 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLink Prediction via Higher-Order Motif Features
Paper and Code
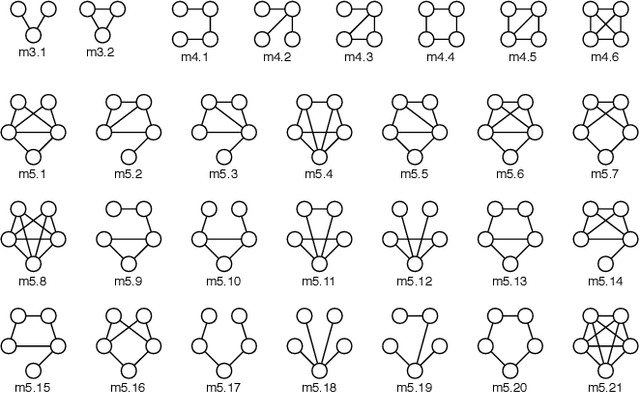
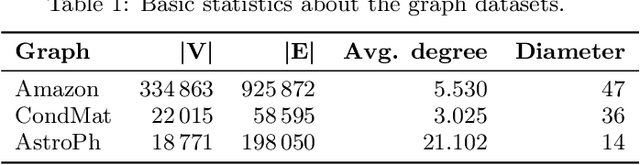
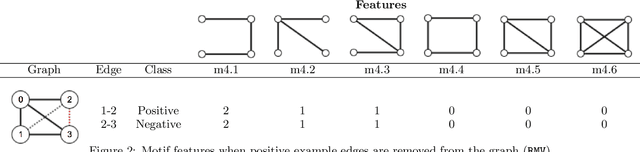

Link prediction requires predicting which new links are likely to appear in a graph. Being able to predict unseen links with good accuracy has important applications in several domains such as social media, security, transportation, and recommendation systems. A common approach is to use features based on the common neighbors of an unconnected pair of nodes to predict whether the pair will form a link in the future. In this paper, we present an approach for link prediction that relies on higher-order analysis of the graph topology, well beyond common neighbors. We treat the link prediction problem as a supervised classification problem, and we propose a set of features that depend on the patterns or motifs that a pair of nodes occurs in. By using motifs of sizes 3, 4, and 5, our approach captures a high level of detail about the graph topology within the neighborhood of the pair of nodes, which leads to a higher classification accuracy. In addition to proposing the use of motif-based features, we also propose two optimizations related to constructing the classification dataset from the graph. First, to ensure that positive and negative examples are treated equally when extracting features, we propose adding the negative examples to the graph as an alternative to the common approach of removing the positive ones. Second, we show that it is important to control for the shortest-path distance when sampling pairs of nodes to form negative examples, since the difficulty of prediction varies with the shortest-path distance. We experimentally demonstrate that using off-the-shelf classifiers with a well constructed classification dataset results in up to 10 percentage points increase in accuracy over prior topology-based and feature learning methods.