 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Article Classification with Edge-Heterogeneous Graph Neural Networks
Sep 20, 2023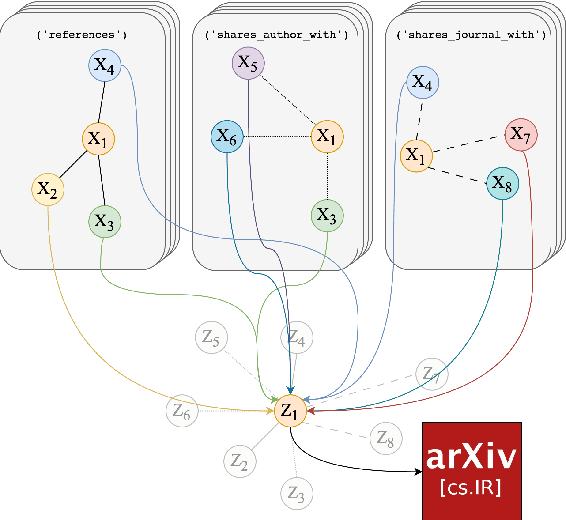
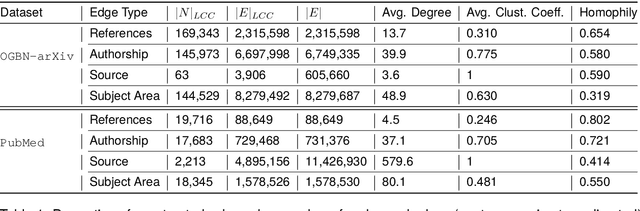
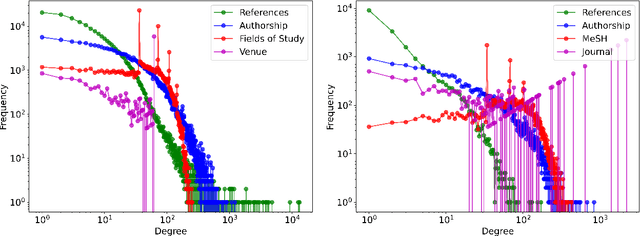
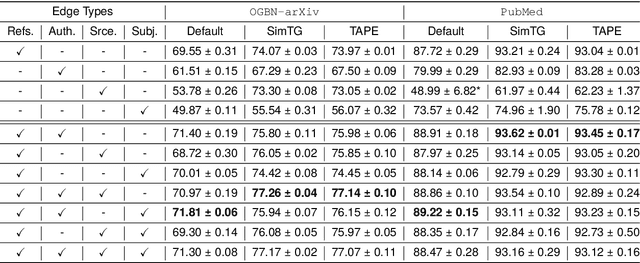
Classifying research output into context-specific label taxonomies is a challenging and relevant downstream task, given the volume of existing and newly published articles. We propose a method to enhance the performance of article classification by enriching simple Graph Neural Networks (GNN) pipelines with edge-heterogeneous graph representations. SciBERT is used for node feature generation to capture higher-order semantics within the articles' textual metadata. Fully supervised transductive node classification experiments are conducted on the Open Graph Benchmark (OGB) ogbn-arxiv dataset and the PubMed diabetes dataset, augmented with additional metadata from Microsoft Academic Graph (MAG) and PubMed Central, respectively. The results demonstrate that edge-heterogeneous graphs consistently improve the performance of all GNN models compared to the edge-homogeneous graphs. The transformed data enable simple and shallow GNN pipelines to achieve results on par with more complex architectures. On ogbn-arxiv, we achieve a top-15 result in the OGB competition with a 2-layer GCN (accuracy 74.61%), being the highest-scoring solution with sub-1 million parameters. On PubMed, we closely trail SOTA GNN architectures using a 2-layer GraphSAGE by including additional co-authorship edges in the graph (accuracy 89.88%). The implementation is available at: $\href{https://github.com/lyvykhang/edgehetero-nodeproppred}{\text{https://github.com/lyvykhang/edgehetero-nodeproppred}}$.
Resolving Gendered Ambiguous Pronouns with BERT
Jun 13, 2019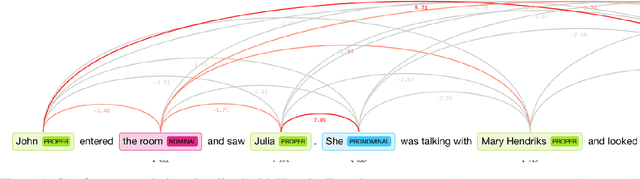
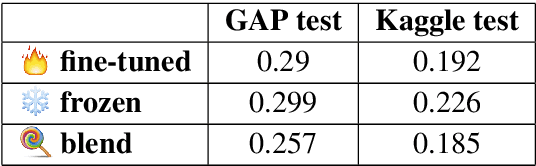


Pronoun resolution is part of coreference resolution, the task of pairing an expression to its referring entity. This is an important task for natural language understanding and a necessary component of machine translation systems, chat bots and assistants. Neural machine learning systems perform far from ideally in this task, reaching as low as 73% F1 scores on modern benchmark datasets. Moreover, they tend to perform better for masculine pronouns than for feminine ones. Thus, the problem is both challenging and important for NLP researchers and practitioners. In this project, we describe our BERT-based approach to solving the problem of gender-balanced pronoun resolution. We are able to reach 92% F1 score and a much lower gender bias on the benchmark dataset shared by Google AI Language team.
Graphlet-based lazy associative graph classification
May 13, 2015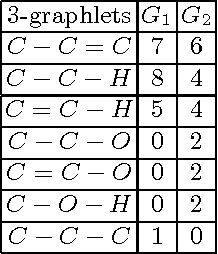
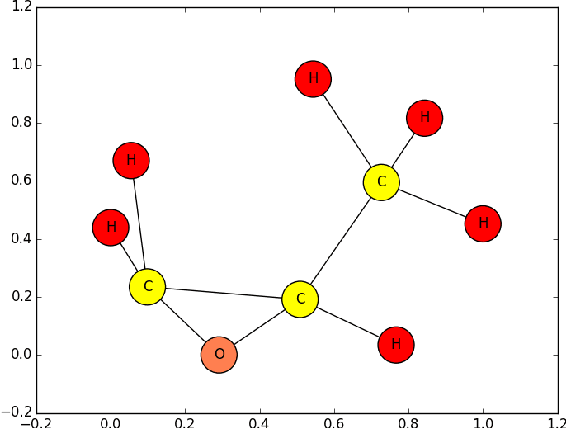
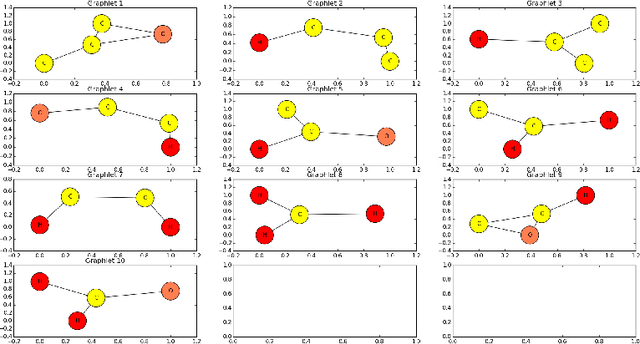
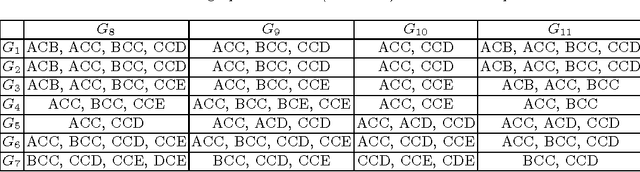
The paper addresses the graph classification problem and introduces a modification of the lazy associative classification method to efficiently handle intersections of graphs. Graph intersections are approximated with all common subgraphs up to a fixed size similarly to what is done with graphlet kernels. We explain the idea of the algorithm with a toy example and describe our experiments with a predictive toxicology dataset.
Can FCA-based Recommender System Suggest a Proper Classifier?
Apr 21, 2015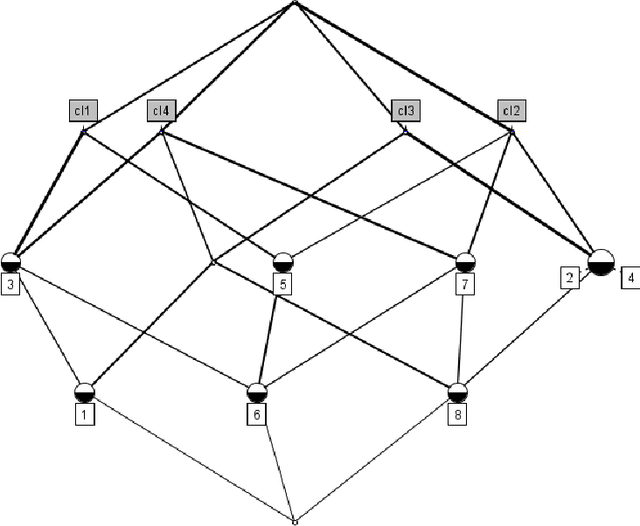
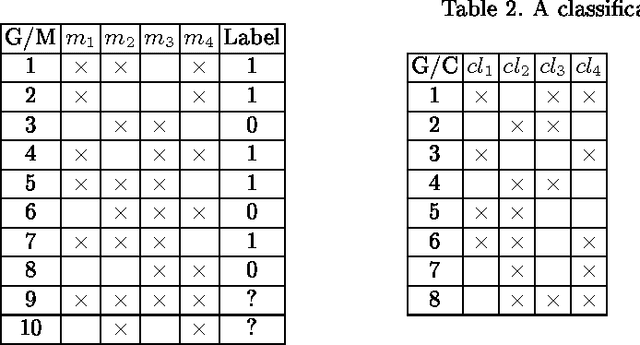
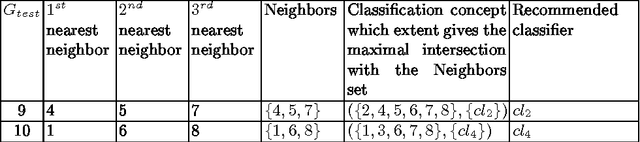
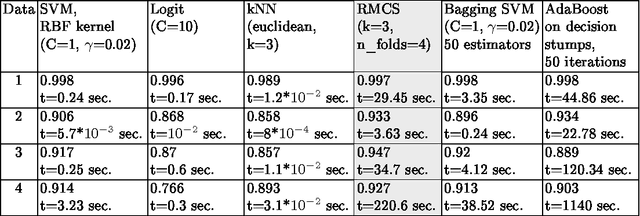
The paper briefly introduces multiple classifier systems and describes a new algorithm, which improves classification accuracy by means of recommendation of a proper algorithm to an object classification. This recommendation is done assuming that a classifier is likely to predict the label of the object correctly if it has correctly classified its neighbors. The process of assigning a classifier to each object is based on Formal Concept Analysis. We explain the idea of the algorithm with a toy example and describe our first experiments with real-world datasets.
* 10 pages, 1 figure, 4 tables, ECAI 2014, workshop "What FCA can do for "Artifficial Intelligence"
Visual analytics in FCA-based clustering
Apr 21, 2015
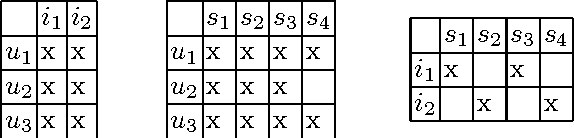
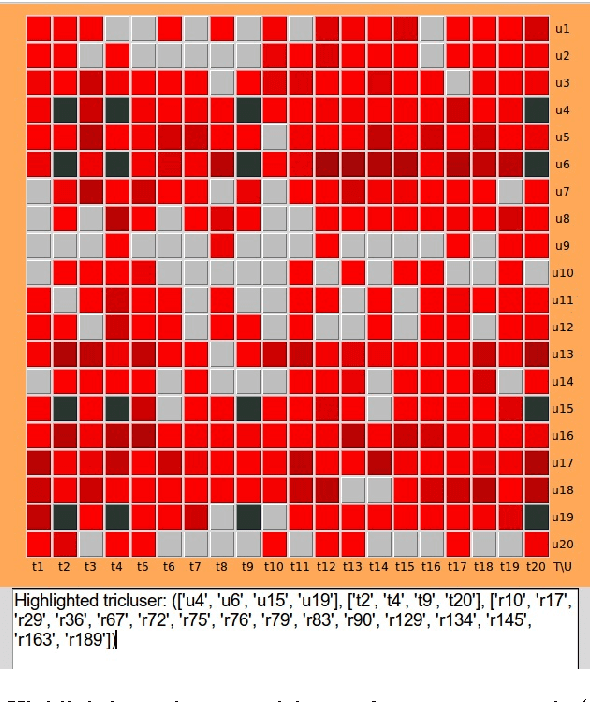
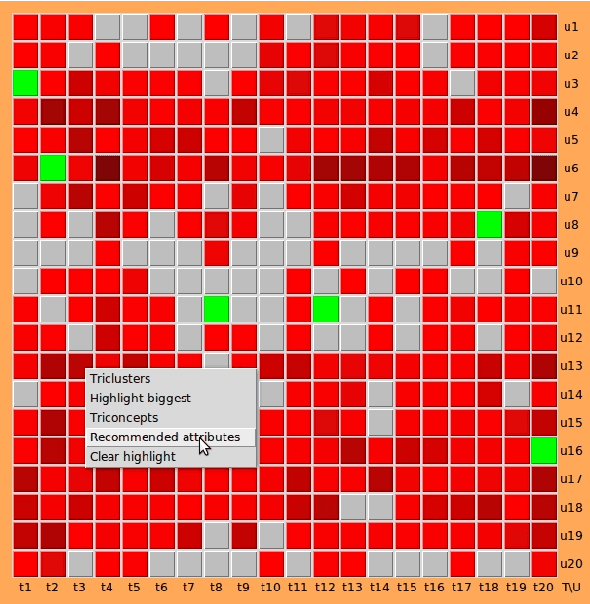
Visual analytics is a subdomain of data analysis which combines both human and machine analytical abilities and is applied mostly in decision-making and data mining tasks. Triclustering, based on Formal Concept Analysis (FCA), was developed to detect groups of objects with similar properties under similar conditions. It is used in Social Network Analysis (SNA) and is a basis for certain types of recommender systems. The problem of triclustering algorithms is that they do not always produce meaningful clusters. This article describes a specific triclustering algorithm and a prototype of a visual analytics platform for working with obtained clusters. This tool is designed as a testing frameworkis and is intended to help an analyst to grasp the results of triclustering and recommender algorithms, and to make decisions on meaningfulness of certain triclusters and recommendations.