 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreNeT: Leveraging Computational Features to Predict Deep Neural Network Training Time
Dec 20, 2024Training deep learning models, particularly Transformer-based architectures such as Large Language Models (LLMs), demands substantial computational resources and extended training periods. While optimal configuration and infrastructure selection can significantly reduce associated costs, this optimization requires preliminary analysis tools. This paper introduces PreNeT, a novel predictive framework designed to address this optimization challenge. PreNeT facilitates training optimization by integrating comprehensive computational metrics, including layer-specific parameters, arithmetic operations and memory utilization. A key feature of PreNeT is its capacity to accurately predict training duration on previously unexamined hardware infrastructures, including novel accelerator architectures. This framework employs a sophisticated approach to capture and analyze the distinct characteristics of various neural network layers, thereby enhancing existing prediction methodologies. Through proactive implementation of PreNeT, researchers and practitioners can determine optimal configurations, parameter settings, and hardware specifications to maximize cost-efficiency and minimize training duration. Experimental results demonstrate that PreNeT achieves up to 72% improvement in prediction accuracy compared to contemporary state-of-the-art frameworks.
A Learning-Based Caching Mechanism for Edge Content Delivery
Feb 05, 2024



With the advent of 5G networks and the rise of the Internet of Things (IoT), Content Delivery Networks (CDNs) are increasingly extending into the network edge. This shift introduces unique challenges, particularly due to the limited cache storage and the diverse request patterns at the edge. These edge environments can host traffic classes characterized by varied object-size distributions and object-access patterns. Such complexity makes it difficult for traditional caching strategies, which often rely on metrics like request frequency or time intervals, to be effective. Despite these complexities, the optimization of edge caching is crucial. Improved byte hit rates at the edge not only alleviate the load on the network backbone but also minimize operational costs and expedite content delivery to end-users. In this paper, we introduce HR-Cache, a comprehensive learning-based caching framework grounded in the principles of Hazard Rate (HR) ordering, a rule originally formulated to compute an upper bound on cache performance. HR-Cache leverages this rule to guide future object eviction decisions. It employs a lightweight machine learning model to learn from caching decisions made based on HR ordering, subsequently predicting the "cache-friendliness" of incoming requests. Objects deemed "cache-averse" are placed into cache as priority candidates for eviction. Through extensive experimentation, we demonstrate that HR-Cache not only consistently enhances byte hit rates compared to existing state-of-the-art methods but also achieves this with minimal prediction overhead. Our experimental results, using three real-world traces and one synthetic trace, indicate that HR-Cache consistently achieves 2.2-14.6% greater WAN traffic savings than LRU. It outperforms not only heuristic caching strategies but also the state-of-the-art learning-based algorithm.
Performance Modeling of Metric-Based Serverless Computing Platforms
Feb 23, 2022



Analytical performance models are very effective in ensuring the quality of service and cost of service deployment remain desirable under different conditions and workloads. While various analytical performance models have been proposed for previous paradigms in cloud computing, serverless computing lacks such models that can provide developers with performance guarantees. Besides, most serverless computing platforms still require developers' input to specify the configuration for their deployment that could affect both the performance and cost of their deployment, without providing them with any direct and immediate feedback. In previous studies, we built such performance models for steady-state and transient analysis of scale-per-request serverless computing platforms (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) that could give developers immediate feedback about the quality of service and cost of their deployments. In this work, we aim to develop analytical performance models for the latest trend in serverless computing platforms that use concurrency value and the rate of requests per second for autoscaling decisions. Examples of such serverless computing platforms are Knative and Google Cloud Run (a managed Knative service by Google). The proposed performance model can help developers and providers predict the performance and cost of deployments with different configurations which could help them tune the configuration toward the best outcome. We validate the applicability and accuracy of the proposed performance model by extensive real-world experimentation on Knative and show that our performance model is able to accurately predict the steady-state characteristics of a given workload with minimal amount of data collection.
MLProxy: SLA-Aware Reverse Proxy for Machine Learning Inference Serving on Serverless Computing Platforms
Feb 23, 2022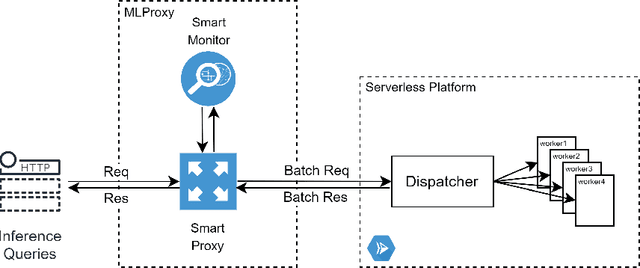
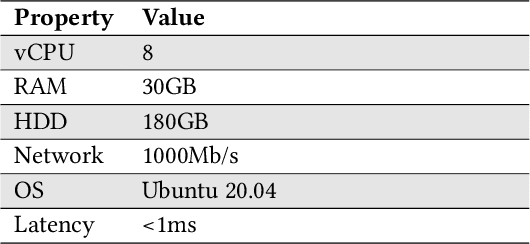
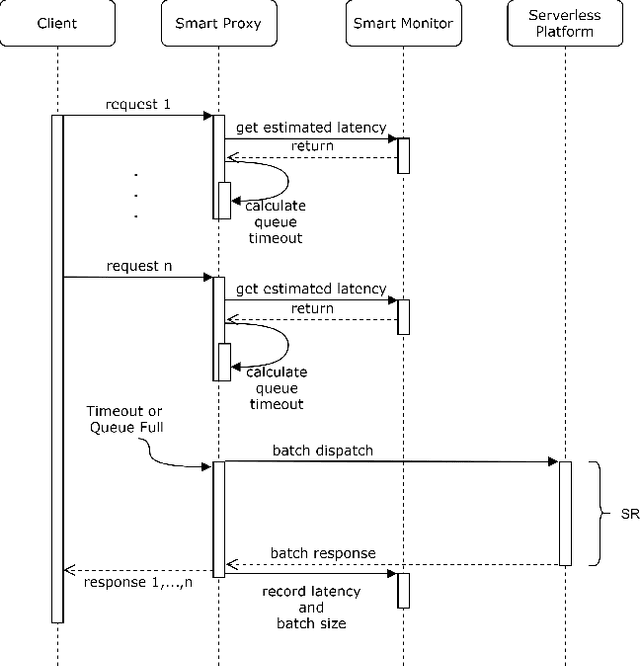

Serving machine learning inference workloads on the cloud is still a challenging task on the production level. Optimal configuration of the inference workload to meet SLA requirements while optimizing the infrastructure costs is highly complicated due to the complex interaction between batch configuration, resource configurations, and variable arrival process. Serverless computing has emerged in recent years to automate most infrastructure management tasks. Workload batching has revealed the potential to improve the response time and cost-effectiveness of machine learning serving workloads. However, it has not yet been supported out of the box by serverless computing platforms. Our experiments have shown that for various machine learning workloads, batching can hugely improve the system's efficiency by reducing the processing overhead per request. In this work, we present MLProxy, an adaptive reverse proxy to support efficient machine learning serving workloads on serverless computing systems. MLProxy supports adaptive batching to ensure SLA compliance while optimizing serverless costs. We performed rigorous experiments on Knative to demonstrate the effectiveness of MLProxy. We showed that MLProxy could reduce the cost of serverless deployment by up to 92% while reducing SLA violations by up to 99% that can be generalized across state-of-the-art model serving frameworks.
Privacy-preserving Data Analysis through Representation Learning and Transformation
Nov 16, 2020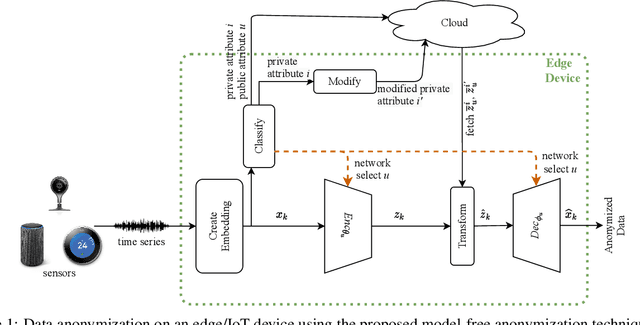

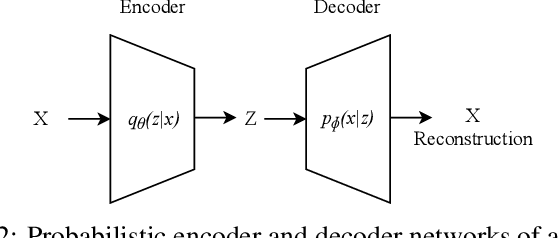

The abundance of data from the sensors embedded in mobile and Internet of Things (IoT) devices and the remarkable success of deep neural networks in uncovering hidden patterns in time series data have led to mounting privacy concerns in recent years. In this paper, we aim to navigate the trade-off between data utility and privacy by learning low-dimensional representations that are useful for data anonymization. We propose probabilistic transformations in the latent space of a variational autoencoder to synthesize time series data such that intrusive inferences are prevented while desired inferences can still be made with a satisfactory level of accuracy. We compare our technique with state-of-the-art autoencoder-based anonymization techniques and additionally show that it can anonymize data in real time on resource-constrained edge devices.