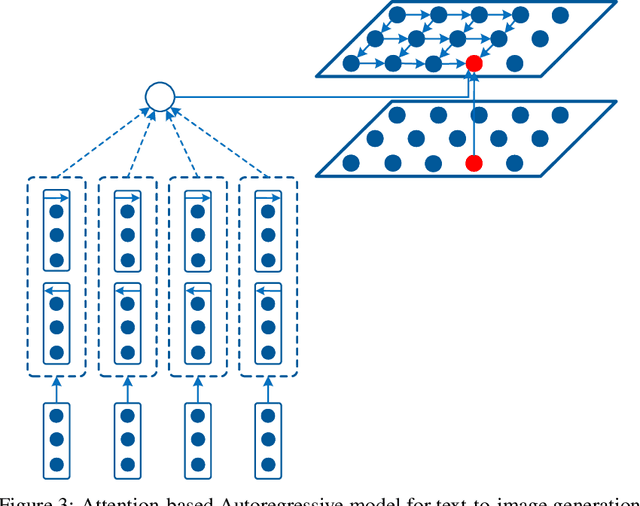

Conditional image modeling based on textual descriptions is a relatively new domain in unsupervised learning. Previous approaches use a latent variable model and generative adversarial networks. While the formers are approximated by using variational auto-encoders and rely on the intractable inference that can hamper their performance, the latter is unstable to train due to Nash equilibrium based objective function. We develop a tractable and stable caption-based image generation model. The model uses an attention-based encoder to learn word-to-pixel dependencies. A conditional autoregressive based decoder is used for learning pixel-to-pixel dependencies and generating images. Experimentations are performed on Microsoft COCO, and MNIST-with-captions datasets and performance is evaluated by using the Structural Similarity Index. Results show that the proposed model performs better than contemporary approaches and generate better quality images. Keywords: Generative image modeling, autoregressive image modeling, caption-based image generation, neural attention, recurrent neural networks.